大模型做数学题的能力很强,可是它们真的能够理解基本的数学原理吗?
拿小学生的数学题进行测试,人类平均得分为93.30%,而大模型的表现让人意外:
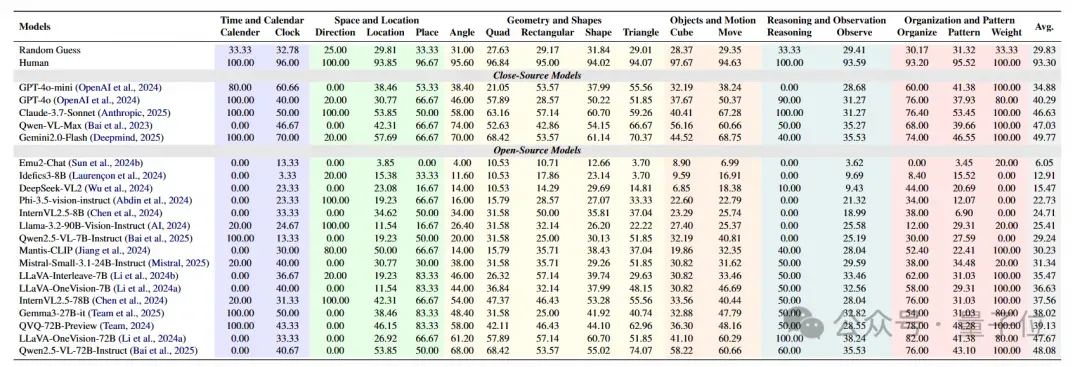
闭源模型中Gemini2.0-Flash(49.77%)、Qwen-VL-Max(47.03%)、Claude-3.7-Sonnet(46.63%)的综合表现最佳,但仍未突破50%准确率。
why?
因为大模型可能并不能真正理解基本数学元素和视觉概念。
现有的视觉数学基准测试主要集中在知识导向的评估上,容易受到大型语言模型中预先嵌入的知识的影响。
上述结论来自达摩院推出的新基准VCBench——这是一个专为评估具备显式视觉依赖性的多模态数学推理任务而设计的综合基准。
该基准主要面向小学 1-6 年级的数学问题,即并不涉及复杂的数学或几何推理,但高度依赖于显式的视觉依赖性的问题。
解决这种问题,需要模型识别和整合图像中的视觉特征,并理解不同视觉元素之间的关系。

△论文标题:Benchmarking Multimodal Mathematical Reasoning with Explicit Visual Dependency
VCBench现已全面开源,代码可见文末。
强调vision-centric而非knowledge-centric
与以往侧重知识评估的基准不同,VCBench更强调视觉为核心的评测。
它主要针对无需专业知识、而是依赖于对数学图像和概念的常见感知推理的问题。
这种方法与儿童的学习路径相符——他们首先掌握的是视觉推理能力,随后才逐步获取领域特定的知识。
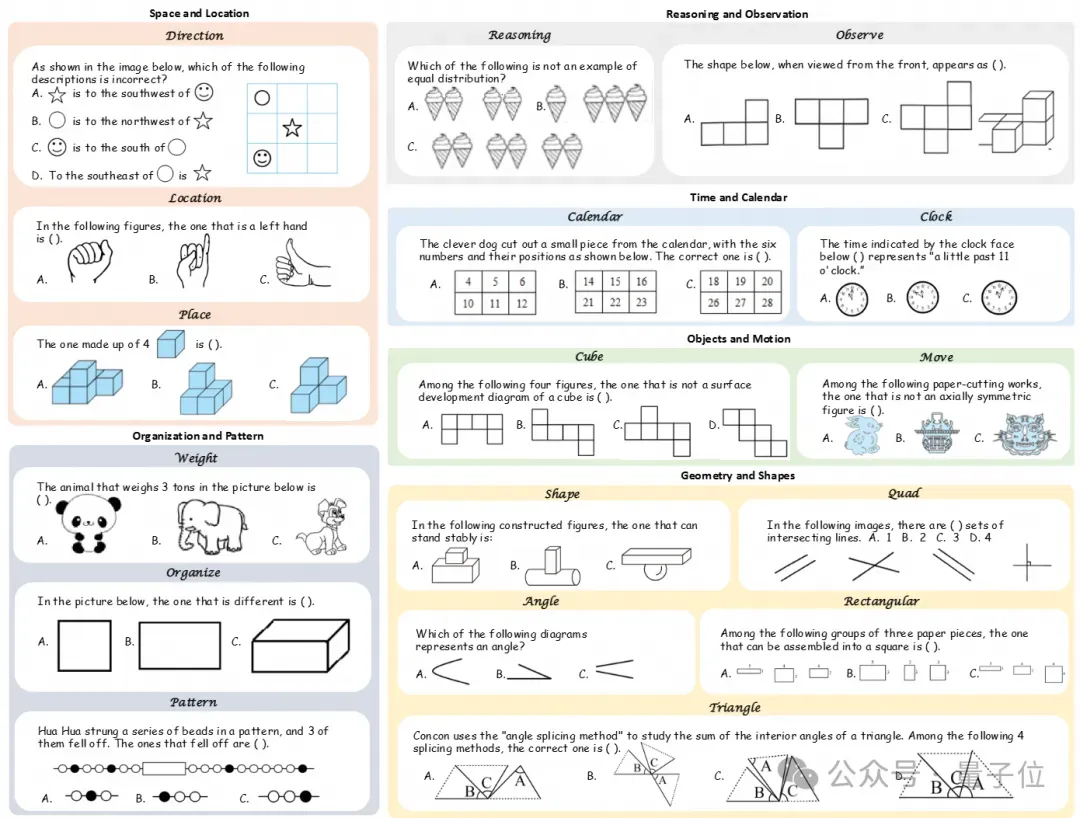
聚焦多图推理
VCBench聚焦于多图(interleave)的问题输入形式,每个问题平均包含3.9张图像,显著高于现有的多图Benchmark。
这种设计要求模型能够显式地整合来自多幅图像的视觉线索,并推理这些元素如何相互作用,这更符合现实世界中的情境——信息往往分散在多个视觉输入之中。
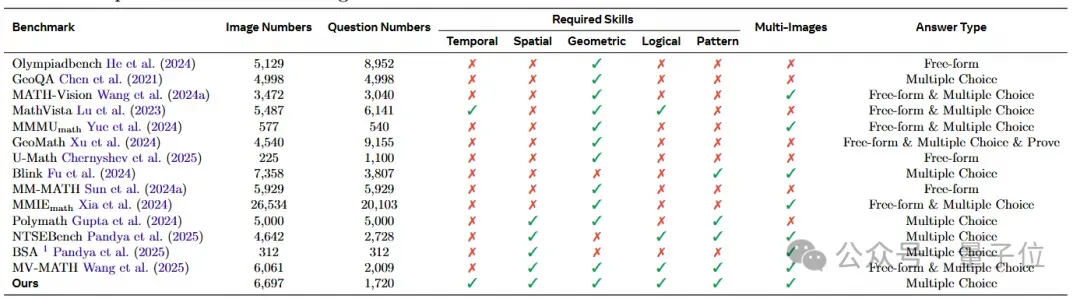
全面评估纯视觉推理的多种能力
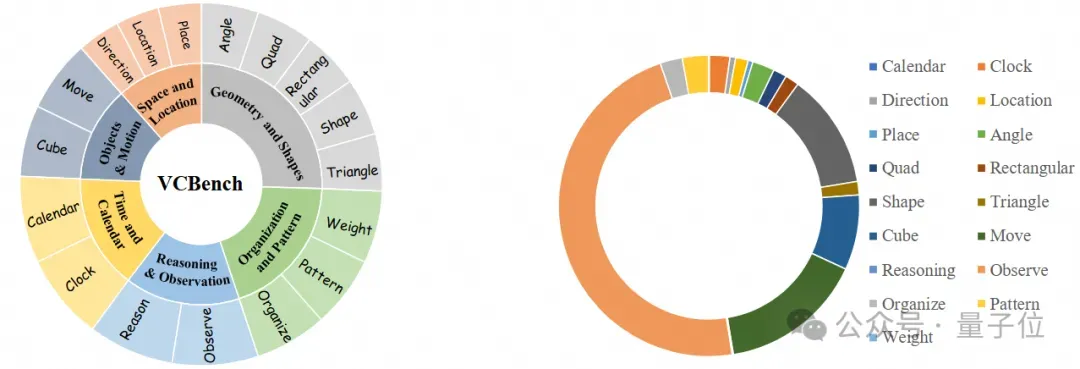
VCBench全面地评估了纯视觉推理的多种能力,涵盖了六大核心认知领域:时间与日历、空间与位置感、几何与形状、物体与运动、推理与观察以及组织与模式。
此外,它还评估了五种不同的认知能力:时间推理、几何推理、逻辑推理、空间推理以及模式识别。
综合实验分析结果
在VCBench的综合实验测试中,人类平均得分93.30%,显著优于所有AI模型,表明当前任务对人类而言可解,但对AI系统仍具挑战性;
闭源模型中Gemini2.0-Flash(49.77%)、Qwen-VL-Max(47.03%)、Claude-3.7-Sonnet(46.63%)表现最佳,但仍未突破50%准确率;
开源模型表现整体趋势低于闭源模型,且表现参差不齐,可能与架构差异、多模态整合程度或训练数据质量有关;
大模型在推理、找规律一类问题上表现较好,但在空间几何表现很差,说明在由小学数学题构建的评测基准中,大模型的逻辑推理能力是过剩的,但是视觉和几何感知则严重不足。
单图实验对照结果
VCBench的一个核心目标是评估模型多图像依赖的推理能力,但为了验证模型是否真正具备跨图像组合推理(compositional reasoning)而非依赖单图优化,需引入单图实验作为对照。
如下图所示,将文字和图片整合成一张大图。
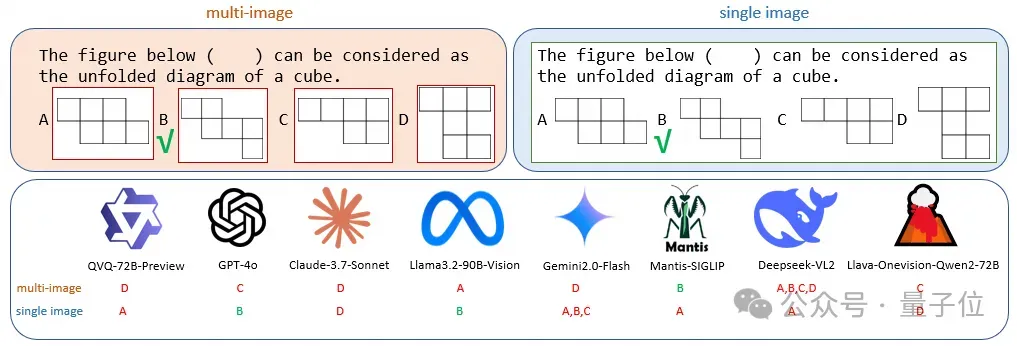
单图和多图结果对比表明,除专为多图设计的模型外,大多数模型在单图场景下表现显著优于多图(平均提升42.3%)。
例如,Emu2-Chat单图性能飙升281.5%,Qwen-VL-Max提升21.3%,说明常规模型更擅长从孤立图像提取信息,但缺乏跨图像关联和时序推理等关键能力。
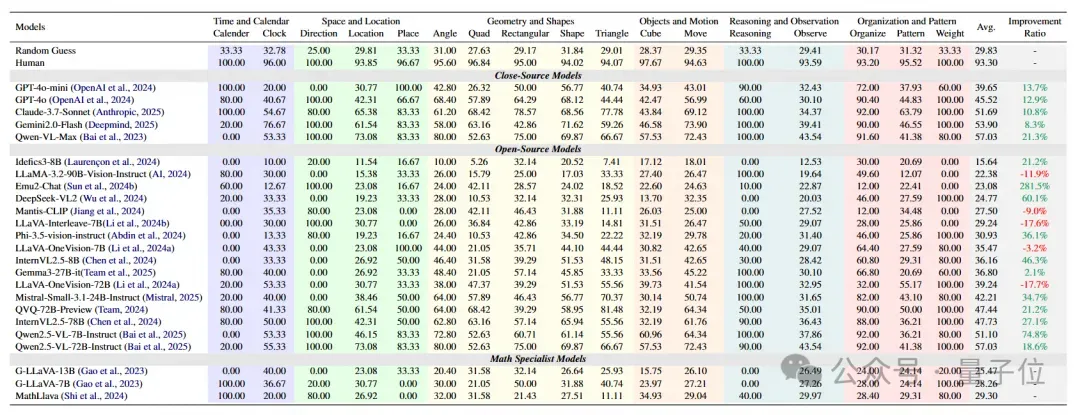
思维链(CoT)对模型性能的影响分析
VCBench团队在三个闭源模型上对比了加入CoT以后对模型性能的影响,得到如下结论:
1、在需要多步逻辑推理的任务中(如模式识别、几何推理),CoT能带来显著性能提升(如Qwen-VL-Max在reasoning任务上提升40%),说明通过显式分解推理步骤,帮助模型更好地整合视觉和语言信息,减少逻辑跳跃错误。
2、效果具有任务依赖性:对感知型任务(如日历读取、方向判断)效果有限甚至产生干扰。这类任务更依赖直接视觉感知而非分步推理,CoT的中间步骤反而可能降低效率。

错误类型分布分析
错误类型可分为以下5种:
- 1.视觉感知错误:模型对视觉内容的误读或未能准确感知;
- 2.计算错误:算术计算过程中的失误;
- 3.上下文误读:模型错误解读文本内容;
- 4.逻辑错误:推理过程中的出错;
- 5.答案整合错误:未能直接回答问题或提供多个相互冲突的答案。
VCBench团队对四个顶尖模型的所有错题进行了手动错误分类,从而能够精准识别每个模型在不同错误类别中的相对弱点。
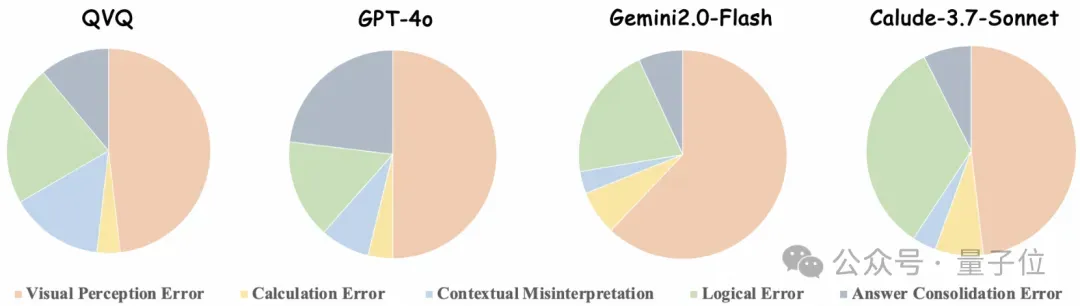
通过分析,得到了如下结论:
1、视觉感知错误在所有模型中占比最高,是当前多模态模型最薄弱的环节。所有模型的视觉感知错误占比均超过50%,其中Gemini2-Flash高达62%。这表明基础视觉理解能力仍是当前多模态模型的主要瓶颈。
2、计算错误(4-7%)和上下文误解错误率普遍较低(3-6%),其中Gemini2-Flash(3%)和Claude(4%)表现最佳,而QVQ(6%)略高,可能反映其存在过度推理倾向。
3、逻辑推理能力在不同模型之间存在显著差异。Claude的逻辑错误率最高(33%),这反映了其推理稳定性在本基准中欠佳。
4、答案整合方面,GPT-4o的答案整合错误率最高(23%),可能因其探索性推理产生多个答案而牺牲了响应规范性。
论文链接:http://arxiv.org/abs/2504.18589数据仓库:https://huggingface.co/datasets/cloudcatcher2/VCBench代码:https://github.com/alibaba-damo-academy/VCBench网页:https://alibaba-damo-academy.github.io/VCBench/