本文发现一个影响所有大型语言模型(LLMs)的信息检索问题。该任务对人类没有难度,但是所有 LLM 均出现显著错误。并对全局记忆(memory)和长推理任务(long reasoning)造成显著损害。 相关论文已被 ICML 2025 Workshop on Long Context Foundation Models 接收。

- 论文标题: Unable to Forget: Proactive Interference Reveals Working Memory Limits in LLMs Beyond Context Length
- arXiv: https://arxiv.org/abs/2506.08184
- GitHub: https://github.com/zhuangziGiantfish/Unable-to-Forget
- 交互式演示网站(强力推荐!45 秒快速理解): https://zhuangzigiantfish.github.io/Unable-to-Forget/ 点击页面中央的 “Mix” 按钮即可直观体验实验与错误模式。
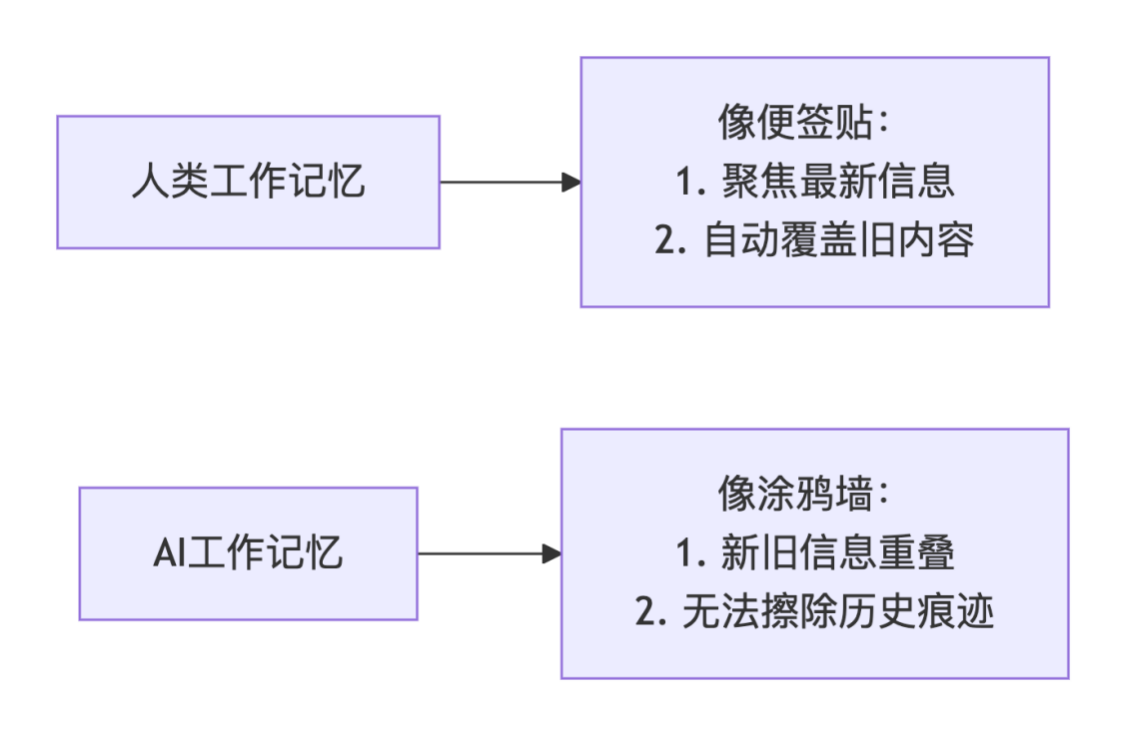
实验核心设定
假设给模型一串动态更新的数据,比如:“Blood Pressure=120, Bp=135, Bp=119”,然后要求 LLM 回答:“请告诉我血压(BP)的最后一个数值是多少?”
显然对人类来说,这个任务非常简单,答案显而易见是最后一个值 119。这种任务模式在金融(账户余额变化)、医疗(生理指标跟踪)、等所有需要追踪动态数据的领域中都极为常见。目前所有主流 LLMs(从最新的 GPT-4.1、Llama-4、DeepSeek-V3,到 Llama-3、Qwen-2.5 等,参数规模从 0.6B 到 600B + 不等)都无法稳定地提取最后一个数值,而且错误方式呈现出明确的数学规律。
核心发现:普适的衰减曲线
- 随着更新次数增加,所有模型的准确率都呈现一致的对数线性下降(log-linear decline)。
- 随着干扰增多,准确率最终稳定地降至 0%。此时,所有模型彻底失灵,100% 产生幻觉(hallucination),100% 无法给出正确答案。
- 这种一致的衰减模式跨越了模型架构、规模和训练资源的差异,强烈暗示问题的根源可能位于 Transformer 架构或其所依赖的注意力机制等基础层面。
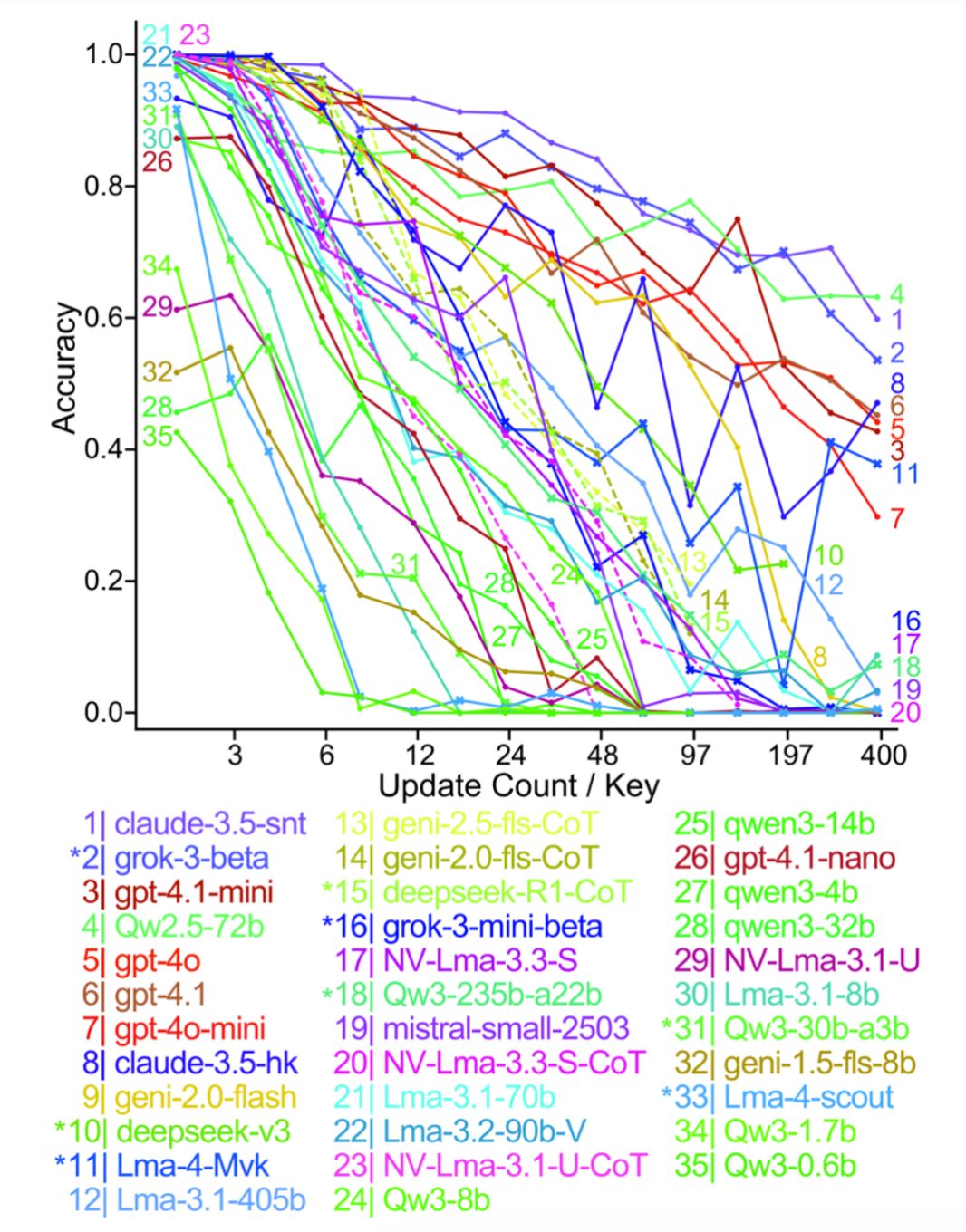
图 1 显示,当语言模型需要在大量语义相似的干扰项之后检索特定目标信息时,其检索准确率会显著且持续地降低,这种对数线性下降趋势在所有主流模型中均被观察到。

图 2 展示了 LLM-PI 测试的基本输入示例:模型需要处理一段连续更新的键值 key-value 信息流(如 “visual art” 对应多个值),并在更新结束后准确检索出每个键对应的最终值(图中以加粗显示)。
实验设置
测试中要求模型处理 1 到 46 个不同的 Key,每个 Key 的更新次数在 1 到 400 次之间。随机,乱序混合这些更新,然后模型正确提取每个 key 的 last vale(最新值)的正确率
与人类对比
这一任务的设计本质上非常简单:(1)不涉及复杂的搜索,(2)不存在逻辑上的难度。人类可以轻松调整注意力,只关注最新信息,几乎不会被上文内容干扰。 分析错误答案显示,模型经常错误地提取了无关的上文更新值作为最终答案,这表明当前的 LLMs 在处理此类信息流时难以有效忽略或过滤掉非目标(旧)信息。进一步的错误分布分析揭示,LLMs 表现出类似有限工作记忆容量的行为模式:它们似乎在有限的表征空间内记录键值对,一旦更新次数超出该容量,检索性能便会彻底失效。
本文还发现,有多种方式可以触发搜索失败,均具备相同的对数衰减曲线。1. 增加同时最终 key 的数量,或者 2. 信息检索目标 value 的长度。这些现象均会对 llm 检索任务准确性造成显著影响。同时在人类实验中也发现类似现象。
现象解读:“Unable to Forget”
大模型无法忽略或者忘记无关信息,从而造成彻底搜索失效:
尤为反直觉的是,即使采用最直观的自然语言干预策略,例如在输入中明确高亮标注答案区域,或直接告诉模型 “专注最新更新” 或 “忘记之前信息”,也无法显著改善模型表现。这说明干扰效应强大到足以覆盖明确的自然语言指令,迫使模型不得不关注旧信息。由此本文提示,要对抗干扰,很可能需要对模型架构本身或训练范式进行根本性调整,而非仅依赖提示工程。
进一步分析:LLMs 为何难以稳定提取最新信息?
对错误的分析表示,LLMs 的失败并非随机失误,而是系统性地受到反复更新的影响。随着干扰量的增加,错误呈现清晰的阶段性演变:
- 初期:邻近干扰占主导,检索错误来源主要是紧邻末尾的 value。
- 中期:干扰范围扩散,错误来源显著扩大到全文任何区域的 value。
- 后期:彻底混乱,模型输出高度分散和大量检索到从未输入的值。
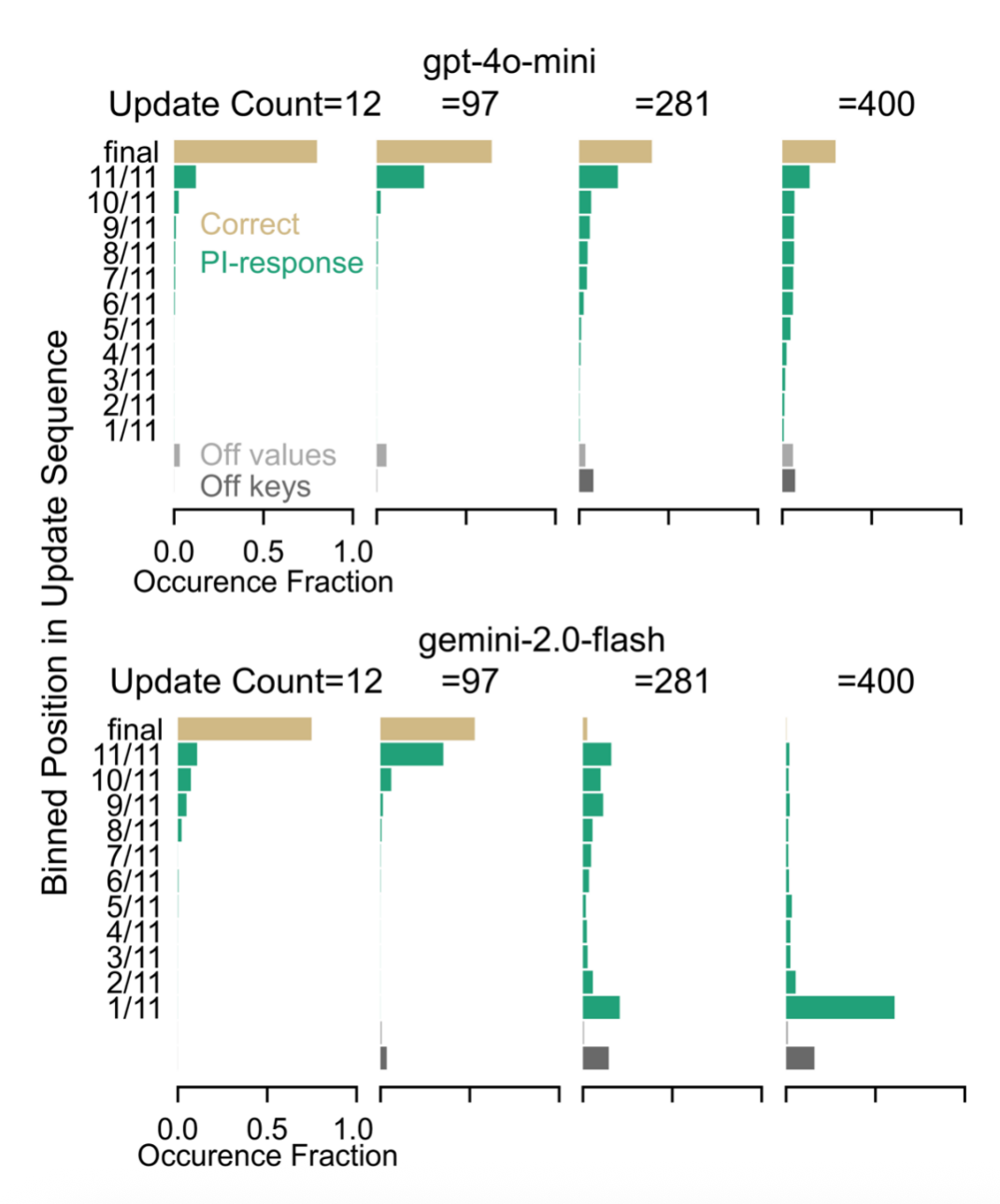
图 4 将模型对某个键的响应按其值在更新流中的位置(分 11 个区间,Bin 1 最早 - Bin 11 最终)进行统计。结果显示:随着更新次数增加(左→右面板),正确命中最终值(土黄)的比例骤降。 更值得注意的是,错误响应从主要聚集在最终更新附近(如 Bin 10-11,可能是混淆相邻更新),逐渐转变为分散到更早的区间(Bin 1-9)。此外,返回不存在值(“幻觉”,浅灰)和未返回值(“失效”,深灰)的错误也急剧增加,共同描绘出信息过载下模型记忆检索系统的崩溃图景。
Top-Down 调控的彻底失效
与人类截然不同,LLMs 在此类提取任务的表现,几乎不受 “自上而下”(Top-Down)prompt 提示的影响。这也解释了为何思维链(CoT) 模型在此问题上没有性能改善。
- 自然语言 prompt 失效: 本文测试了多种提示词(prompt)变体,明确引导模型关注最新信息或忽略历史干扰(例如,明确标注答案区域、“专注下文” 或指令 “忘记之前内容”)。结果: 所有自然语言干预措施,均未能显著提升模型在的提取准确率,也未能改变的 log-linear 正确率衰退模式。干扰累积时,模型依然顽固地滑向彻底错误(0% 正确率)
- CoT 模型没有改善,即使不设限制的让模型输出冗长的的推理过程(CoT),其提取错误率曲线与不使用 CoT 的基线模型几乎完全重合。这表明,推理无法有效提升模型抵抗上下文信息干扰的能力。
- 这说明,干扰信息对模型行为的影响超越了自然语言指令所能引导或抑制的范围。模型 “理解” 了指令(如声称要专注最新值),但在实际操作中无法有效执行,仍被历史信息强力牵引注意。
- 问题触及架构或训练根本: prompt 和 CoT 模型的无效性暗示,仅靠提示工程(Prompt Engineering)无法根治此问题。很可能需要在模型架构设计(如注意力机制、记忆模块)或训练目标 / 方法(如引入抗干扰的显式训练信号)层面进行创新性调整。这指向了未来研究的一个关键方向。
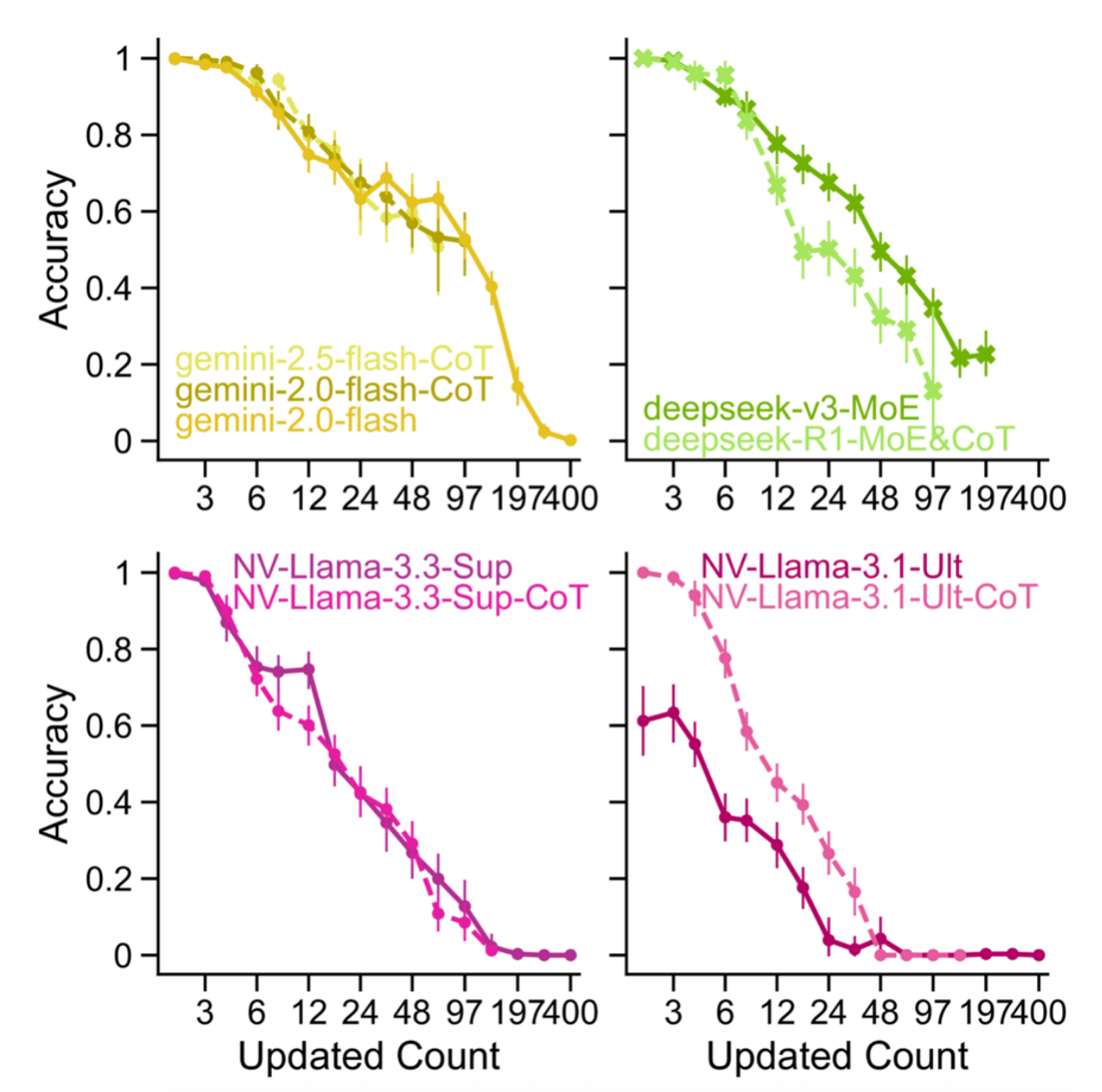
图 13 思维链(CoT)模型对提升信息检索抗干扰能力几乎无效。启用 CoT 的版本(虚线)性能曲线与其基础模型(实线)高度重合或更差。证实:干扰导致的检索失败是底层机制问题,无法通过附加的 “思考” 过程克服。
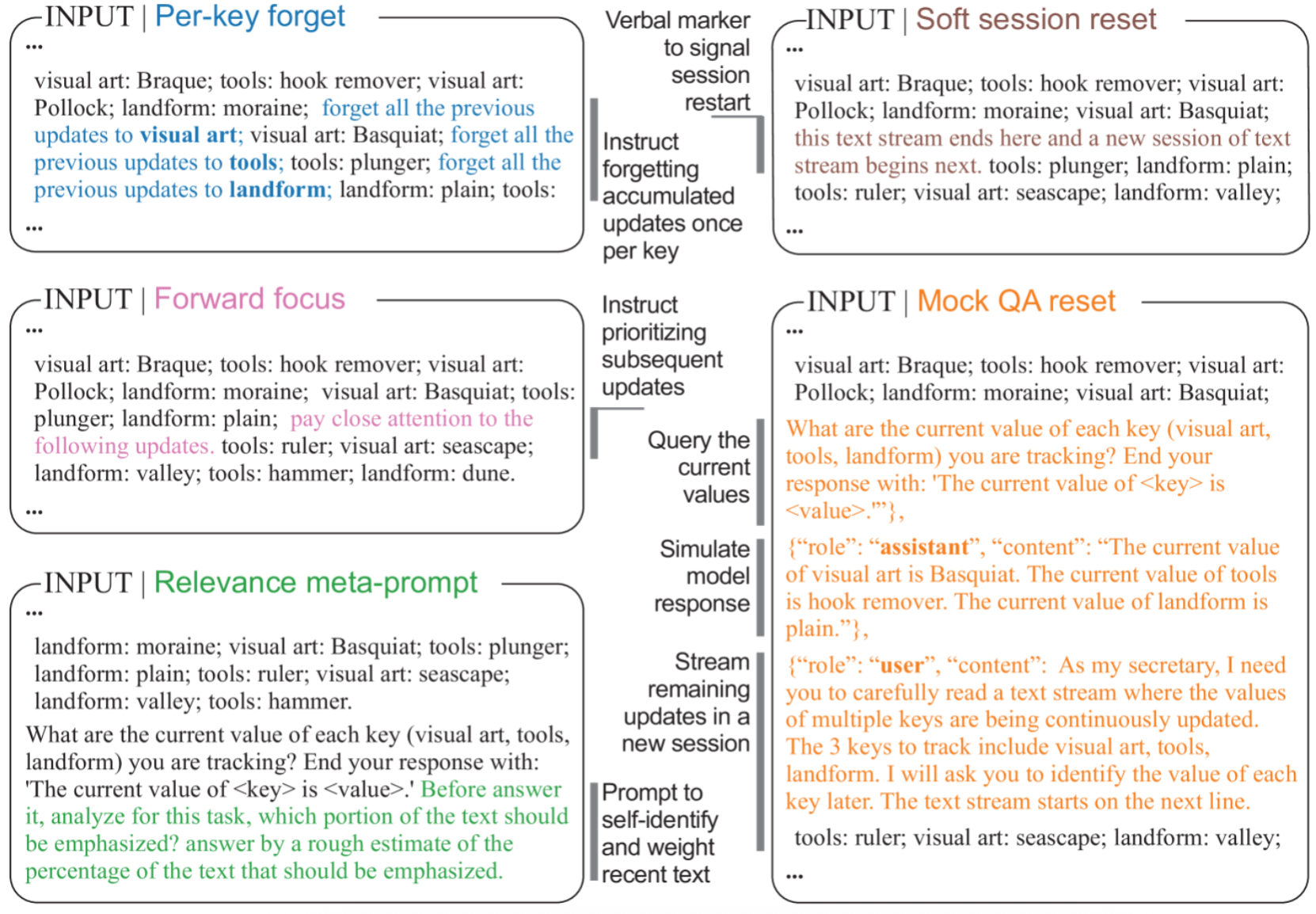
图 10 展示了五种不同的自然语言干预策略(如指令模型 “忘记” 特定键历史、提示关注后续信息、自我评估相关性、软会话重置以及技术性的 Mock QA 重置),它们被设计插入到信息流后期以试图对抗干扰。然而实验表明,所有这些提示工程策略均未能有效缓解信息过载导致的检索性能崩溃,对数衰减模式依旧,突显了现有自然语言干预的局限性。
“Unable to Forget”
此外受 LLM 行为研究(LLM Hack)的启发,本文作者设计了一种非自然语言的 prompt:在输入中构造一段虚假的人机对话,暗示所有上文更新都属于另一个已被回答完毕的旧问题。这种 “欺骗性上下文隔离” 策略部分提升了正确率,但提升后的正确率依然遵循 log-linear decay 规律。这说明:LLMs ** 无法真正 “忘记” 或忽略那些造成干扰的信息,只能通过特定输入形式进行一定程度的 “屏蔽”。
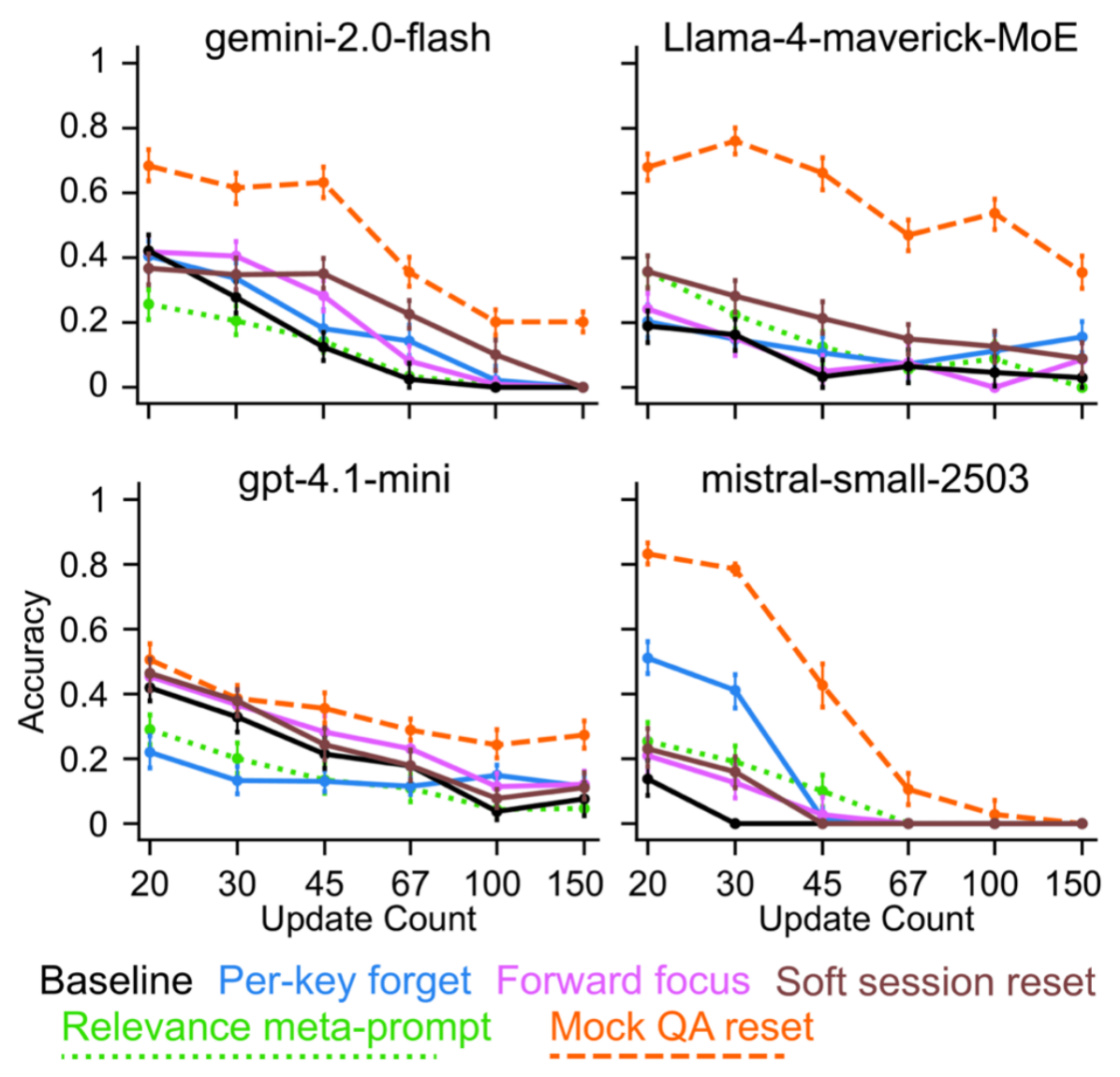
图 11 揭示了关键结果:旨在缓解干扰的自然语言提示策略(实线)效果普遍微弱,在高更新量下与基线(黑线)性能曲线几乎无区别,部分策略反而有害。唯一例外是结构化 hack-Mock QA 重置(橙色虚线),作为人为设计的 “hack method”,它带来了实质性提升,但仍无法阻止准确性随信息量增长的整体下滑。
干扰” 作为独立变量:
不同于业内通常认为的输入文本长度导致注意力稀释,本文控制变量实验证明。模型性能的下降主要由干扰强度驱动,而非单纯由文本长度引起。具体来说,即使固定输入文本长度,控制干扰强度,LLMs 的错误率依然表现出对数上升。
该实验对 LLM 在 MRCR 测试中的不良表现提供了解释角度
DeepMind 的 MRCR 和 OpenAI 的 Open MRCR 通过仿真测试 在长文本中插入大量相似项,揭示了 LLM 区分相似信息的弱点。本文的工作提供了互补且更底层的视角,并证明不需要海量信息也可以触发检索错误:MRCR 测试所称为的共指消解(coreference)对应人类认知领域的干涉(interference)现象
- 本文定量剥离出 “干扰”(Interference)作为核心独立变量 ,直接证明其对性能的因果性负面影响。
- 揭示了此类任务失败的核心驱动因素之一是模型的抗干扰容量(Anti-Interference Capacity)不足,并提供了精确的量化分析框架(log-linear decay)
OpenAI 在 GPT-4.1 文档中指出,客户(尤其在法律、金融领域)高度关注频繁更新并提取信息的任务。(链接 Introducing GPT-4.1 in the API)。本文直接指向了 MRCR 的底层挑战之一不仅是海量信息的搜索造成的。而是 LLM 在 interference 信息面前的检索失效造成的。
实验同时对认知科学角度提供了对比
1. 认知科学的桥梁: 该测试在认知科学领域(proactive interference 测试)被严格用于衡量人类工作记忆(Working Memory)容量和抗干扰能力。实验采用了严格对应认知科学的实验范式。因此,结果可被解读为:LLMs 表现出某种类似工作记忆的有限容量机制,其 “抗干扰容量”(Anti-Interference Capacity)是衡量该机制强度的关键指标。
2.LLMs 的普遍失效,强烈暗示其目前尚缺乏人类般有效进行 Top-Down 控制、以优化利用上下文信息的能力 *。任务要求极其明确,搜索难度极低(理论上最利于 LLM)。提升这种能力,对于增强 LLM 在金融、医疗监测等依赖动态数据追踪的任务中的基础可靠性至关重要。也对执行 long reasoning (长推理)的能力提供可靠性支持。
直观演示
为了直观地展示这个现象,论文搭建了一个交互式演示网站 https://zhuangzigiantfish.github.io/Unable-to-Forget/ 点击页面中央的 “MIX” 按钮,通过约 3-4 秒的动画演示, 45 秒内迅速理解实验设计和模型的系统性错误模式。

TL;DR:核心结论
LLMs 目前不具备人类水平的 Top-Down 信息关注和处理控制的能力,尤其是在需要抵抗语义相似的上下文信息干扰、精确提取数据的场景下无法稳定工作。
ICML 评审意见亮点:
1. 揭示了一个此前未被发现的 LLM 检索失败现象。
2. 采用认知科学启发的测试设计方法,具有显著新颖性。
论文作者介绍
本研究由王楚培(第一作者、通讯作者,弗吉尼亚大学物理学士,具哲学背景的跨学科研究者)与孙嘉秋(共同第一作者、通讯作者,纽约大学神经科学中心博士生,师从纽约大学神经与认知科学副教授田兴)共同主导。两位作者分别具备物理、建筑与哲学的多元背景,致力于从认知系统崩溃点探索智能本质。
特别感谢郑喆阳(Flatiron Institute CCN 客座研究员、纽约大学博士生)与邝一伦(纽约大学 CILVR Lab 博士生,导师:Yann LeCun)在项目的发起与推进过程中,为团队提供了关键性的咨询和建议。


