最近「上下文工程」有多火?Andrej Karpathy 为其打 Call,Phil Schmid 介绍上下文工程的文章成为 Hacker News 榜首,还登上了知乎热搜榜。
之前我们介绍了上下文工程的基本概念,今天我们来聊聊实操。
为什么关注「上下文工程」
我们很容易将 LLM 拟人化——把它们当作能够「思考」、「理解」或「感到困惑」的超级助手。从工程学的角度来看,这是一个根本性的错误。LLM 并不具备信念或意图,它是一个智能的文本生成器。
更准确的看法是:LLM 是一个通用的、不确定的函数。这个函数的工作方式是:你给它一段文本(上下文),它会生成一段新的文本(输出)。

- 通用:意味着它能处理各种任务(如翻译、写代码),无需为每个任务单独编程。
- 不确定:意味着同样的输入,每次可能得到稍有不同的输出。这是它的特点,不是毛病。
- 无状态:意味着它没有记忆。你必须在每次输入时,提供所有相关的背景信息,它才能「记住」对话。
这个视角至关重要,因为它明确了我们的工作重心:我们无法改变模型本身,但可以完全控制输入。所有优化的关键,在于如何构建最有效的输入文本(即上下文),来引导模型生成我们期望的输出。
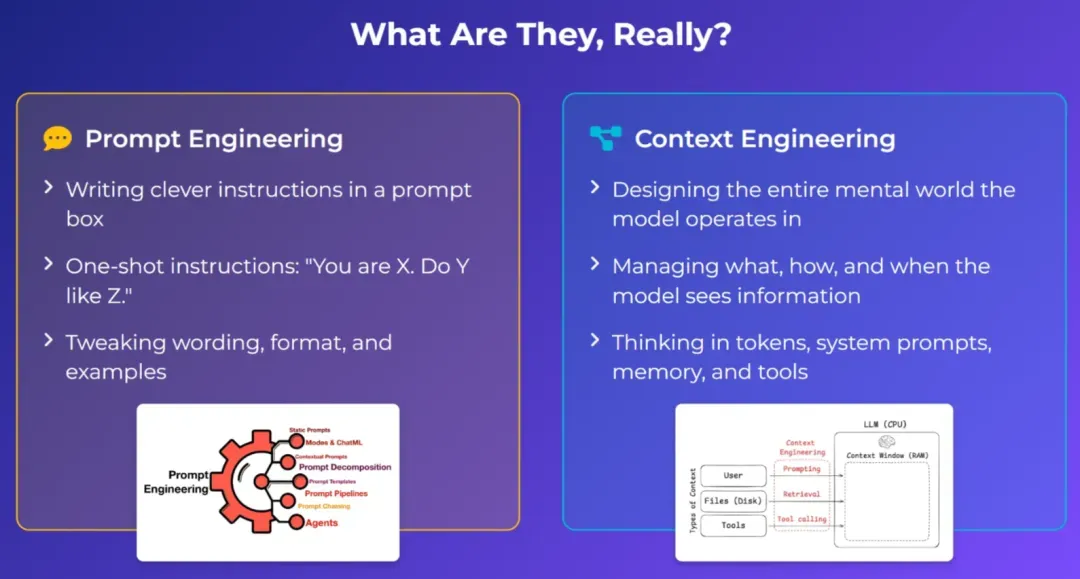
「提示词工程」一度很火,但它过于强调寻找一句完美的「魔法咒语」。这种方法在真实应用中并不可靠,因为「咒语」可能因模型更新而失效,且实际输入远比单句指令复杂。
一个更精准、更系统的概念是「上下文工程」。
两者的核心区别在于:
- 提示词工程:核心是手动构思一小段神奇的指令,如同念咒。
- 上下文工程:核心是构建一个自动化系统,像设计一条「信息流水线」。该系统负责从数据库、文档等来源自动抓取、整合信息,并将其打包成完整的上下文,再喂给模型。
正如 Andrej Karpathy 所说,LLM 是一种新型的操作系统。我们的任务不是给它下达零散的命令,而是为它准备好运行所需的所有数据和环境。
上下文工程的核心要素
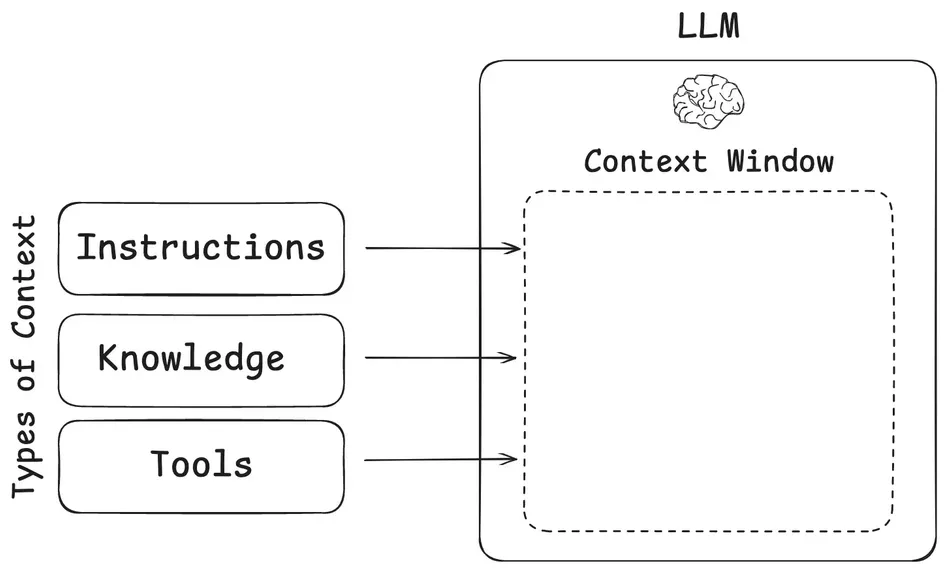
简单说,「上下文工程」就是打造一个「超级输入」的工具箱。我们听到的各种时髦技术(比如 RAG、智能体),都只是这个工具箱里的工具而已。
目标只有一个:把最有效的信息,用最合适的格式,在最恰当的时机,喂给模型。
以下是工具箱里的几种核心要素:
- 指令:下达命令这是最基础的,就是直接告诉模型该做什么。比如命令它「扮演一个专家」,或者给它看几个例子,让它照着学。
- 知识:赋予「记忆」 模型本身没有记忆,所以我们要帮它记住。在聊天机器人里,就是把聊天记录一起发给它。如果记录太长,就做个「摘要」或者只保留最近的对话。
- 工具:
- 检索增强生成 (RAG):给它一本「开卷考试」用的参考书为了防止模型瞎说(产生幻觉),我们可以让系统先从我们自己的知识库(比如公司文档)里查找相关资料,然后把「参考资料」和问题一起交给模型,让它根据事实来回答。
- 智能体:让它自己去「查资料」
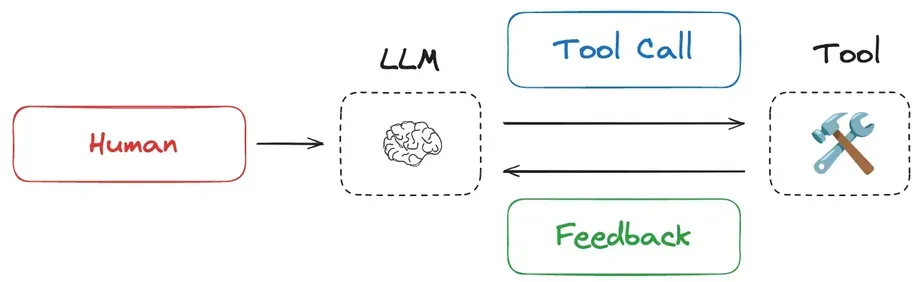
这是更高级的玩法。我们不再是提前准备好所有资料,而是让一个聪明的「智能体」自己判断需要什么信息,然后主动使用工具(比如上网搜索、查数据库)去寻找答案,最后再汇总起来解决问题。
总而言之,所有这些技术,无论简单还是复杂,都是在回答这一个问题:「怎样才能给模型打造出最完美的输入内容?」
上下文工程的实践方法论
使用 LLM 更像做科学实验,而不是搞艺术创作。你不能靠猜,必须通过测试来验证。
工程师的核心能力不是写出花哨的提示,而是懂得如何用一套科学流程来持续改进系统。这套流程分两步:
第一步:从后往前规划(定目标 → 拆任务)
从你想要的最终结果出发,反向推导出系统的样子。
- 先想好终点:明确定义你希望 LLM 输出的完美答案是什么样的(内容、格式等)。
- 再倒推需要什么原料:要得到这个完美答案,LLM 的输入(上下文)里必须包含哪些信息?这就定义了你的系统需要准备的「原料包」。
- 最后设计「流水线」:规划出能够自动生产这个「原料包」的系统。
第二步:从前往后构建(搭积木 → 总装)
规划好后,开始动手搭建。关键是:搭好一块,测一块,最后再组装。
- 先测试「数据接口」:确保能稳定地获取原始数据。
- 再测试「搜索功能」:单独测试检索模块,看它找资料找得准不准、全不全。
- 然后测试「打包程序」:检查那个把所有信息(指令、数据)组装成最终输入的程序是否正常工作。
- 最后才进行「总装测试」:当所有零件都确认无误后,再连接起来,对整个系统进行端到端测试。这时,你可以完全专注于评估 LLM 的输出质量,因为你知道它收到的输入肯定是正确的。
核心思想就是:通过这种「先规划、后分步搭建和测试」的严谨流程,我们将使用 LLM 从凭感觉的艺术,变成了有章可循的工程科学。
实践
更具体的实践方法,大家可以参考 Langchain 最新的博客和视频,里面详细介绍了上下文工程当前主流的四大核心方法,并展示了 LangChain 生态中 LangGraph 和 LangSmith 如何助力开发者高效实施上下文工程。
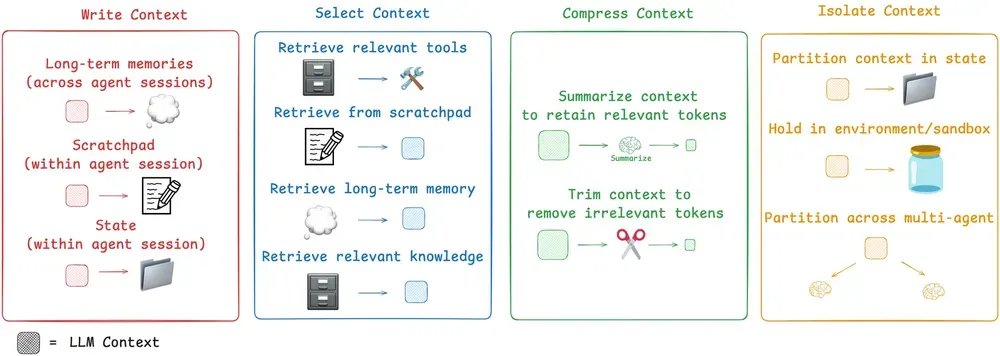
- 博客地址:Context Engineering for Agents
- 视频地址:Context Engineering for Agents (LangChain)


