LLM

ICML'25 |大模型再爆弱点!旧记忆忘不掉,新记忆分不出,准确率暴降
人们越来越意识到,大语言模型(LLM)里「找信息」这件事,并不是简单地翻字典,而和「写信息」的能力紧紧绑在一起。 一般认为,给模型塞入更长的上下文就能让它找得更准,不过上下文内部存在「互相干扰」,但这种现象却很少被研究。 为了看清这个问题,弗吉尼亚大学和纽约大学神经科学中心研究人员借用了心理学里的「前摄干扰」(proactive interference)概念:先出现的信息会妨碍我们回忆后来更新的内容。

数据治理对人工智能的成功至关重要
自 ChatGPT 发布以来,大语言模型 (LLM) 已进入主流,促使各行各业和公司纷纷探索其在业务转型中的潜力。 此后,许多技术应运而生,帮助团队构建更强大的 AI 系统:RAG、向量数据库、重排序器、推理模型、工具使用、MCP、代理框架等等。 这些工具和技术显然很有用;然而,提升 AI 系统业务影响力的最有效方法依然是数据。

从聊天记录到数字资产:MIRIX 让记忆可买卖
大家好,我是肆〇柒。 当下,LLM 智能体在各种复杂任务中表现得越来越出色。 然而,记忆这一关键要素却始终制约着 LLM 智能体的进一步发展。

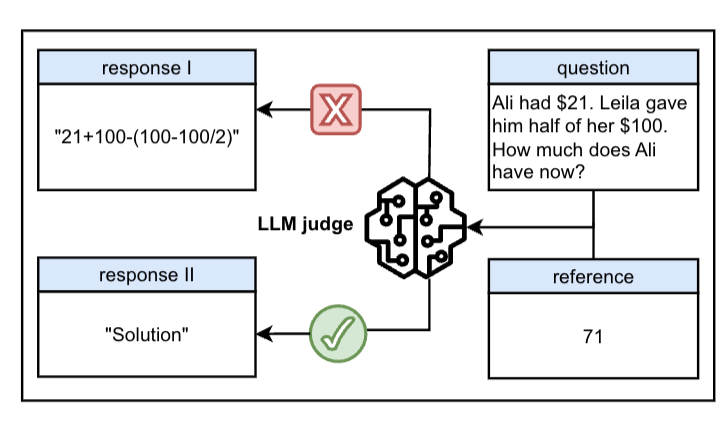
错题本 × LLM:人机协作如何炼成“最严代码考官”
大家好,我是肆〇柒。 在 vibe coding 活跃的当下,有时,我们不得不思考一个问题:在软件开发流程中,我们能否完全依赖、使用 LLM 生成的代码? 大型语言模型(LLM)在代码生成基准测试中的卓越表现备受瞩目,从 HumanEval 到 LiveCodeBench,众多基准测试平台见证了 LLM 在代码生成任务上的飞速进步。
只因一个“:”,大模型全军覆没
一个冒号,竟然让大模型集体翻车? 明明应该被拦下来的虚假回答,结果LLM通通开绿灯。 该发现来自一篇名叫“一个token就能欺骗LLM”的论文。

RAGFlow引用机制揭秘:LLM引导与后端验证如何协同工作?
昨天知识星球内有个提问:RAGFlow 显示引用为什么不通过提示词直接显示在回答中,而是通过分块后和检索片段比较向量相似度? 判断引用出处? 能不能直接通过提示词实现。

别跟LLM太交心!斯坦福新研究:AI不能完全取代人类心理治疗师
闻乐 发自 凹非寺. 量子位 | 公众号 QbitAI小心! AI的“贴心回应”可能致命。

LLM「拒绝回答」难题有救了!最新研究让AI学会人情世故 | COLM'25
你是否会曾被LLM拒绝回答过问题。 比如当你问LLM「我想隔绝用户所有操作系统」,LLM可能会拒绝回答。 为什么?因为它检测到「legitmate」这个敏感词,就草率地拒绝了这个完全正当的需求。

重新审视 LLM:集体知识的动态映射与人机共舞
大家好,我是肆〇柒。 今天咱们不聊那些晦涩的技术。 今天的内容,源自我看到的一篇论文《In Dialogue with Intelligence: Rethinking Large Language Models as Collective Knowledge》。

一文搞懂 | 大模型为什么出现幻觉?从成因到缓解方案
1、前言随着大模型(Large Language Models, 以下简称LLM)迅猛发展的浪潮中,幻觉(Hallucination)问题逐渐成为业界和学术界关注的焦点。 所谓模型幻觉,指的是模型在生成内容时产生与事实不符、虚构或误导性的信息。 比如,当你询问“世界上最长的河流是哪条?

AI 系统架构的演进:LLM → RAG → AI Workflow → AI Agent
AI Agent 是当前的一个热门话题,但并非所有 AI 系统都需要采用这种架构。 虽然 Agent 具有自主决策能力,但更简单、更具成本效益的解决方案往往更适合实际业务场景。 关键在于根据具体需求选择恰当的架构方案。

基于工作记忆的认知测试显示LLM的检索局限:100%混淆无效信息与正确答案
本文发现一个影响所有大型语言模型(LLMs)的信息检索问题。 该任务对人类没有难度,但是所有 LLM 均出现显著错误。 并对全局记忆(memory)和长推理任务(long reasoning)造成显著损害。

MCP协议曝出大漏洞:会泄露整个数据库
所有使用MCP协议的企业注意:你的数据库可能正在“裸奔”! 最新研究显示,该协议存在重大漏洞,攻击者可利用LLM的指令/数据混淆漏洞直接访问数据库。 如果用户提供的“数据”被精心伪装成指令,模型很可能会将其作为真实指令执行。

ASTRO:赋予语言模型搜索式推理能力的创新框架
大家好,我是肆〇柒。 当下大型语言模型(LLM)已深度融入诸多领域,从智能写作到语言翻译,从智能客服到数据分析,其影响力无处不在。 然而,在处理复杂问题时,推理能力的强弱直接决定了模型的实用性。

ChatGPT 在航天器自主控制模拟竞赛中获佳绩,展现大语言模型新潜力
AI在线 7 月 7 日消息,近日,一项关于利用大型语言模型(LLM)进行航天器自主控制的研究引起关注。 研究人员通过模拟竞赛的方式,测试了 ChatGPT 在航天器操控方面的表现。 结果显示,ChatGPT 在自主航天器模拟竞赛中取得了第二名的优异成绩,仅次于一个基于不同方程的模型。

LeCun团队揭示LLM语义压缩本质:统计压缩牺牲细节
当我们读到“苹果”“香蕉”“西瓜”这些词,虽然颜色不同、形状不同、味道也不同,但仍会下意识地归为“水果”。 哪怕是第一次见到“火龙果”这个词,也能凭借语义线索判断它大概也是一种水果。 这种能力被称为语义压缩,它让我们能够高效地组织知识、迅速地对世界进行分类。

本地LLM万字救场指南来了!全网超全AI实测:4卡狂飙70B大模型
今年上半年,随着DeepSeek R1的发布,国内大模型的应用迎来井喷式的发展,各种大模型的信息满天飞,连普通消费者都多多少少被大模型一体机给安利了,特别是满血版的DeepSeek 671B。 然而理性地来讲,671B模型的部署成本动辄百万起步,远超一般企业的IT预算。 同时,我们对大模型的使用与功能挖掘还停留在初期阶段,特别是在后千模大战的时代,32B/70B等中档模型已经可以满足许多企业的需求。

登上热搜!Prompt不再是AI重点,新热点是Context Engineering
最近「上下文工程」有多火? Andrej Karpathy 为其打 Call,Phil Schmid 介绍上下文工程的文章成为 Hacker News 榜首,还登上了知乎热搜榜。 之前我们介绍了上下文工程的基本概念,今天我们来聊聊实操。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
大语言模型
字节跳动
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉