大型扩散模型(如 Stable Diffusion)让我们能够从文字生成高保真的图像。但当用户希望「生成我和我的朋友们在不同场景中的照片」时,现有的个性化生成方法(如 DreamBooth、IP-Adapter)仍面临两个根本问题:
- 缺乏交互性:无法自由控制人物的空间位置、大小与关系。
- 难以扩展到多主体:每多一个人,内存和算力就线性增长。
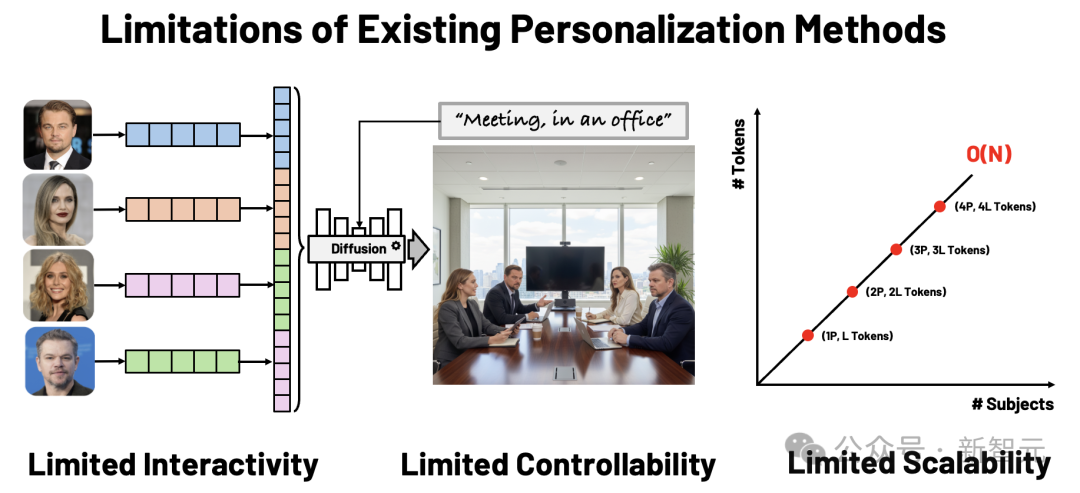
LayerComposer的目标,就是要打破这两大限制,让用户可以直观地控制在哪里放置什么样的元素,进行可控且高效的个性化生成。

项目地址:https://snap-research.github.io/layercomposer/
论文地址:https://arxiv.org/abs/2510.20820

「一张由雪人和三位女孩组成的合照」—— 你可以像在Photoshop里一样,放置、缩放、锁定角色,然后让模型完成剩下的工作。
LayerComposer的三大设计
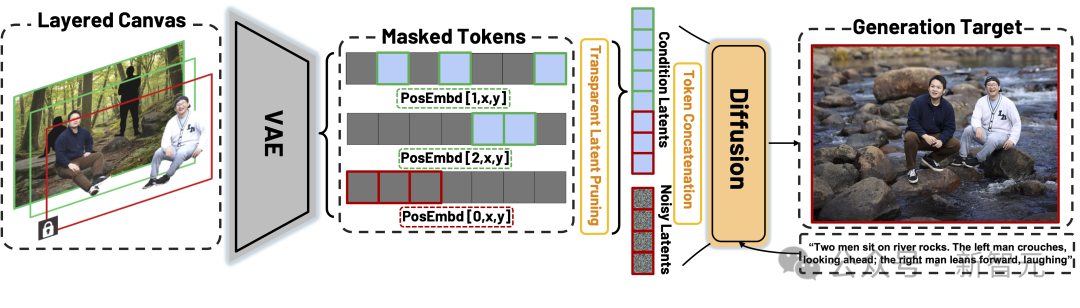
分层画布(Layered Canvas)
每个人物、物体或背景都放在独立的RGBA层 中(包含透明通道的图片),这样可以:
- 避免人物遮挡导致的信息丢失;
- 通过透明裁剪(Transparent Latent Pruning)显著降低计算量;
- 支持任意数量的主体组合。
类似于在Photoshop里,每一层就是一个独立的角色,随意移动、缩放或删除。
锁定机制(Locking Mechanism)
每一层都可以选择「锁定(Lock)」或「解锁(Unlock)」:
- 锁定层 → 模型必须高保真地保留该层,仅允许细微的光照调整;
- 解锁层 → 模型可以根据文字描述自由生成姿态、表情或交互。
你可以锁定背景,让人物随提示变化,也可以锁定一个角色姿势,生成其他人围绕他互动。
这种「可选保真度」让 LayerComposer 比以往方法更接近人类的创作流程。
模型–数据共设计(Model–Data Co-Design)

LayerComposer的锁定机制无需修改网络结构。
研究人员通过「位置嵌入」(positional embedding) 与「数据采样策略」共同实现:
- 锁定层共享相同的空间编码;
- 解锁层使用独立的编码,以避免重叠混淆。
这种轻量化设计,可以在现有扩散模型(如 FLUX Kontext)上直接适配。
实验结果
多主体、高保真、强可控
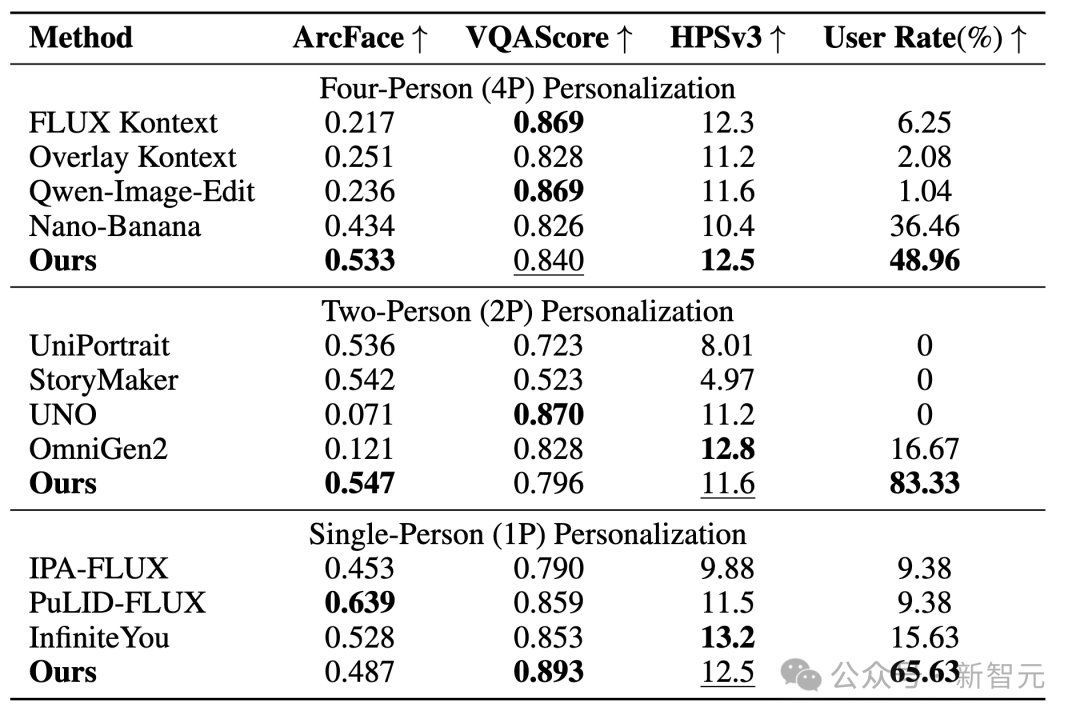
四人场景(4P)

在四人同框的任务中,LayerComposer的生成质量显著优于 FLUX Kontext、Qwen-Image-Edit、Gemini 2.5 Flash Image等模型,能在存在遮挡的情况下保持人物结构完整,并忠实地还原每个人物。
双人交互(2P)

在需要两人互动的场景(如「一起吃饭」、「握手」)中,LayerComposer能生成自然的姿态与空间关系,不再出现「复制粘贴」或「少人」的问题,用户偏好达到83.3%,远超OmniGen2等最新模型。
单人个性化(1P)

即使只生成单人肖像,LayerComposer仍展示出优越的表现:
在保持身份一致的同时,能灵活生成不同表情与动作(如笑、闭眼、吃饭等),避免「贴脸」效果。
消融实验
锁定与分层的作用

锁定机制(Locking Mechanism)
为了展示锁定机制的效果,研究人员逐步对每一层输入进行锁定。
被锁定的层会保留该人物的姿态——模型只会在此基础上进行「外延绘制」(outpainting)和轻微的细节光照调整。
需要强调的是,这与「掩膜推理(masked inference)」不同:在掩膜推理中,被遮挡的区域完全不会被更新。
另外,在实验设置中,未锁定的层会根据已锁定的内容和整体场景上下文灵活调整,从而实现自然的协调与融合。
分层画布(Layered Canvas)
如果不使用分层画布,模型就只能在训练中以单张拼贴图像(collage)作为条件输入,如图中 「Inputs」 一列所示。
可以看到,在「w/o layered canvas」(无分层画布)的结果中,由于拼贴重叠造成的遮挡,会导致信息缺失。
例如,左边女子圣诞帽上的球被遮挡后在生成结果中完全消失。
相比之下,提出的分层画布能够显式地处理遮挡问题,从而避免此类伪影(artifacts)和细节丢失。

通过在Layered Cavas中调整每一个subject在各自layer的位置,LayerComposer支持直观的空间布局调控。
总结
LayerComposer让多主体个性化生成从「被动输入」迈向「主动创作」。
用户不再只是输入文本,而是真正参与到构图过程中。
从DreamBooth到LayerComposer,个性化生成,终于有了交互的灵魂。
未来展望
尽管LayerComposer带来了交互式个性化的新范式,但仍存在一些挑战。
在需要「复杂物理推理」(如「坐在输入图片椅子上」)的场景中可能失败。
未来,研究人员计划让LayerComposer支持更强的理解能力和更多模态,以促进人机协同创作:
- 结合大语言与视觉模型(VLMs) 的理解能力,实现语义级别的自动布局与构图建议;
- 支持视频级别的分层个性化,让交互式创作从静态图像走向动态场景;
- 探索生成与编辑的统一界面,让用户在同一画布上无缝地修改、添加与再生成内容。
这种以「分层画布」为核心的交互式个性化范式,将成为下一代生成式创作工具的重要方向。


