不再依赖语言,仅凭图像就能完成模型推理?
大模型又双叒叕迎来新SOTA!
当你和大模型一起玩超级玛丽时,复杂环境下你会根据画面在脑海里自动规划步骤,但LLMs还需要先转成文字攻略一格格按照指令移动,效率又低、信息也可能会丢失,那难道就没有一个可以跳过“语言中介”的方法吗?


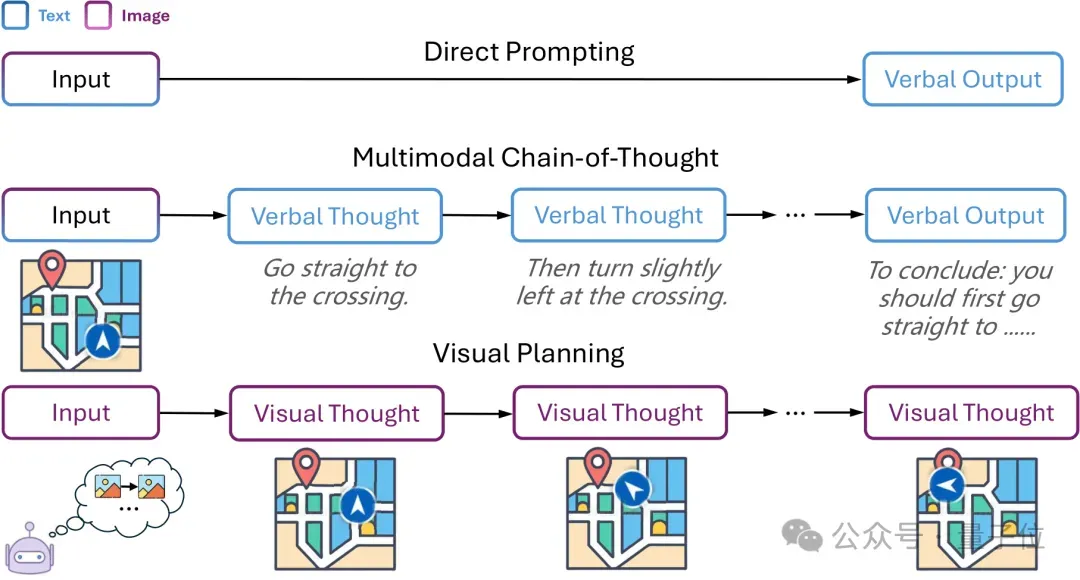
于是来自剑桥、伦敦大学学院和谷歌的研究团队推出了首次纯粹依靠图像进行推理的新范式——基于强化学习的视觉规划(VPRL)。
新框架利用GRPO对大型视觉模型进行后训练,在多个代表性视觉导航任务中的性能表现都远超基于文本的推理方法。
准确率高达80%,性能超文本推理至少40%,首次验证了视觉规划显著优于文本规划,为直觉式图像推理任务开辟了新方向。
目前相关代码已开源,可点击文末链接获取。

以下是有关VPRL的更多细节。
VPRL更准确、更有效
现有的视觉推理基准都是将视觉信息映射到文本领域进行处理,整个推理过程都由语言模型完成。
纯视觉规划则是让模型直接利用图像序列,没有中间商“赚差价”,推理效率直线UP。
由此团队直接引入一个基于强化学习的视觉规划训练框架VPRL,基于群组相对策略优化(GRPO),利用视觉状态之间的转换来计算奖励信号,同时验证环境约束。
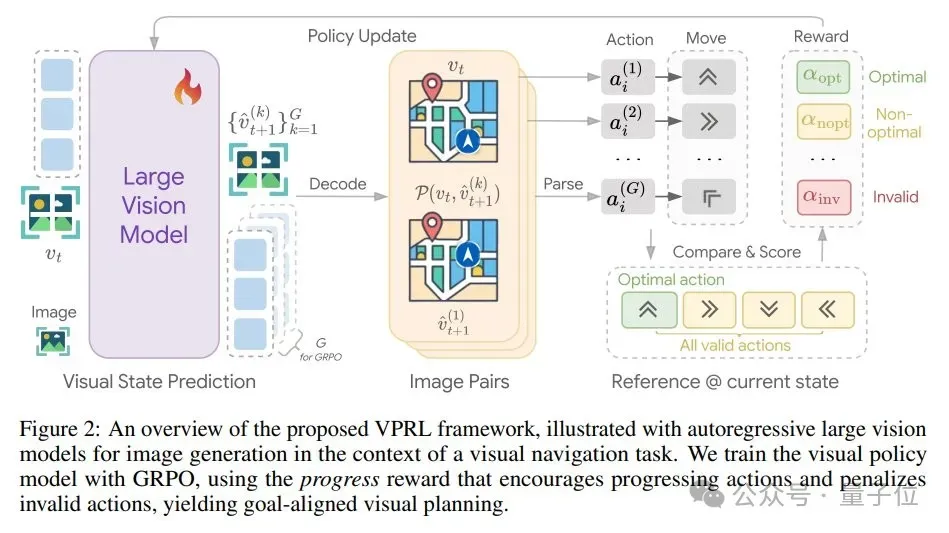
该框架可以分为两个阶段:
- 策略初始化
通过环境中的随机游走轨迹初始化模型,再对每条轨迹提取图像对,并给定输入前缀,此外通过最小化监督损失以鼓励生成连贯的视觉输出:
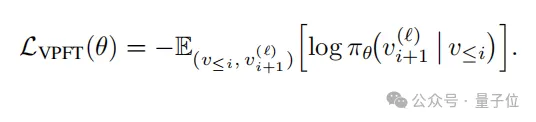
- 强化学习优化
利用模型在随机轨迹初始化后已具备的探索能力,通过生成下一视觉状态模拟潜在动作结果,并引导模型执行有效规划。
具体来说,就是基于GRPO计算组内相对优势,每个候选的相对优势为:
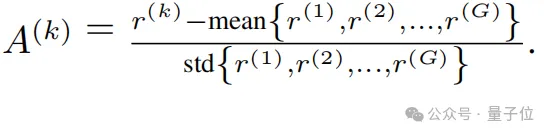
同时为引导模型生成更高优势的响应,通过最大化以下目标函数更新策略模型:
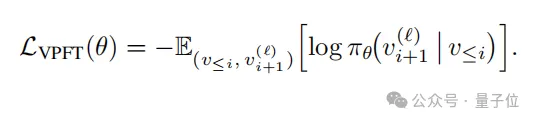
在视觉规划框架中,核心挑战始终在于生成的视觉状态能否正确反映规划动作的意图,因此需要通过奖励函数评估动作有效性(奖励进展动作、零奖励非进展动作、惩罚无效动作),进度奖励函数定义为:

除了VPRL,研究团队还选用了几种系统变体作为基线,分别是基于微调的视觉规划 (VPFT)和文本中的监督微调 (SFT),以比较基于语言和基于视觉的规划,同时评估强化学习的作用。
VPFT与VPRL在第一阶段训练架构一致,但用最佳规划轨迹取代随机轨迹;而SFT用一个预期动作序列的文本描述取代中间视觉结果。
视觉规划vs语言规划
实验搭建
为了更直观地比较两种规划效果,团队选取了三个可以完全以视觉方式表达和执行的代表性任务:
- FrozenLake智能体需从起点安全导航至终点,过程中需要避开冰洞。
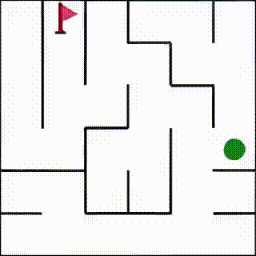
- Maze智能体需从起点(绿点)导航至终点(红旗)。
- MiniBehavior智能体需拾取打印机并放置到桌上,包含“拾取”和“放置”两个附加动作。
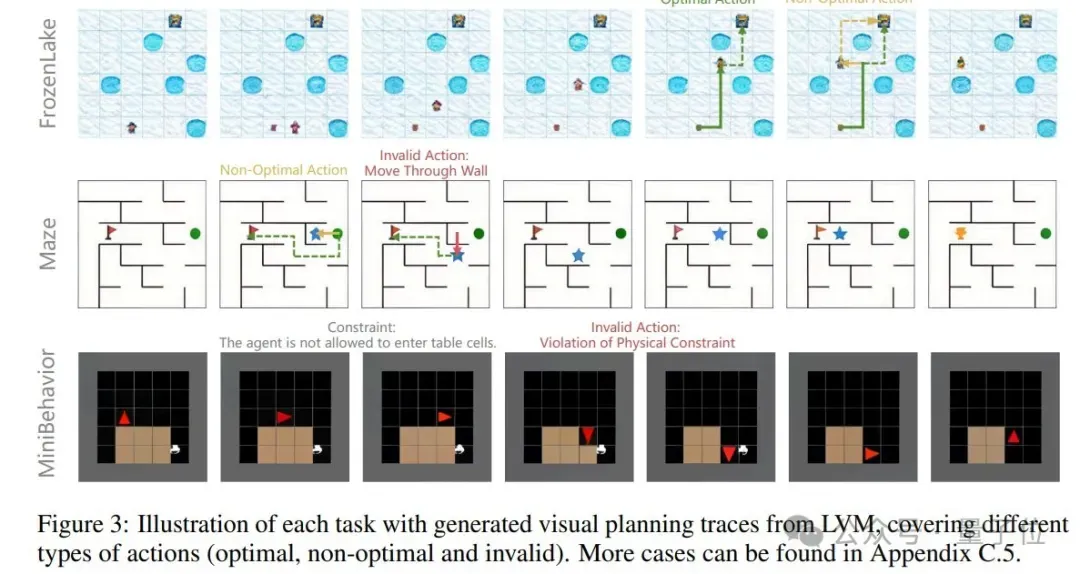
在模型的选取上,选择专门在视觉数据上训练的模型LVM-3B,确保预训练期间不接触任何文本数据。
另外评估比较Qwen 2.5VL-Instruct在仅推理(Direct2和CoT)和训练后设置(SFT)两种模式下的文本规划效果,以及将Gemini 2.0 Flash和Gemini 2.5 Pro作为多模态推理的参考模型。
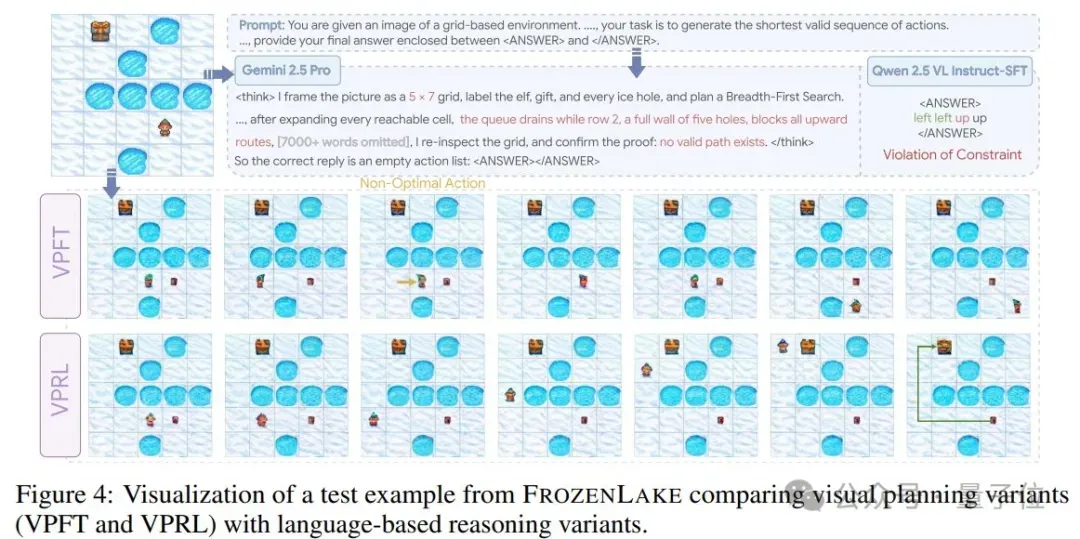
评估指标采用精确匹配率(EM)和进展率(PR),前者衡量模型是否成功生成与最优路径一致的完整规划轨迹,后者则测量从开始到最优路径的连续正确步数与总步数的比率。
实验结果
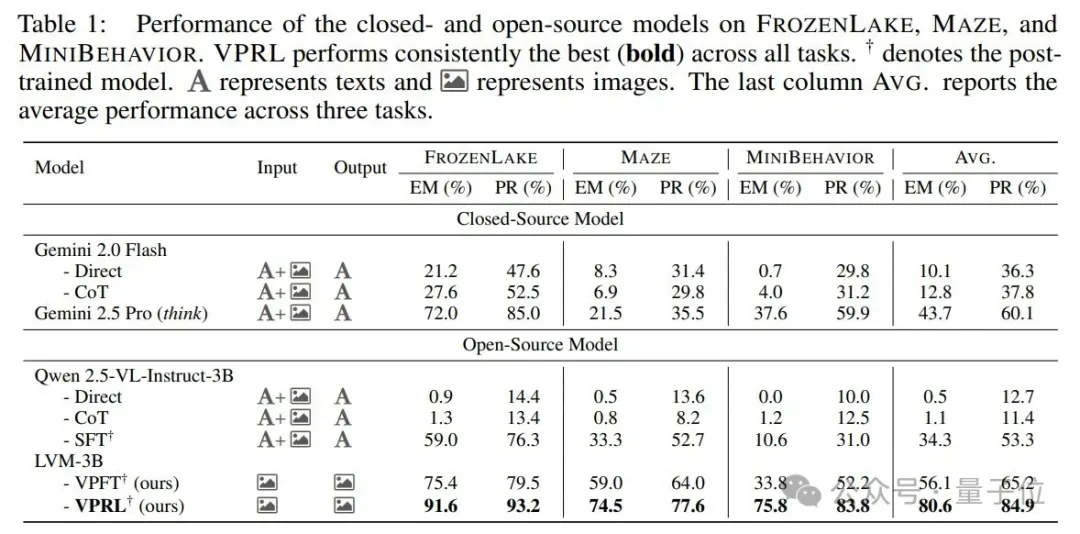
实验结果表明,视觉规划显著优于文本规划。
视觉规划(VPFT和VPRL)在所有任务上都取得了最高分,如表所示,VPRL在三个任务中平均EM高达80.6%,远超文本基线(如Gemini 2.5 Pro平均EM为43.7%)。
在强化学习的增益上,VPRL也相比监督基线VPFT提升超20%,尤其是在复杂任务MiniBehavior中EM更是高达75.8%。
说明通过奖励驱动,可以帮助模型自由探索不同行动并从结果中学习,从而有效提高规划性能。
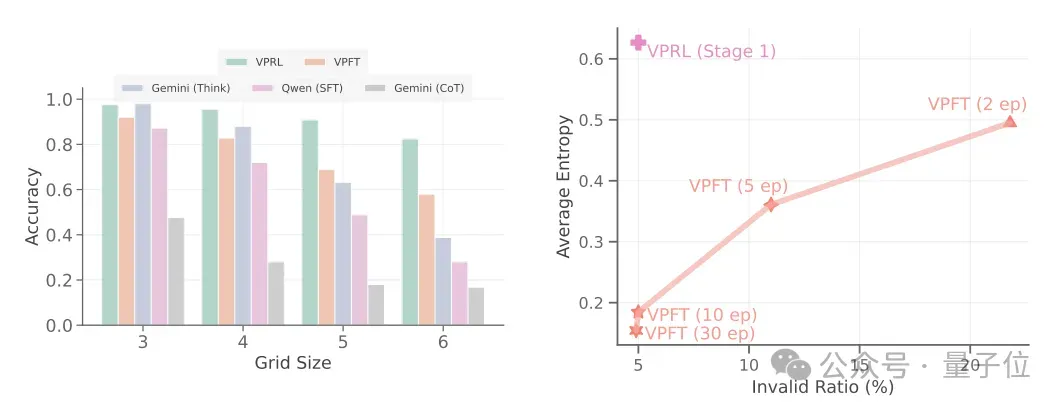
与此同时在鲁棒性上,随着网格尺寸增大(如FrozenLake从3×3到6×6),VPRL性能下降平缓(EM从97.6%降至82.4%),而Gemini 2.5 Pro从98.0%骤降至38.8%,充分体现了VPRL更强的稳定性。
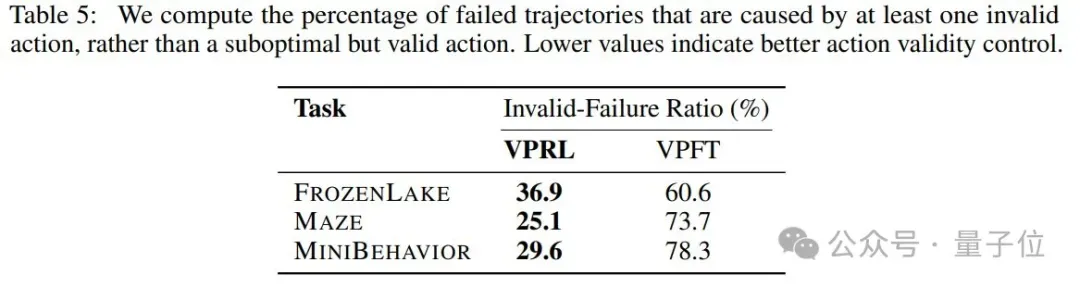
与VPFT相比,VPRL也将无效失败率降低了24%,从而帮助模型保持在有效的动作空间内。
综上,实验结果首次验证了纯视觉推理的可行性,通过研究团队提出的新范式VPRL框架,可以在视觉导航任务中实现超越文本模型的推理性能,并展现出极强的泛化能力,推动多模态推理在未来朝着更直观的图像化方向发展。
值得一提的是,团队成员长期致力于视觉推理研究,他们也曾研究通过多模态思维可视化(MVoT)生成视觉“思想”,以彻底改变AI推理方式,感兴趣的小伙伴们可以持续关注团队的研究进展~

论文链接:https://arxiv.org/abs/2505.11409
代码链接:https://github.com/yix8/VisualPlanning


