模型

Sakana AI 扔出重磅炸弹:让机器像人一样“持续思考”
人工智能领域最近迎来了一项引人关注的新进展。 总部位于东京的 Sakana AI 发表了一篇题为《连续思维机器》(Continuous Thought Machines)的论文,提出了一种旨在让机器模拟生物大脑复杂神经活动和“持续思考”能力的新模型。 这篇论文的核心观点是挑战当前深度学习中对时间动态的简化处理,试图将神经元层面的时序处理和同步机制重新引入,使“神经时序”成为人工智能模型的基础。
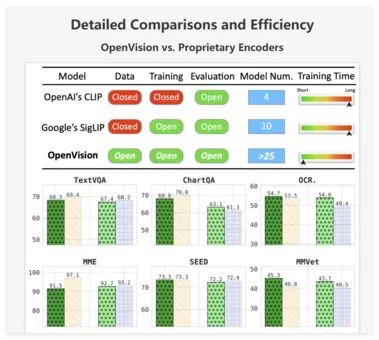
新一代开源视觉编码器 OpenVision 发布:超越 CLIP 与 SigLIP 的强大选择
加州大学圣克鲁兹分校近日宣布推出 OpenVision,这是一个全新的视觉编码器系列,旨在为 OpenAI 的 CLIP 和谷歌的 SigLIP 等模型提供替代方案。 OpenVision 的发布为开发者和企业带来了更多灵活性和选择,使得图像处理和理解变得更加高效。 什么是视觉编码器?视觉编码器是一种人工智能模型,它将视觉材料(通常是上传的静态图像)转化为可被其他非视觉模型(如大型语言模型)理解的数值数据。

200M参数吊打商业巨头!浙大-哈佛开源ICEdit,用1%资源实现图像编辑自由!一句指令生成海报级修图方案
浙江大学联合哈佛大学提出一种高效的基于指令的图像编辑框架ICEdit,与以往的方法相比,ICEdit仅需1%的可训练参数(200M)和0.1% 的训练数据(50k),就展现出强大的泛化能力,能够处理各种编辑任务。 相比 Gemini、GPT4o 等商业模型,我们更加开源,成本更低,速度更快(处理一幅图像大约需要 9 秒),性能强大。 使用ComfyUI-nunchaku,仅需 4 GB VRAM GPU 就足以尝试我们的模型!

OpenAI深夜开源HealthBench,60个国家合力开发5000段真实对话
今天凌晨1点30,OpenAI开源了一个专门面向医疗大模型的测试评估集——HealthBench。 与以往测试集不同的是,该测试集的5000段核心测试对话,全部由来自60个国家/地区的26个专业262名医生打造,极大增强了该测试集的难度、真实性以及丰富度。 并且采用了多轮对话测试,而不是简单的答题或选择题模式。

Sam Altman最新万字专访:2025,Agent智能体应用大年
今天凌晨3点,全球著名投资机构红杉资本(Sequoia Capital)发布了,Sam Altman参加其举办的“2025 AI Ascent”大会。 OpenAI联合创始人兼首席执行官SamA ltaman作为特邀嘉宾,接受了32分钟的专访和现场提问。 Altaman回顾了OpenAI的创业历程、产品规划/发展、对AI行业的看法等。

GPT-5研发内幕首曝!OpenAI首席研究官:AGI指日可待
GPT-5到哪一步了? 最近,GPT-4.1核心研究员Michelle Pokrass透露,构建GPT-5的挑战在于,在推理和聊天之间找到适当的平衡。 她表示,「o3会认真思考,但并不适合进行随意聊天。
0.33秒生成1秒音频!Muyan-TTS 开源上线,播客、有声书场景完美适配
开源语音合成迎来新突破!近日发布的开源 TTS 模型 Muyan-TTS 专为播客、有声书、长视频等场景设计,具备零样本语音合成、极速生成与高连贯性朗读能力,是当前最适合批量化长语音生成的模型之一。 Muyan-TTS 基于超10万小时播客数据预训练,仅需 0.33秒即可生成1秒高质量音频,支持无需打断地朗读数分钟文本,语音自然流畅。 更支持说话人定制,任意声音克隆,一键生成具有个性化语气与节奏的语音内容。

推理模型越来越强,大模型微调还有必要吗?
最近笔者在将大模型服务应用于实际业务系统时,首先一般习惯性用一些闭源api服务,花上几块钱快速测试下流程,然后在去分析下大模型效果。 如果通过几次调整Prompt或者超参数还是出现的bad cases比较多(比如输出结果的结构化有问题,输出结果不理想,在某些专业领域不同模型结果表现不一并且效果比较差),这个时候需要考虑下通过微调的方式来训练大模型。 现在的大模型推理能力越来越厉害,人们开始怀疑:我们还需要花时间和资源去微调大模型吗?

18岁天才高中生独登顶刊,AI解锁150万新天体!斯坦福连夜发offer
在NASA的2000亿条数据中隐藏着150万个未知天体,而揭开它们神秘面纱的,竟是一位美国高中生! 他就是Matteo Paz,来自加州南帕萨迪纳高中的天才少年。 基于加州理工学院的研究,Matteo挖掘了美国国家航空航天局(NASA)某项任务「沉睡的数据」,并以独著身份在天文学顶级期刊发文。

苹果放大招!FastVLM 让视觉语言模型在 iPhone 上飞速 “狂飙”
苹果最近又搞了个大新闻,偷偷摸摸地发布了一个叫 FastVLM 的模型。 听名字可能有点懵,但简单来说,这玩意儿就是让你的 iPhone 瞬间拥有了“火眼金睛”,不仅能看懂图片里的各种复杂信息,还能像个段子手一样跟你“贫嘴”!而且最厉害的是,它速度快到飞起,苹果官方宣称,首次给你“贫嘴”的速度比之前的一些模型快了足足85倍!这简直是要逆天啊!视觉语言模型的 “成长烦恼”现在的视觉语言模型,就像个不断进化的小天才,能同时理解图像和文本信息。 它的应用可广了,从帮咱们理解图片里的内容,到辅助创作图文并茂的作品,都不在话下。

阿里通义千问成为日本AI发展的新基石
近日,日本经济新闻(NIKKEI)发表了一篇引人注目的报道,指出阿里巴巴的通义千问大模型正迅速成为日本人工智能开发的重要基础。 随着全球 AI 技术的飞速发展,通义千问的表现已在国际舞台上崭露头角,尤其是在日经新闻对各大 AI 模型进行的综合评测中,通义千问 Qwen2.5-Max 一举夺得第六名,超越了许多国内外知名模型,包括 DeepSeek-V3和 OpenAI 的 o3-mini 等。 日本的众多新兴企业正纷纷借助通义千问的强大能力,开发适用于自身的企业级 AI 模型。
苹果发布FastVLM模型,可在iPhone上运行的极速视觉语言模型
苹果正式发布FastVLM,一款专为高分辨率图像处理优化的视觉语言模型(VLM),以其在iPhone等移动设备上的高效运行能力和卓越性能引发行业热议。 FastVLM通过创新的FastViTHD视觉编码器,实现了高达85倍的编码速度提升,为实时多模态AI应用铺平了道路。 技术核心:FastViTHD编码器与高效设计FastVLM的核心在于其全新设计的FastViTHD混合视觉编码器,针对高分辨率图像处理进行了深度优化。

陶哲轩油管首秀:33分钟,AI速证「人类需要写满一页纸」的证明
快来围观,陶哲轩当视频博主了。 第一个产出就很炸裂:人类需要写满一页纸的证明,结果借助AI 33分钟就搞定了? 整个过程看起来一气呵成,还是全程“盲证”不用过脑子那种。

强迫模型自我争论,递归思考版CoT热度飙升!网友:这不就是大多数推理模型的套路吗?
CoT(Chain-of-thought)大家都很熟悉了,通过模仿「人类解题思路」,进而大幅提升语言模型的推理能力。 这几天,一个名为 CoRT(Chain-of-Recursive-Thoughts)的概念火了! 从名称上来看,它在 CoT 中加入了「递归思考」这一步骤。

CVPR2025|MCA-Ctrl:多方协同注意力控制助力AIGC时代图像精准定制化
本文由中国科学院计算技术研究所研究团队完成,第一作者为硕士生杨晗,通讯作者为副研究员安竹林,助理研究员杨传广。 论文标题:Multi-party Collaborative Attention Control for Image Customization论文地址::,生成式人工智能(Generative AI)技术的突破性进展,特别是文本到图像 T2I 生成模型的快速发展,已经使 AI 系统能够根据用户输入的文本提示(prompt)生成高度逼真的图像。 从早期的 DALL・E 到 Stable Diffusion、Midjourney 等模型,这一领域的技术迭代呈现出加速发展的态势。
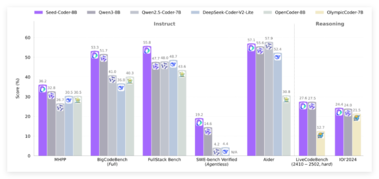
字节跳动发布开源代码模型Seed-Coder,8B参数引领编程新风潮
字节跳动Seed团队正式推出全新开源代码模型Seed-Coder,以其卓越的代码生成、补全、编辑及推理能力引发业界广泛关注。 作为一款8B参数规模的模型,Seed-Coder在多个基准测试中超越同级别竞品,展现出强大的编程潜力和高效的数据处理设计。 模型概览:8B参数,32K上下文,MIT协议开源Seed-Coder是一个专注于代码生成、编程和软件工程任务的模型系列,包含三个主要变体:Seed-Coder-8B-Base:基于模型为中心的代码数据预训练,奠定坚实基础。

MCP 与创新悖论:开放标准为何能拯救 AI
模型上下文协议(MCP)的出现,预示着人工智能应用生态系统即将发生根本性变革。 由 Anthropic 于2024年11月推出的 MCP,旨在规范 AI 应用程序与其训练数据之外的世界进行交互的方式。 正如 HTTP 和 REST 为 Web 应用和服务间的连接奠定了基础,MCP 正在为 AI 模型与各种工具的连接建立统一的标准。

用户提问方式影响AI模型准确性,简洁回答易导致错误信息
近期,法国人工智能研究机构 Giskard 进行了一项关于语言模型的研究,结果表明,当用户要求简短回答时,许多语言模型更可能生成错误或误导性的信息。 该研究使用了多语言的 Phare 基准测试,专注于模型在现实使用环境中的表现,尤其是它们所产生的 “幻想” 现象。 幻想指的是模型产生虚假或误导性内容的情况,而先前的研究显示,这一问题占据了大型语言模型所有记录事件的三分之一以上。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉