
昨天知识星球内有个提问:
RAGFlow 显示引用为什么不通过提示词直接显示在回答中,而是通过分块后和检索片段比较向量相似度?判断引用出处?能不能直接通过提示词实现。
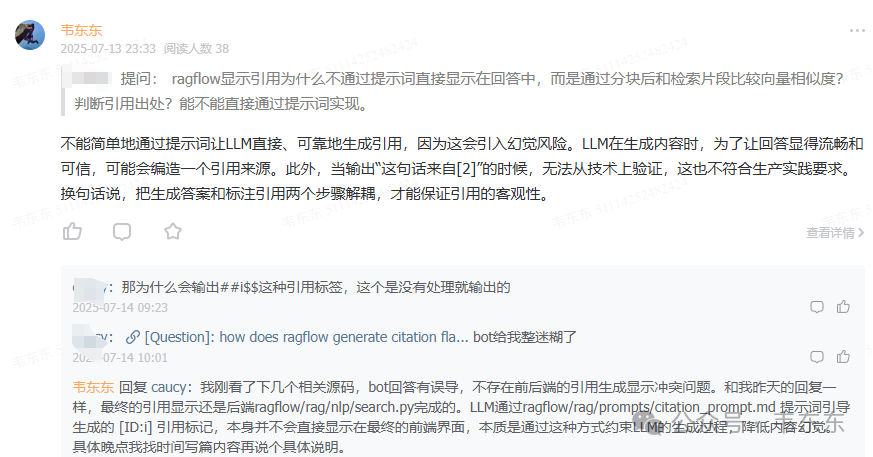
我当时给的回答是:
不能简单地通过提示词让 LLM 直接、可靠地生成引用,因为这会引入幻觉风险。LLM 在生成内容时,为了让回答显得流畅和可信,可能会编造一个引用来源。此外,当输出“这句话来自[2]”的时候,无法从技术上验证,这也不符合生产实践要求。换句话说,把生成答案和标注引用两个步骤解耦,才能保证引用的客观性。
本来这个对话就结束了,今天这个星友追评了下在 RAGFlow 的 Github 提了一个相关问题的 issue,结果 bot 的回答让他有些困惑。我之前也没有仔细了解过 RAGFlow 的相关源码设计,就这这个问题实际看了下之后,觉得值得拿出来专门写篇文章来做个拆解。
这篇试图说清楚,为啥 RAGFlow 的最终回答中的引用显示是后端完成的,LLM 通过提示词引导生成的 [ID:i] 引用标记具体是什么作用,以及这种设计可以参考的工程化经验。
以下,enjoy:
1、Issue 中的 BOT 误导
这个 Issue 的核心问题是:“RAGFlow 是如何生成引用标记的?”bot 的回答显得摇摆不定:起初它断言引用完全由后端生成,LLM 本身并不参与;https://github.com/infiniflow/ragflow/issues/8817
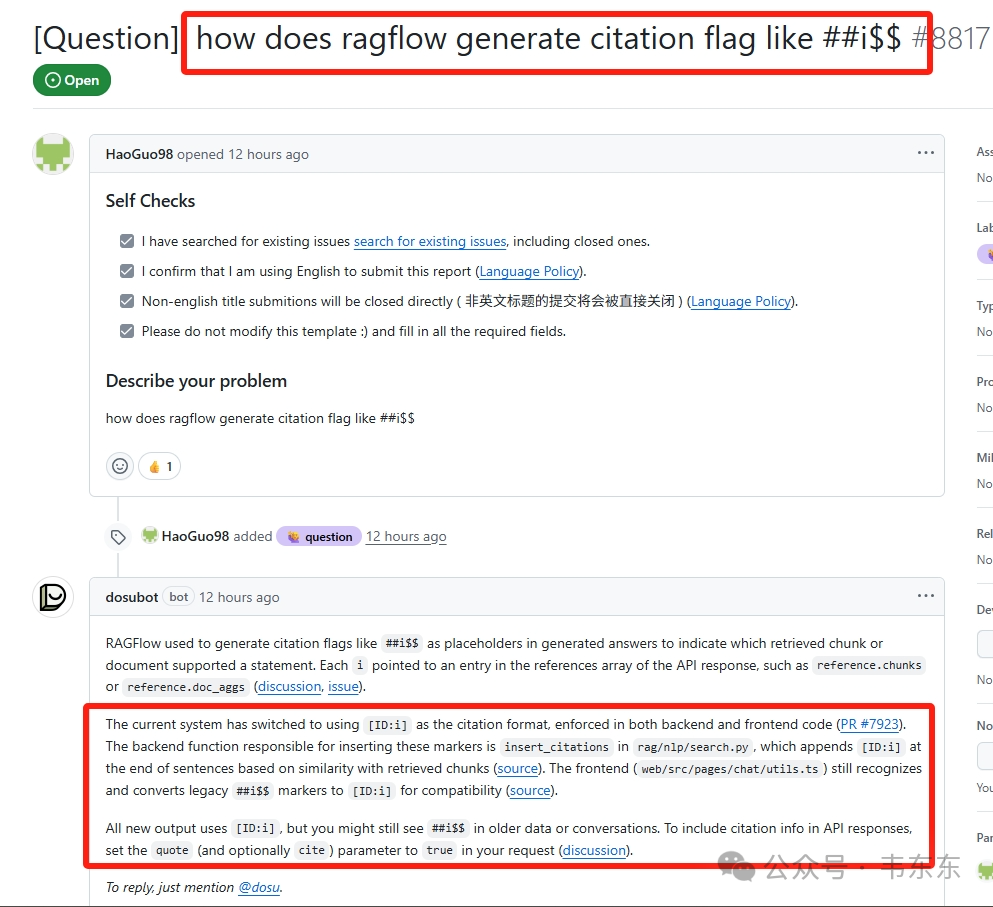
但在被用户以源码中的 citation_prompt 质疑后,它又提出了一种“双模式竞争”理论,暗示 LLM 和后端是两条可能冲突的独立路径。不过不看源码就能猜到,这种说法显然是不合理的。但是具体还是要从源码中找答案。
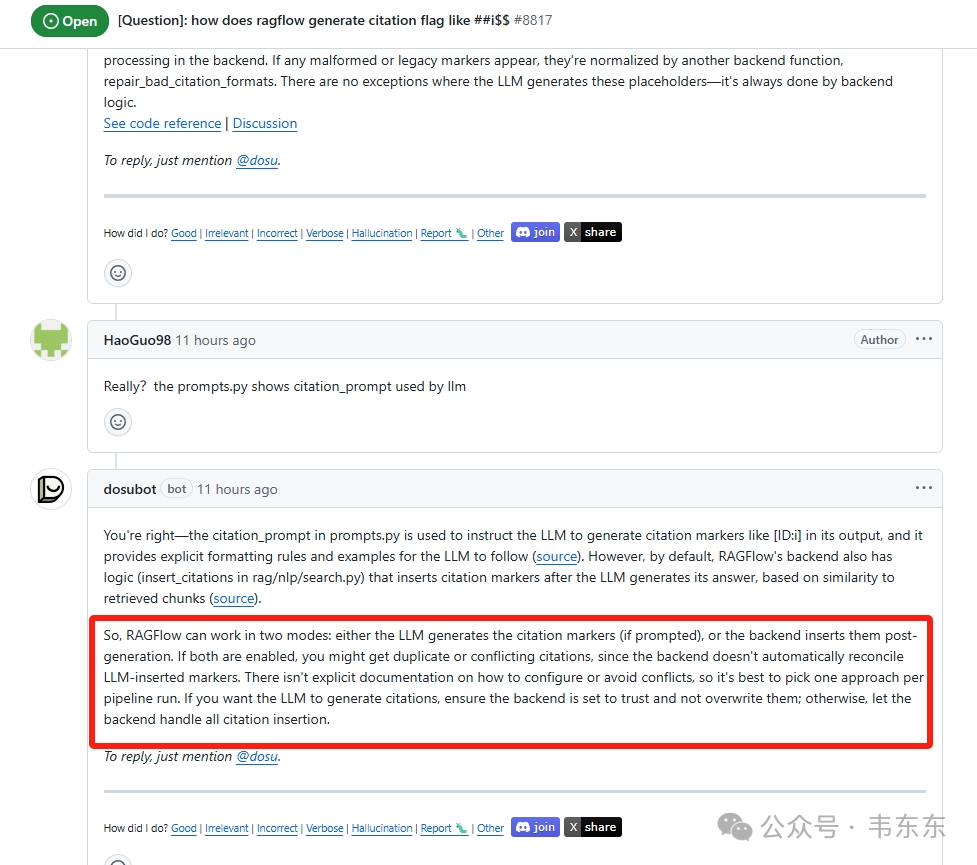
2、后端关键函数分析
要找到引用的源头,首先应该查看后端代码。在 RAGFlow 的源码中,我在 rag/nlp/search.py 文件里,找到了一个名为 insert_citations 的关键函数。
这段代码的逻辑很清晰的说明了以下三个问题:
1.输入是纯文本: 该函数的输入 answer 是 LLM 生成的纯净答案。它完全不关心 answer 是否已经带有 LLM 自己生成的引用标记。
2.独立计算: 函数的核心是 hybrid_similarity,它完全基于内容相似度(结合了向量语义和关键词文本)来独立判断每个句子与知识块的关联。这是一个从零开始、基于数据和算法的计算过程。
3.权威注入: 函数最后将自己计算出的引用 [ID:c] 注入到文本中,并返回最终结果。
初步结论非常明确,RAGFlow 的引用完全由后端算法基于内容相似度独立生成,拥有最终的、绝对的决定权。 它不依赖、不修改、也不信任 LLM 可能生成的任何引用。这当然也是符合最佳实践的做法。
3、前端对应溯源
进一步的问题是,既然知道后端生成了带有 [ID:i] 标记的字符串。那么前端是如何把这个文本标记变成一个可点击、可交互的链接的呢?
3.1message-item 组件
在 web/src/components/message-item/index.tsx 中,可以看到它负责渲染一个完整的消息气泡。但它并不亲自处理消息内容,而是将任务委托了出去。
3.2markdown-content 组件
真正的魔法发生在 web/src/pages/chat/markdown-content/index.tsx。这个组件接收到原始字符串后,执行了最终的“查找与替换”操作。
前端的处理流程清晰地展现了“职责分离”原则。MessageItem 负责消息的整体结构,而 MarkdownContent 负责将后端生成的 [ID:i] 文本标记,通过查找替换的方式,转换为用户可以交互的 UI 组件。这再次证实了所有引用处理在数据到达前端之前,必须已经在后端全部完成了。
4、提示词引导生成的巧思
既然后端和前端的逻辑都很清晰,还没有回答的一个问题是,如果后端函数是引用的唯一来源,那为什么 RAGFlow 的源码中还要在 rag/prompts/citation_prompt.md 中写下引导 LLM 生成引用的规则,而这个引用最终并不会使用。
看到这里,就知道为啥 GitHub 机器人所说的“双模式竞争”纯属瞎编了。citation_prompt 的真正目的,不是为了“结果”,而是为了“过程”。
换句话说,不是为了得到 LLM 生成的 [ID:i] 这个结果,而是为了规范 LLM 生成答案文本的整个过程。它通过这种方式向 LLM 施加了强烈的约束。
1.降低幻觉: 通过强制要求 LLM“必须为你的话找到出处”,系统在源头上极大地降低了内容幻觉。
2.保证内容质量: LLM 必须生成与原文高度相关的内容。
3.为后端铺路: 正是这份高质量的草稿,让后端的 insert_citations 函数能够游刃有余地进行精准的相似度匹配,并最终完成权威的标注工作。
5、写在最后
RAGFlow 的引用生成机制,也形象的展示了 LLM 应用落地的核心范式。生产实践可用的关键不在于对 LLM 能力的盲目相信(当然最好用最先进的 LLM),也不在于过多的依赖传统的规则引擎,而在于把 LLM 作为一个强大但需要被引导和验证的推理核心,并围绕它构建一套由确定性工程逻辑组成的脚手架,最后给出三个类似的样例作为参考:
1.AI Agent 与工具调用 (Tool Calling)
让 LLM 自由思考(Chain of Thought),分析用户意图,并决定需要调用哪个 API(工具)。但比如一旦 LLM 决定调用 get_weather("北京"),这个 API 本身的执行过程是完全确定的。系统不会让 LLM 去“创造”天气数据,而是通过严格的函数调用获取真实、可信的结果。
2.结构化数据提取 (JSON Mode)
对于一段非结构化的用户评论:“我喜欢这款手机的屏幕,但电池太不给力了”,通过强制启用 JSON Mode,并提供 Pydantic 等模式定义,来约束 LLM 的输出必须符合{ "positive_feedback": "屏幕", "negative_feedback": "电池" }这样严格的格式。LLM 可以在内容上发挥,但格式被约束,这也保证了下游程序的可解析性。
3.黑盒兜底机制 (Fallback)
在许多客服机器人中,首先尝试让 LLM 直接回答用户问题。但如果比如连续两次回答的置信度都低于某个阈值,或者触发了特定关键词,系统会无缝切换到人工客服或预设的、基于规则的流程(确定性)。这也是目前业界常用的一种经典的平衡策略。


