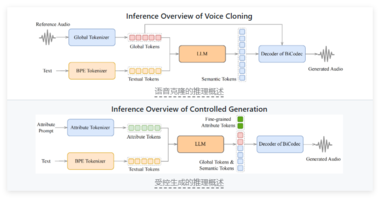
开源语音合成迎来新突破!近日发布的开源 TTS 模型 Muyan-TTS 专为播客、有声书、长视频等场景设计,具备零样本语音合成、极速生成与高连贯性朗读能力,是当前最适合批量化长语音生成的模型之一。
Muyan-TTS 基于超10万小时播客数据预训练,仅需 0.33秒即可生成1秒高质量音频,支持无需打断地朗读数分钟文本,语音自然流畅。更支持说话人定制,任意声音克隆,一键生成具有个性化语气与节奏的语音内容。
模型已开放至 Hugging Face,支持离线部署,开发者可轻松本地推理,适配多样应用场景:播客生成、有声书制作、英文视频配音、AI角色朗读、智能音箱播报等,极大提升内容生产效率。
感兴趣的开发者可前往 Hugging Face 获取模型权重与示例代码,开启你的 AI 语音创作之旅。
GitHub 开源地址:https://github.com/MYZY-AI/Muyan-TTS
HF 模型地址:https://huggingface.co/MYZY-AI/Muyan-TTS