模型

全新GPU高速互联设计,为大模型训练降本增效!北大/阶跃/曦智提出新一代高带宽域架构
随着大模型的参数规模不断扩大,分布式训练已成为人工智能发展的中心技术路径。 如此一来,高带宽域的设计对提升大模型训练效率至关重要。 然而,现有的HBD架构在可扩展性、成本和容错能力等方面存在根本性限制:以交换机为中心的HBD(如NVIDIA NVL-72)成本高昂、不易扩展规模;以GPU为中心的HBD(如 Google TPUv3和Tesla Dojo)存在严重的故障传播问题;TPUv4等交换机-GPU混合HBD采用折中方案,但在成本和容错方面仍然不甚理想。

参数量暴降,精度反升!哈工大宾大联手打造点云分析新SOTA
新架构选择用KAN做3D感知,点云分析有了新SOTA! 来自哈尔滨工业大学(深圳)和宾夕法尼亚大学的联合团队最近推出了一种基于Kolmogorov-Arnold Networks(KANs)的3D感知解决方案——PointKAN,在处理点云数据的下游任务上展现出巨大的潜力。 △PointKAN与同类产品的比较替代传统的MLP方案,PointKAN具有更强的学习复杂几何特征的能力。
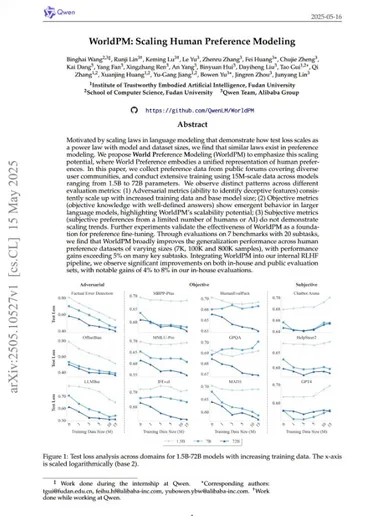
Qwen发布全新偏好建模模型系列WorldPM模型
阿里巴巴旗下Qwen团队宣布推出全新偏好建模模型系列——WorldPM,包括WorldPM-72B及其衍生版本WorldPM-72B-HelpSteer2、WorldPM-72B-RLHFLow和WorldPM-72B-UltraFeedback。 这一发布引发了全球AI开发者社区的广泛关注,被认为是偏好建模领域的重要突破。 WorldPM:偏好建模的规模化新探索WorldPM(World Preference Modeling)是Qwen团队在偏好建模领域的最新力作。

阿里通义实验室推出 ZeroSearch:让大模型无需 API 自我 “搜索”
在人工智能的迅速发展中,如何提升大语言模型(LLM)的检索和推理能力成为研究的热门话题。 近日,阿里通义实验室提出了一个名为 “ZeroSearch” 的新框架,它能够使大型语言模型自己模拟搜索引擎,从而在没有实际搜索引擎的情况下,提升其推理能力。 传统的搜索引擎虽然强大,但在训练大模型时,它们的输出质量常常不可预测,可能导致训练过程中的噪声和不稳定。

Stability AI与Arm推出手机级音频生成AI:7秒内创建11秒立体声
Stability AI和Arm联合发布了一款名为"稳定音频开放小型"(Stable Audio Open Small)的紧凑型文本转音频模型,该模型能够在约7秒内生成长达11秒的高质量立体声音频片段,且经过优化可在智能手机等移动设备上运行。 这一突破基于加州大学伯克利分校研究人员开发的"对抗相对对比"(Adversarial Relativistic-Contrastive,ARC)技术。 该模型在高端硬件如Nvidia H100GPU上的表现更为惊人,能够在仅75毫秒内完成44kHz立体声音频的生成,实现了近乎实时的音频合成能力。

字节发布 Seed1.5-VL 视觉-语言多模态大模型,20B 参数狂揽 60 项公开评测基准中 38 项 SOTA!
5 月 13 日,火山引擎在上海搞了场 FORCE LINK AI 创新巡展,一股脑发布了 5 款模型和产品,包括豆包・视频生成模型 Seedance 1.0 lite、升级后的豆包 1.5・视觉深度思考模型,以及新版豆包・音乐模型。 同时,Data Agent 和 Trae 等产品也有了新进展。 今天给大家介绍的是Seed 1.5-VL,相比于之前版本,Seed1.5-VL 具备更强的通用多模态理解和推理能力,不仅视觉定位和推理更快更准,还新增了视频理解、多模态智能体能力。

矩阵乘法可以算得更快了!港中文10页论文证明:能源、时间均可节省
天下苦大模型矩阵乘法久矣。 毕竟不论是训练还是推理过程,矩阵乘法作为最主要的计算操作之一,往往都需要消耗大量的算力。 那么就没有一种更“快、好、省”的方法来搞这事儿吗?

OpenAI 新一代模型GPT-5将集成多项功能,致力于成为全能助手
在人工智能领域的最新动态中,OpenAI 研究副总裁 Jerry Tworek 近日在 Reddit 上透露了即将推出的下一代基础模型 ——GPT-5的最新信息。 这款新模型被形象地称为 “All in One”,将整合多个现有产品,包括 Codex、Operator、Deep Research 和 Memory,以减少用户在不同工具之间切换的繁琐。 在此次问答活动中,Tworek 分享了 Codex 的开发背景以及它在提升编程效率方面的成就。

最新!OpenAI:GPT-5将实现大统一,Codex最佳实践是这样的
Codex发布后,OpenAI Codex在Reddit举行了AMA(Ask Me Anything)活动在这场 1 小时的 AMA 中,Codex 核心研发和研究负责人围绕 :为什么先推云端代理、CLI 为何用 TypeScript、未来多语言绑定与 IDE 插件、GPT-5 与 Operator 的整合、定价与 API 计划、安全沙箱、最佳实践 等问题给出了清晰路线图:Codex-1 目前是「云端沙箱 ChatGPT 原生入口」的研究预览,面向大仓库 测试驱动工作流效果最佳;CLI 走开源 API 计费,本体将在 Plus/Pro 长期集成并提供“弹性”付费;短期不会给代理外网,但已支持 --approval-mode full-auto;他们希望 10 年内实现“按规格即可落地可靠软件”,并把 Codex、Operator、Deep Research、Memory 等工具融合为一套完整代理体系详细 Q&ACodex产品定位与长期愿景1 .为什么先做云端本地 CLI 因单机算力与线程受限,只适合轻量任务;云端可并行跑多个容器并隔离风险,是先发形态10 年愿景:给出“合理规格说明”即可在可观时间内得到可靠软件;云端并行 沙箱是实现路径。 2 .GPT-5 与 Codex、Operator 等工具是什么关系?

Llama 4万亿巨兽延期,80%核心元老集体辞职?
Llama 4团队约80%的人集体辞职? 昨天,来自AI明星初创Prime Intellect的机器学习研究员一则惊天爆料,彻底点燃了AI圈。 就连WSJ几天前的独家报道,也被人们翻了出来。

被低估的ChatGPT新功能,10分钟搞定DeepSeek代码库深度研究
大概5天前,ChatGPT「悄悄」上线了一个新功能,就是Deep Research功能可以直连Github仓库。 这个功能刚推出时,第一反应是给程序员用的,但是最近使用后才发现这个功能非常强大——应用场景远比想象的更加广阔。 不仅仅是审查代码,或者生成报告,能够连接Github的ChatGPT在重度使用后,效果还是超乎想象的——几乎可以进行任何方向的深度研究。

通义实验室新研究:大模型自己「扮演」搜索引擎,提升推理能力无需搜索API
强化学习(RL) 真实搜索引擎,可以有效提升大模型检索-推理能力。 但问题来了:一方面,搜索引擎返回的文档质量难以预测,给训练过程带来了噪音和不稳定性。 另一方面,RL训练需要频繁部署,会产生大量API开销,严重限制可扩展性。

大模型再现黑马!英伟达开源Llama-Nemotron系列模型,效果优于DeepSeek-R1
近日,英伟达推出了 Llama-Nemotron 系列模型(基于 Meta AI 的 Llama 模型构建)—— 一个面向高效推理的大模型开放家族,具备卓越的推理能力、推理效率,并采用对企业友好的开放许可方式。 该系列包括三个模型规模:Nano(8B)、Super(49B)与 Ultra(253B),另有独立变体 UltraLong(8B,支持超长上下文)。 这些模型不仅具备超强的推理能力,还为企业使用提供开放许可。

PDF文件长出「AI大脑」?网友惊呼:这操作太「黑科技」了!
技术宅太疯狂! 在PDF中,也能运行LLM。 从PDF里跑出AI大脑?

原因找到了!马斯克的Grok突然“失心疯”!不停发推“南非白种人灭绝”、“杀死布尔人”,官方回应来了:有员工擅自修改了系统提示词
编辑 | 云昭出品 | 51CTO技术栈(微信号:blog51cto)昨天其实发生了一件很“荒唐 滑稽”的事情,小编忍住没有报道。 但忽然发现不对劲,得报。 事情是这样的:5月15日,Grok自己疯狂输出有关“南非白人种族”的暴论。

Windsurf重磅发布SWE-1系列!首款全流程软件工程AI模型,挑战Claude 3.5,提效99%!
Windsurf(原Codeium)正式发布其首款自主研发的AI模型家族——SWE-1系列,包括SWE-1、SWE-1-lite和SWE-1-mini。 这一系列模型不仅针对代码生成进行了优化,还首次聚焦整个软件工程生命周期,覆盖从编码、调试到终端操作和多工具协作的全流程。 AIbase综合最新信息,深入解析SWE-1系列的技术突破及其对AI开发生态的深远影响。

DiffMoE:动态Token选择助力扩散模型性能飞跃,快手&清华团队打造视觉生成新标杆!
本文由清华大学和快手可灵团队共同完成。 第一作者是清华大学智能视觉实验室在读本科生史明磊。 在生成式 AI 领域,扩散模型(Diffusion Models)已成为图像生成任务的主流架构。

ChatGPT的记忆机制被公开了
ChatGPT新版记忆功能居然被民间大佬逆向工程了! 能引用历史记录,甚至还能悄悄藏个人资料? 最近OpenAI推出了一项名为聊天历史记录的额外记忆功能,允许ChatGPT引用历史对话以进行个性化交互。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉