模型

12秒生成1万token!谷歌推出文本「扩散模型」Gemini Diffusion,研究员:演示都得降速看
谷歌又放新大招了,将图像生成常用的“扩散技术”引入语言模型,12秒能生成1万tokens。 什么概念? 不仅比Gemini 2.0 Flash-Lite更快。

ACL 2025 | 大模型乱试错、盲调用?KnowSelf让智能体有「知识边界感知」能力
在 AI 领域,大模型智能体的发展日新月异。 我们今天要介绍的这篇 ACL 2025 论文——《Agentic Knowledgeable Self-awareness》,聚焦于如何提升智能体的「知识边界感知」能力,使其在复杂任务规划中更加得心应手,为智能体的可靠应用提供了新思路。 论文标题:Agentic Knowledgeable Self-awareness论文链接:: 秒速读版本KnowSelf 聚焦于大模型智能体在决策过程中所面临的「知识边界感知」问题。

Mistral 重返开源阵营:发布超高效代码 AI 模型 Devstral 笔记本电脑也能跑
法国人工智能模型制造商 Mistral 在因其最新闭源模型 Medium3受到部分开源社区批评后,迅速回归开源路线。 该公司近日与开源初创公司 All Hands AI(OpenDevin 的创建者)合作,推出了全新的开源语言模型 Devstral。 这款拥有2400万参数的轻量级模型,专为代理 AI 软件开发而设计,其性能甚至在特定基准测试中超越了许多参数高达数十亿的竞争对手,包括一些闭源模型。

OpenAI放大招!核心API支持MCP,一夜改变智能体开发
今天凌晨,OpenAI全资收购io的消息占据了大部分头条。 同时OpenAI也“悄悄地”放出了另外一个重磅消息,用于开发智能体的核心API——Responses API支持MCP服务。 传统方法,我们在开发智能体需要通过函数调用与外部服务交互,每次操作都涉及从大模型到后端再到外部服务的网络传输,导致多次跳转、延迟会很高,并增加扩展和管理的复杂性。

如何基于自定义MCP服务器构建支持工具调用的Llama智能体(含code)
一、背景与目标:从知识隔离到本地化智能体在人工智能应用日益普及的今天,隐私保护与数据主权成为重要挑战。 传统的AI模型依赖外部服务,导致私有知识面临泄露风险。 本文将详细介绍如何构建一个完全本地化的AI智能体,通过自定义的Model Context Protocol(MCP)服务器实现知识隔离,并结合Llama 3.2轻量级模型实现工具调用能力。

谷歌推出 MedGemma AI 模型:医疗图像与文本分析的革命性工具
在刚刚结束的2025年 I/O 开发者大会上,谷歌宣布开源全新医疗 AI 模型 ——MedGemma。 这款基于 Gemma3架构的模型专为医疗领域设计,具备强大的多模态图像和文本理解能力,旨在提升医疗诊断与治疗效率。 MedGemma 提供两种配置选项,分别为4B 和27B 参数模型。

腾讯大模型战略亮相 Turbo S 与 T1 模型全面升级
5月21日,腾讯宣布其混元大模型矩阵全面升级,标志着腾讯在人工智能领域的技术能力持续提升。 此次升级涵盖了多个方面,包括旗舰快思考模型混元TurboS、深度思考模型混元T1的升级,以及基于TurboS基座新推出的视觉深度推理模型T1-Vision和端到端语音通话模型混元Voice。 此外,腾讯还同步更新了混元图像2.0、混元3D v2.5及混元游戏视觉生成等一系列多模态模型。

苹果将开放AI模型给开发者,力求催生创新应用
苹果公司近日宣布,将向第三方开发者开放其人工智能模型,旨在激发新应用的创造力,并提升其设备的吸引力。 知情人士透露,这一计划将在6月9日的全球开发者大会(WWDC)上正式发布。 苹果希望通过提供软件开发工具包(SDK)和相关框架,让开发者能够基于其大型语言模型构建 AI 功能。
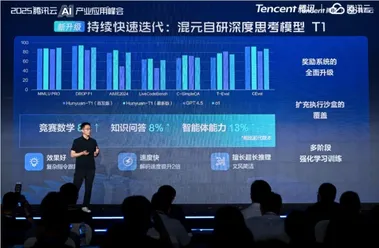
腾讯混元宣布模型矩阵全面升级,新推视觉推理模型T1-Vision和语音通话模型混元Voice
今日,腾讯混元正式宣布其模型矩阵的全面升级,包括 旗舰快思考模型混元TurboS、深度思考模型混元T1升级,并基于TurboS基座,新推出视觉深度推理模型T1-Vision和端到端语音通话模型混元Voice。 另外,腾讯混元图像2.0、腾讯混元3D v2.5及混元游戏视觉生成等一系列多模态模型同步“上新”。 此次升级不仅增强了混元在 AI 领域的竞争力,也标志着腾讯在多模态技术上的新进展。

ChatGPT转型计划曝光!不再只是回答问题,而是通过穿插使用工具变身行动助手
AI Agent今天是初级工程师,6个月后是高级工程师,一年后是架构师。 这是OpenAI CPO Kevin Weil在接受最新访谈时提出的构想。 他表示,ChatGPT将从回答问题转变为为用户做事。

纯靠“脑补”图像,大模型推理准确率狂飙80%丨剑桥谷歌新研究
不再依赖语言,仅凭图像就能完成模型推理? 大模型又双叒叕迎来新SOTA! 当你和大模型一起玩超级玛丽时,复杂环境下你会根据画面在脑海里自动规划步骤,但LLMs还需要先转成文字攻略一格格按照指令移动,效率又低、信息也可能会丢失,那难道就没有一个可以跳过“语言中介”的方法吗?

瘦身不降智!大模型训推效率提升30%,京东大模型开发计算研究登Nature旗下期刊
京东探索研究院关于大模型的最新研究,登上了Nature旗下期刊! 该项研究提出了一种在开放环境场景中训练、更新大模型,并与小模型协同部署的系统与方法。 它通过模型蒸馏、数据治理、训练优化与云边协同四大创新,这个项目将大模型推理效率平均提升30%,训练成本降低70%。

何恺明团队又发新作: MeanFlow单步图像生成SOTA,提升达50%
这段时间,大神何恺明真是接连不断地发布新研究。 这不,5 月 19 日,他又放出一篇新作! 论文标题:Mean Flows for One-step Generative Modeling 论文地址: MeanFlow 的单步生成建模框架,通过引入平均速度(average velocity)的概念来改进现有的流匹配方法,并在 ImageNet 256×256 数据集上取得了显著优于以往单步扩散 / 流模型的结果,FID 分数达到 3.43,且无需预训练、蒸馏或课程学习。

策略学习助力LLM推理效率:MIT与谷歌团队提出异步并行生成新范式
金天,麻省理工学院(MIT)计算机科学与人工智能实验室(CSAIL)博士五年级学生,师从 Michael Carbin 和 Jonathan Ragan-Kelley。 他主要研究机器学习与编程系统的结合。 此前曾在 IBM Research 主导实现深度神经网络在 IBM 主机上的推理部署。

FaceAge登上「柳叶刀」!AI一张照片看穿你的真实年龄
你有没有发现,有些人看起来就是比其他人更老。 脸,不仅仅是我们的门面,还是一个人的「健康快照」,更是一张映射身体状态的「体检报告」。 最近的一项研究发现这其中还藏着更深的秘密,这项研究登上《柳叶刀数字健康》:Mass General Brigham团队用AI训练出一个模型FaceAge,从人脸照片里预测癌症患者的真实「生物年龄」以提供建议辅助治疗。

字节跳动开源多模态模型 BAGEL:图文生成与编辑的新突破
字节跳动 发布了一款名为 BAGEL 的开源多模态基础模型,拥有70亿个活跃参数,整体参数量达到140亿。 BAGEL 在标准多模态理解基准测试中表现出色,超越了当前一些顶级开源视觉语言模型,如 Qwen2.5-VL 和 InternVL-2.5。 此外,在文本到图像的生成质量上,BAGEL 的表现也与强大的专业生成器 SD3相媲美。
豆包·语音播客模型发布 将在豆包APP及PC端、扣子等上线
火山引擎正式推出豆包·语音播客模型,豆包·语音播客模型基于流式模型构建,能够实现从文本创作到双人对话式播客的秒级转化,为用户带来“低成本、高时效、强互动”的全新创作体验。 这一模型的推出,不仅解决了传统AI播客创作中的诸多痛点,还极大地简化了播客制作流程,让热点内容能够瞬间转化为生动的播客。 在当今信息爆炸的时代,播客作为一种受欢迎的内容传播形式,正吸引着越来越多的用户。

谷歌Gemma 3n发布!可在手机上流畅跑多模态AI,音频+图像+文本全能
谷歌在I/O2025大会上正式揭晓Gemma3n,一款专为低资源设备设计的多模态AI模型,仅需2GB RAM即可在手机、平板和笔记本电脑上流畅运行。 Gemma3n继承了Gemini Nano的架构,新增音频理解功能,支持文本、图像、视频和音频的实时处理,且无需云端连接,彻底颠覆了移动端AI体验。 AIbase综合最新社交媒体动态,深入解析Gemma3n的技术亮点及其对AI生态的影响。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉