当我们读到“苹果”“香蕉”“西瓜”这些词,虽然颜色不同、形状不同、味道也不同,但仍会下意识地归为“水果”。
哪怕是第一次见到“火龙果”这个词,也能凭借语义线索判断它大概也是一种水果。
这种能力被称为语义压缩,它让我们能够高效地组织知识、迅速地对世界进行分类。
那问题来了:大型语言模型(LLM)虽然语言能力惊人,但它们在语义压缩方面能做出和人类一样的权衡吗?
为探讨这一问题,图灵奖得主LeCun团队,提出了一种全新的信息论框架。
该框架通过对比人类与LLM在语义压缩中的策略,揭示了两者在压缩效率与语义保真之间的根本差异:
LLM偏向极致的统计压缩,而人类更重细节与语境。
 图片
图片
语义压缩对比框架
要实证性地研究LLM的表征方式与人类概念结构之间的关系,需要两个关键要素:
稳健的人类概念分类基准
研究团队基于认知科学中的三项经典研究(Rosch 1973、1975和McCloskey & Glucksberg 1978),构建了一个涵盖1049个项目、34个语义类别的统一基准。
这些数据不仅提供了类别归属信息,还包含人类对各项目“典型性”的评分,反映了人类认知中概念形成的深层结构。
相比现代众包数据,这些经过专家严格设计的数据集更具可信度与解释力,为LLM的类人性评估提供了高保真的比较基础。
多样化的LLM模型选择
为全面评估不同大型语言模型在概念表征上的差异,研究团队选取了30+LLMs(BERT、LlamA、Gemma、Qwen等),参数规模从3亿到720亿不等。
所有模型均从输入嵌入层提取静态词元表示,以贴近人类分类实验中“去上下文”的刺激方式,确保模型和人类的认知基准保持一致,便于公平比较。
为分析LLM与人类在表达和组织语义信息时的差异,研究引入了一个信息论框架。
该框架借鉴了两大经典信息论原理:
- 速率失真理论:描述压缩效率与信息失真之间的最优权衡;
- 信息瓶颈原理:关注在压缩表示的同时,最大程度保留与目标相关的信息。
LLM与人类在表征策略上的关键差异
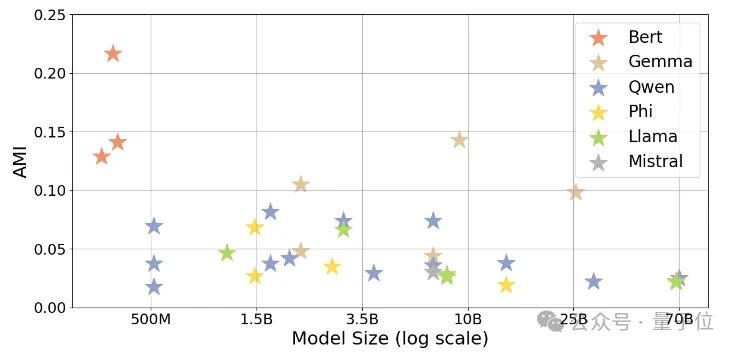
研究发现,LLM的概念分类结果与人类语义分类的对齐程度显著高于随机水平。
这一结果验证了LLM在语义组织方面的基本能力,并为后续更细粒度的语义结构对比奠定了基础。
 图片
图片
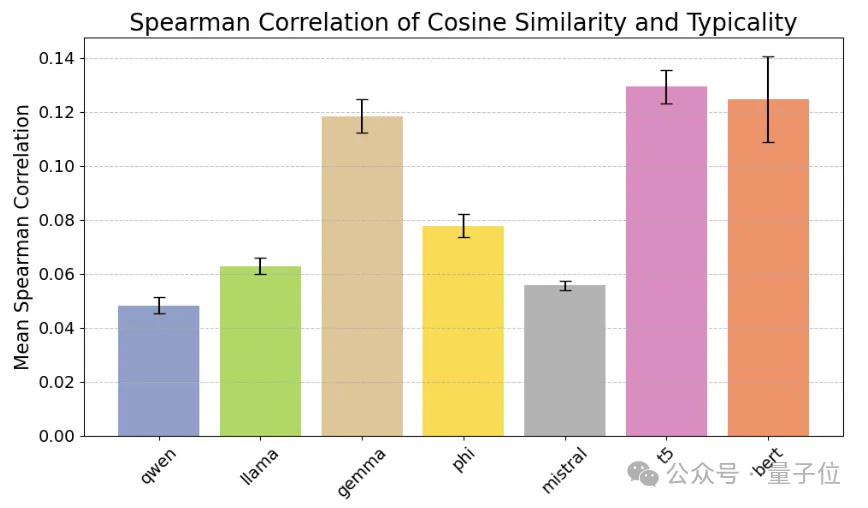
但是大型语言模型真的理解细节吗?
答案是:LLM难以处理细粒度的语义差异。它们的内部概念结构与人类对类别归属的直觉不相符。
 图片
图片
人类典型性判断与LLM余弦相似度之间的斯皮尔曼相关系数较弱且大多数不显著,表明两者在概念表征结构上存在差异。
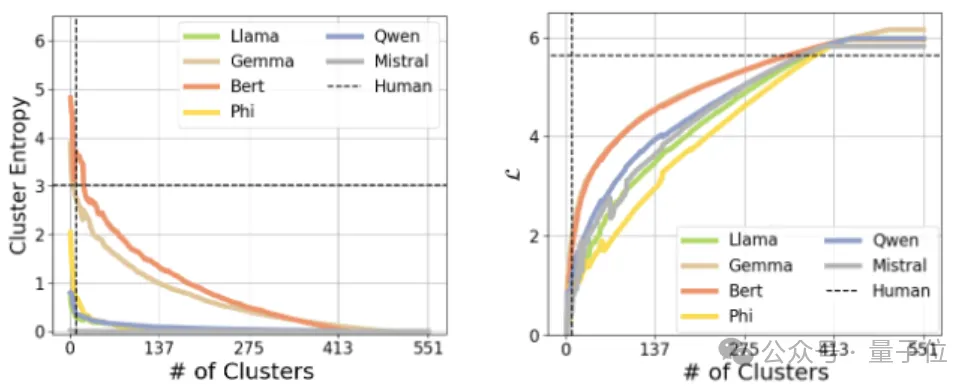
那LLM和人类在信息压缩与语义保真上存在哪些关键差异呢?
LLM侧重于统计压缩,力求最大程度地减少冗余信息;而人类则更注重适应性和丰富性,强调保持灵活性和上下文的完整性。
 图片
图片
研究团队
这项研究由斯坦福大学与纽约大学联合开展,团队成员均来自这两所高校。
其中,第一作者为斯坦福大学博士后研究员Chen Shani。
 图片
图片
更让网友震惊的的是,Yann LeCun也为此研究的作者之一。
 图片
图片

Yann LeCun是当今人工智能领域最具影响力的科学家之一,现任 Meta(原 Facebook)首席人工智能科学家,同时也是纽约大学教授。
LeCun早在1980年代便开始研究神经网络,最著名的贡献是提出了卷积神经网络(CNN)的核心架构——LeNet-5,用于手写数字识别。
该网络是现代深度学习模型的雏形,为后续图像识别和计算机视觉技术的发展奠定了坚实基础。
他与Geoffrey Hinton、Yoshua Bengio被誉为“深度学习三巨头”,共同推动了深度学习的理论与应用突破。
2018年,三人因在深度学习领域的杰出贡献,荣获了计算机科学领域的最高奖项——图灵奖。
除了技术创新,LeCun还积极推动深度学习技术在工业界的应用,尤其是在Meta,领导团队将人工智能技术应用于大规模系统。
他同时是自监督学习的积极倡导者,认为这是实现通用人工智能(AGI)的关键路径之一。
可以说,LeCun的研究对人工智能技术的演进产生了重要影响。
论文地址:https://arxiv.org/abs/2505.17117
参考链接:https://x.com/ziv_ravid/status/1928118800139841760


