编辑|云昭
出品 | 51CTO技术栈(微信号:blog51cto)
AI 的“聪明”有时令人惊叹,有时又让人困惑。它能写论文、算数、作诗,却也会在最简单的逻辑题上犯错。
更可怕的是——它自己并不知道哪一步错了。不过现在,要有解了!
最近,Meta FAIR(Fundamental AI Research)团队和爱丁堡大学的研究者提出了一种新方法,让大模型学会“自查”并“纠错”自己的推理过程。
 图片
图片
他们称之为 Circuit-based Reasoning Verification(CRV)——基于电路的推理验证。这项研究登上 arXiv 后,迅速引起了全球 AI 研究圈的热议。
先用一句话总结看完它的感受:
大模型要别“思维黑箱”时代了,Meta提出的新方法太牛了!,它可以让推理错误变得可见、可诊断、可修复。
1.AI 推理为什么不可靠?
现在的 LLM常用“思维链”来模拟人类推理。
它会边思考边解释,比如:“首先我要先计算这个,再乘以那个,最后得出答案是……”。
看上去逻辑清晰,但 Meta 的研究指出:
模型生成的“思维链”文字,并不等于它内部真实的推理过程。
有时候,模型输出的推理是“编出来的”——看似合理,但内部计算其实早就偏离了正确轨迹。
于是,AI 可能在中途“自信地胡说”,而我们毫无察觉。
过去的验证方式主要分两类:
- 黑箱方法:只看最终结果或输出置信度;
- 灰箱方法:用探针观察神经激活状态,尝试推测模型脑子里在想什么。(Anthropic今年一篇博客中揭露了该做法。)
问题在于,这些方法只能发现“哪里不对”,却解释不了“为什么错”。就像医生知道病人发烧,却找不到病因。
2.CRV:第一次“打开”AI 的推理电路
Meta 的思路更接近于“开盖检查引擎”。
他们认为,模型在解决任务时,会激活一套套内部“电路”——相当于潜在算法。推理出错,其实就是某个“算法模块”执行不对。
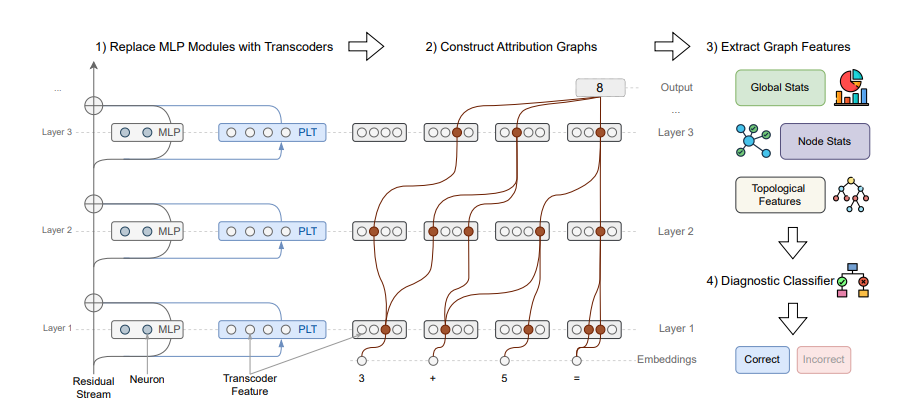
于是,CRV 直接介入模型内部,用一种叫 “转码器(Transcoder)” 的结构替换原有层,让模型的中间计算变得稀疏且可解释。
这相当于在大脑里装上“透明窗口”,能看到每一步是哪个电路在发光。
 图片
图片
然后,研究者继续做了以下步骤:
- 构建模型每步推理的“归因图”(Attribution Graph),记录信息流动路径;
- 从中提取“结构指纹”特征;
- 训练一个诊断模型,实时判断当前推理是否正确。
 图片
图片
拓扑图对比:红-错误 蓝-正确
在推理时,CRV 就像一个“随行监控器”,能即时发出预警:
“嘿,这一步的逻辑结构和以往正确推理的模式不一样,可能要出错了。”
3.最惊人的部分:它能“修”
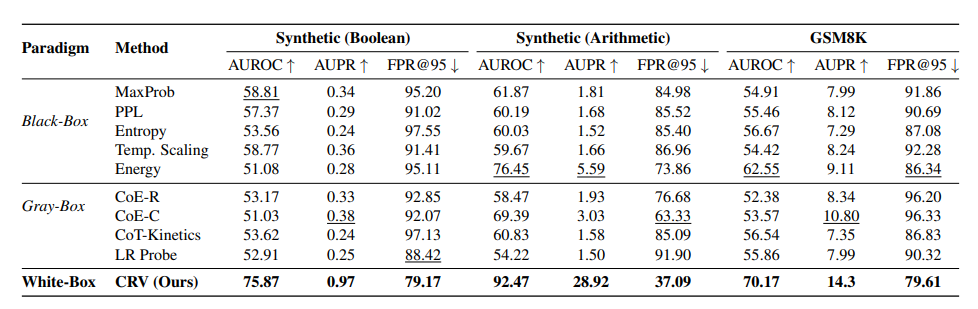
实验对象是改造后的 Llama 3.1 8B Instruct。研究者用逻辑、算术和 GSM8K 数学题测试后发现:
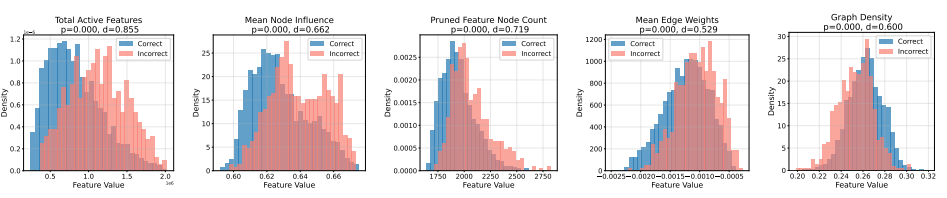
- CRV 在所有数据集上都优于传统黑箱与灰箱方法;
- 不同任务的错误有明显“领域特征”——逻辑与算术错误在计算图上表现完全不同;
- 更关键的是:错误特征具有因果性。
 图片
图片
在一个案例中,模型因“运算顺序”出错。
CRV 发现问题出在“乘法”模块提前激活——研究者手动抑制了该特征,模型立刻修正,解题成功。
这意味着:模型的推理错误不只是能被检测,还能被定位并即时修复。
 图片
图片
这在 AI 研究中是一个质的飞跃。
以往我们只能说“AI 犯错了”;现在,我们可以问:“它具体是哪个‘电路’出了问题?”
4.AI 调试:从不可解释到可维护
CRV 的意义远不止是修数学题。它开启了一个更重要的方向——可调试的 AI(Debuggable AI)。
传统软件出错时,开发者可以看执行日志、查堆栈、追踪变量。
而大模型的计算过去是“雾状”的:你只能看到输入和输出,中间的逻辑完全黑箱。
CRV 的“归因图”提供了类似“执行追踪”的能力,让开发者看到一个输出是如何逐步从中间特征生成的。
这或许会成为未来AI 调试器的雏形。
想象一下,如果企业级模型在财务分析或医疗诊断中推理错误,开发者不需要重训上百亿参数,只需针对问题电路进行局部修补。
这种能力,将大大降低 AI 开发与部署的风险。
5.未来:AI 的“理性自愈”
Meta 的这项研究目前仍是原型,但方向已经很清晰:
未来的 AI,不只是能学习,更要能理解并修正自己的错误。
团队计划公开数据集与转码器模型,推动整个领域朝“可解释、可控、可调试”的 AI 演进。
AI 从此可能进入一个全新阶段——不是追求更大的参数,而是追求更强的“理性自治”。
过去我们常说:AI 是个黑箱。现在,Meta 正在告诉我们:
“黑箱”不是宿命,推理也可以像电路那样被看见、被修复。
这也许正是下一代 AI 的分水岭:从模仿思考,到真正“懂得思考”。


