这段时间,大神何恺明真是接连不断地发布新研究。
这不,5 月 19 日,他又放出一篇新作!作者团队来自 CMU 以及 MIT。

- 论文标题:Mean Flows for One-step Generative Modeling
- 论文地址:https://arxiv.org/pdf/2505.13447v1
文章提出了一种名为 MeanFlow 的单步生成建模框架,通过引入平均速度(average velocity)的概念来改进现有的流匹配方法,并在 ImageNet 256×256 数据集上取得了显著优于以往单步扩散 / 流模型的结果,FID 分数达到 3.43,且无需预训练、蒸馏或课程学习。
生成模型旨在将先验分布转换为数据分布。流匹配提供了一个直观且概念简单的框架,用于构建将一个分布传输到另一个分布的流路径。流匹配与扩散模型密切相关,但关注的是引导模型训练的速度场。自引入以来,流匹配已在现代生成模型中得到广泛应用。
本文提出了一种名为 MeanFlow 的理论框架,用于实现单步生成任务。其核心思想是引入一个新的 ground-truth 场来表示平均速度,而不是流匹配中常用的瞬时速度。
文章提出使用平均速度(在时间间隔内的位移与时间的比值)来代替流匹配中通常建模的瞬时速度。然后本文推导出平均速度与瞬时速度之间存在一个内在的关系,从而作为指导网络训练的原则性基础。
基于这一基本概念,本文训练了一个神经网络来直接建模平均速度场,并引入损失函数来奖励网络满足平均速度和瞬时速度之间的内在关系。
本文进一步证明,该框架可以自然地整合无分类器引导(CFG),并且在采样时无需额外成本。
MeanFlow 在单步生成建模中表现出了强大的性能。在 ImageNet 256×256 数据集上,仅使用 1-NFE(Number of Function Evaluations)就达到了 3.43 的 FID 分数。这一结果显著优于之前同类方法的最佳水平,相对性能提升达到 50% 到 70%(见图 1)。
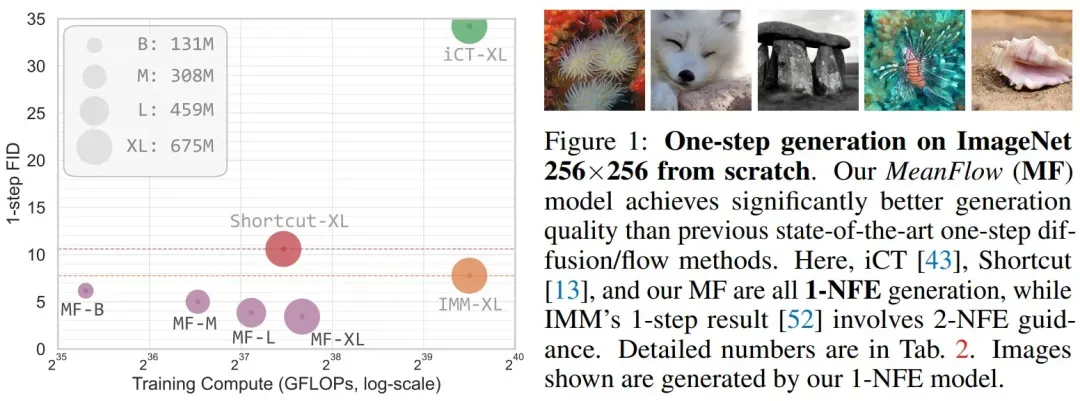
此外,MeanFlow 是一个自成一体的生成模型:它完全从头开始训练,没有任何预训练、知识蒸馏或课程学习。该研究大幅缩小了单步扩散 / 流模型与多步研究之间的差距。
方法介绍
MeanFlow 核心思想是引入一个代表平均速度的新场。
平均速度 u 可表示为:
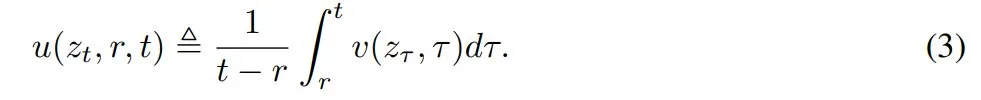
其中,u 表示平均速度,v 表示瞬时速度。u (z_t,r,t) 是一个同时依赖于 (r, t) 的场。u 的场如图 3 所示:

平均速度 u 是瞬时速度 v 的函数,即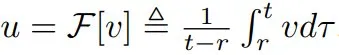 ,它是由 v 诱导的场,不依赖于任何神经网络。
,它是由 v 诱导的场,不依赖于任何神经网络。
进一步的,为了得到适合训练的公式,本文将 Eq.(3) 改写为:
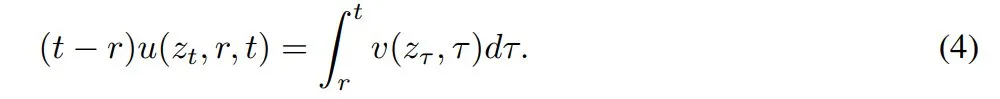
然后两边对 t 求导,把 r 看作与 t 无关的变量,得到:
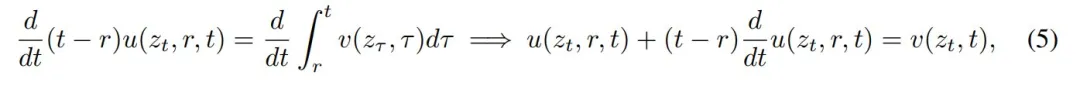
其中左侧的运算采用乘积法则,右侧的运算采用微积分。重新排列项,得到恒等式:
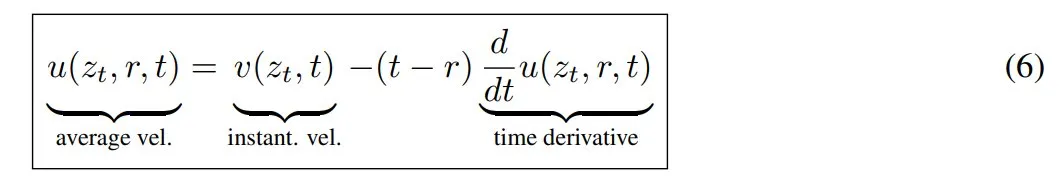
这个方程称为 MeanFlow 恒等式,它描述了 v 和 u 之间的关系。
图 1 给出了最小化损失函数的伪代码。

单步采样

实验效果如何?
实验是在 256×256 ImageNet 数据集上进行的。
图 1 中,本文将 MeanFlow 与之前的单步扩散 / 流模型进行了比较,如表 2(左)所示。总体而言,MeanFlow 的表现远超同类:它实现了 3.43 的 FID,与 IMM 的单步结果 7.77 相比,相对提升了 50% 以上。
如果仅比较 1-NFE(而不仅仅是单步)生成,MeanFlow 与之前的最佳方法(10.60)相比,相对提升了近 70%。不难看出,本文方法在很大程度上缩小了单步和多步扩散 / 流模型之间的差距。
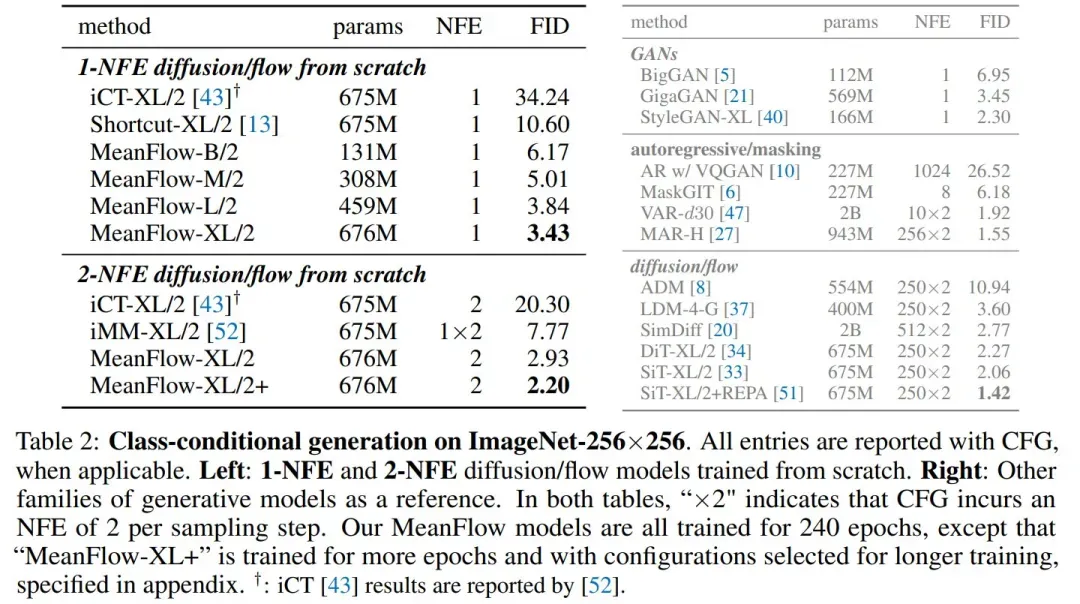
在 2-NFE 生成中,MeanFlow 实现了 2.20 的 FID(表 2 左下)。这一结果与多步扩散 / 流模型的领先基线模型相当,即 DiT (FID 2.27)和 SiT (FID 2.15),两者的 NFE 均为 250×2(表 2 右)。
这一结果表明,few-step 扩散 / 流模型可以媲美其多步模型。值得注意的是,本文方法是独立的,完全从头开始训练。它无需使用任何预训练、蒸馏或课程学习,就取得了出色的结果。
表 3 报告了在 CIFAR-10(32×32)上的无条件生成结果,本文方法与先前的方法相比具有竞争力。
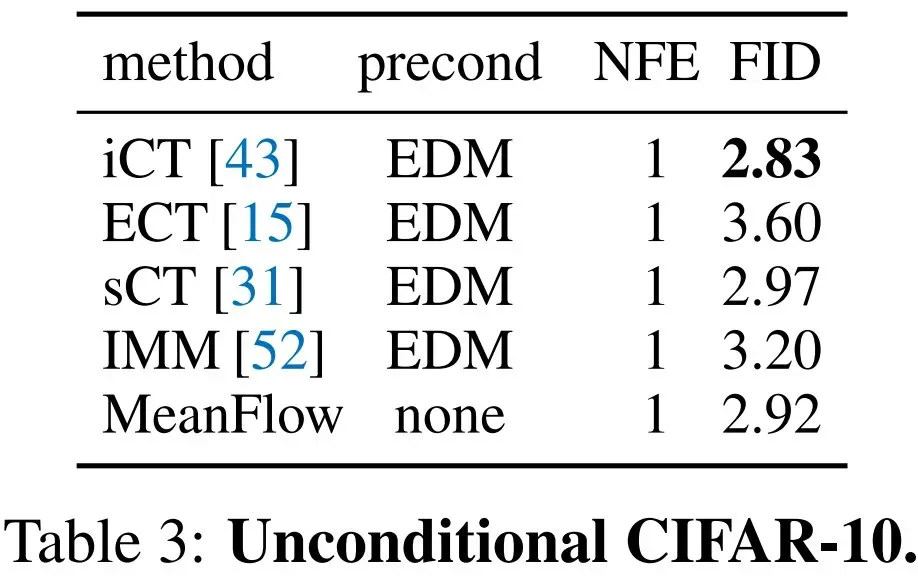
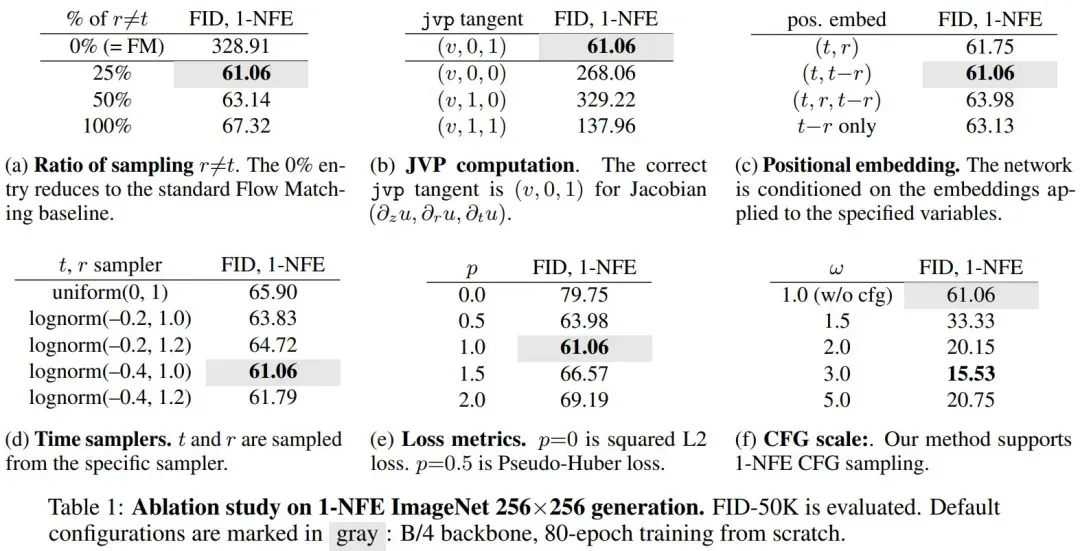
表 1 为消融实验结果:
最后,展示一些 1-NFE 的生成结果。

更多详情请参阅原论文。


