模型

Mistral 推出新开源模型 Devstral:在笔记本上也能挑战 GPT-4.1-mini
法国初创公司 Mistral 再次引发关注,他们与开源团队 All Hands AI 合作推出了全新语言模型 Devstral。 这一模型不仅拥有240亿个参数,而且所需的计算资源显著低于许多同类产品,使其成为本地部署及设备端使用的理想选择。 对于那些拥有 RTX4090显卡或32GB 内存的用户而言,Devstral 可以轻松运行,带来了更加灵活的使用体验。

谷歌黑科技炸场!LightLab:只需一张图+AI,光影编辑像呼吸一样简单,废片秒变电影级大片!
在之前的文章中以及和大家介绍过需要关于图像&视频重打光的方法,在今天的推送文章中,已经帮大家重新整理好了,欢迎大家点击阅读~今天给大家介绍谷歌提出的一种基于扩散模型的方法LightLab,可以实现对单张图像中光源的细粒度、参数化控制。 该方法能够调整可见光源的强度和颜色、环境光照的强度,并可在场景中插入虚拟光源。 LightLab方法能够对图像中的光源进行显式的参数化控制,同时生成物理上合理的阴影和环境光效应。

字节开源高精度文档解析大模型Dolphin:轻量高效,性能超GPT4.1、Mistral-OCR!
字节跳动刚刚开源一款全新文档解析模型——Dolphin。 与目前市面上各类大模型相比,这款轻量级模型不仅体积小、速度快,并且取得了令人惊艳的性能突破,解析效率提升近2倍。 测试结果显示,Dolphin在文档解析任务上解析准确率超越了GPT-4.1、Claude3.5-Sonnet、Gemini2.5-pro、Qwen2.5-VL等通用多模态大模型,以及最近推出的号称最强OCR大模型的Mistral-OCR等垂类大模型。
Claude4来袭!Anthropic推出"业界最强"AI模型,编程能力全面超越竞争对手
在首届开发者大会上,Anthropic推出了两款声称"业界最强"的AI模型,加剧了与OpenAI和谷歌的竞争Anthropic在周四举行的首届开发者大会上正式发布Claude4模型系列,包括Claude Opus4和Claude Sonnet4两款新模型。 该公司声称这些模型在多项流行基准测试中达到业界领先水平,专门针对编程任务进行了优化。 产品特性与定价策略新发布的Claude4系列具备分析大型数据集、执行长期任务和处理复杂操作的能力。
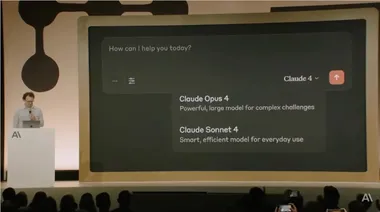
太卷了!Anthropic发布Claude 4 编程和推理能力秒杀Gemini2.5pro
最近,人工智能界传来重大消息,Anthropic 正式推出了其 Claude4系列模型,包括 Claude Opus4和 Claude Sonnet4。 这次发布并没有华丽的口号或冗长的论文,关键词只有一个 ——“干活”。 根据 Anthropic 的说法,Claude Opus4被誉为全球最强的编程模型,能够稳定处理复杂且长期的任务,表现出色。

小学数学题,大模型集体不及格!达摩院推出新基准VCBench
大模型做数学题的能力很强,可是它们真的能够理解基本的数学原理吗? 拿小学生的数学题进行测试,人类平均得分为93.30%,而大模型的表现让人意外:闭源模型中Gemini2.0-Flash(49.77%)、Qwen-VL-Max(47.03%)、Claude-3.7-Sonnet(46.63%)的综合表现最佳,但仍未突破50%准确率。 因为大模型可能并不能真正理解基本数学元素和视觉概念。

最强编码模型Claude 4!7小时不间断写代码,连玩24小时宝可梦,GitHub已选为Copilot底层模型
AI圈子好热闹。 今天凌晨,Claude终于迎来了它的重大版本升级——Claude 4来了! 此次主要发布的有两个模型:Claude Opus 4和Claude Sonnet 4。
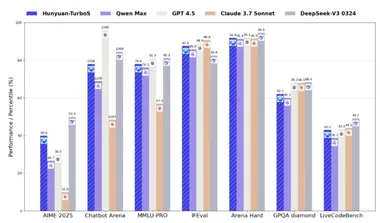
腾讯混元 TurboS 技术报告全面揭秘,560B参数混合Mamba架构
腾讯发布了混元 TurboS 技术报告,揭示了其旗舰大语言模型 TurboS 的核心创新与强大能力。 根据全球权威大模型评测平台 Chatbot Arena 的最新排名,混元 TurboS 在239个参赛模型中位列第七,成为国内仅次于 Deepseek 的顶尖模型,并在国际上仅落后于谷歌、OpenAI 及 xAI 等几家机构。 混元 TurboS 模型的架构采用了创新的 Hybrid Transformer-Mamba 结构,这种新颖的设计结合了 Mamba 架构在处理长序列上的高效性与 Transformer 架构在上下文理解上的优势,从而实现了性能与效率的平衡。

Mistral发布全新开源AI编程模型Devstral,轻松运行于单张显卡
近日,总部位于法国巴黎的 Mistral AI 公司联合 All Hands AI 推出了一款专为软件开发设计的开源 AI 模型 ——Devstral。 这款模型具有高达240亿的参数量,目前处于 “研究预览” 阶段,并以 Apache2.0开源许可发布,允许开发者和企业在商业用途上无所顾忌地使用。 Devstral 的发布标志着 AI 在编程领域中的一大步进,Mistral AI 在其官方博客中指出,该模型推动了 “agentic” 编码的发展。

阿联酋推出阿拉伯语专用 AI 大模型,助力轻量化应用发展
在全球人工智能技术迅猛发展的背景下,阿布扎比技术创新研究院(TII)近日在 “阿联酋制造” 大会上,隆重发布了两款全新的人工智能大模型 ——Falcon Arabic 和 Falcon H1。 这两款模型分别针对阿拉伯语环境及低算力应用需求,旨在为当地市场提供更多定制化的 AI 解决方案。 Falcon 系列的命名灵感来自于 “猎鹰”,该系列模型最早于2023年发布,并迅速在开源社区引发关注。

Meta推出J1系列模型,最强“AI法官”上线
近日,Meta 公司发布了其全新 J1系列模型,这是一项旨在提升 AI 判断能力的创新技术。 通过结合强化学习和合成数据的训练方法,J1模型不仅在判断的准确性上取得显著进步,还在公平性方面表现出色。 此次发布的消息由科技媒体 marktechpost 报道,令人瞩目。

红帽发布全新 AI 推理服务器,推动混合云环境下智能化发展
红帽公司近期正式推出了红帽 AI 推理服务器(Red Hat AI Inference Server),这款服务器旨在为混合云环境提供更加高效和经济的 AI 推理服务。 通过采用先进的 vLLM 技术,并结合 Neural Magic 的创新能力,红帽希望为用户带来更快的响应速度和更优越的性能。 红帽 AI 推理服务器是一款专为高性能设计的开放推理解决方案,配备了一系列先进的模型压缩与优化工具。

Meta 推出 “Llama 创业计划”,支持初创企业使用 AI 模型
Meta 公司近日宣布推出一项名为 “Llama 创业计划” 的新项目,旨在鼓励初创企业采用其 Llama AI 模型。 该计划为参与公司提供 “直接支持”,并在某些情况下提供资金支持。 任何在美国注册、融资少于1000万美元、拥有至少一名开发人员并正在开发生成式 AI 应用的公司,均可在5月30日前申请参与。

多模态大模型MMaDA:让AI学会「跨次元思考」,文本图像通吃的全能型选手来了!
最近,普林斯顿大学、字节跳动、清华大学和北京大学联手搞了个大事情,推出了一款名为 MMaDA 的多模态大模型! 这可不是普通的 AI,它号称能让 AI 拥有“深度思考”的能力,还能在文本、图像、甚至复杂的推理任务之间“七十二变”,表现力直接超越了你熟悉的 GPT-4、Gemini、甚至 SDXL!你可能觉得,现在的多模态模型已经很厉害了,能看图说话,也能根据文字生成图片。 但 MMaDA 告诉我们:这还远远不够!

24B模型编程超DeepSeek全家桶,32G内存苹果电脑就能跑,专门针对真实GitHub Issue训练
Mistral沉默好久,果然在憋大招。 刚刚发布最新开源编程模型Devstral,在软件工程任务上一举超过DeepSeek全家桶和Qwen3 235B。 并且参数只有24B,可以在单卡RTX4090甚至32G内存的Mac上运行。

帮大模型提速80%,华为拿出昇腾推理杀手锏FlashComm,三招搞定通算瓶颈
在今年 2 月的 DeepSeek 开源周中,大模型推理过程中并行策略和通信效率的深度优化成为重点之一。 近日,华为数学家出手,祭出 FlashComm,三箭齐发,解决大模型推理通算难题:FlashComm1: 大模型推理中的 AllReduce 通信优化技术。 将 AllReduce 基于通信原理进行拆解,并结合后续计算模块进行协同优化,推理性能提升 26%。
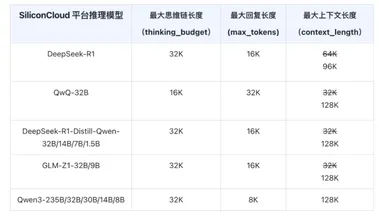
硅基流动升级DeepSeek-R1 等推理模型API ,支持 128K 上下文长度
硅基流动(SiliconCloud)宣布对其 DeepSeek-R1等推理模型 API 进行了一次重要升级,旨在更好地满足开发者对长上下文和灵活参数配置的需求。 此次升级中,多个推理模型的最大上下文长度被提升至128K,使得模型在思考时能够更加充分,输出内容也更为完整。 在此次升级中,多个知名模型,如 Qwen3、QWQ、GLM-Z1等,均支持128K 的最大上下文长度,而 DeepSeek-R1则支持96K。

微软支持的 AI 模型颠覆飓风预测,速度与成本双双优于传统方法
近日,科学家开发出了一种名为 “Aurora” 的机器学习模型,它在热带气旋轨迹预测方面表现优于官方机构,并且速度更快、成本更低。 Aurora 是由微软、宾夕法尼亚大学及其他机构的研究人员共同研发的基础模型,旨在提升地球系统预测的速度和准确性,涵盖空气质量、海洋波动、热带气旋轨迹以及高分辨率天气等领域。 图源备注:图片由AI生成,图片授权服务商MidjourneyAurora 的联合作者、宾夕法尼亚大学机械工程及应用力学副教授巴黎・佩尔迪卡里斯(Paris Perdikaris)表示,Aurora 类似于大型神经网络,能够从过去的地球物理数据中学习,预测复杂的物理过程,而不再依赖传统的物理方程。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉