5 月 13 日,火山引擎在上海搞了场 FORCE LINK AI 创新巡展,一股脑发布了 5 款模型和产品,包括豆包・视频生成模型 Seedance 1.0 lite、升级后的豆包 1.5・视觉深度思考模型,以及新版豆包・音乐模型。同时,Data Agent 和 Trae 等产品也有了新进展。

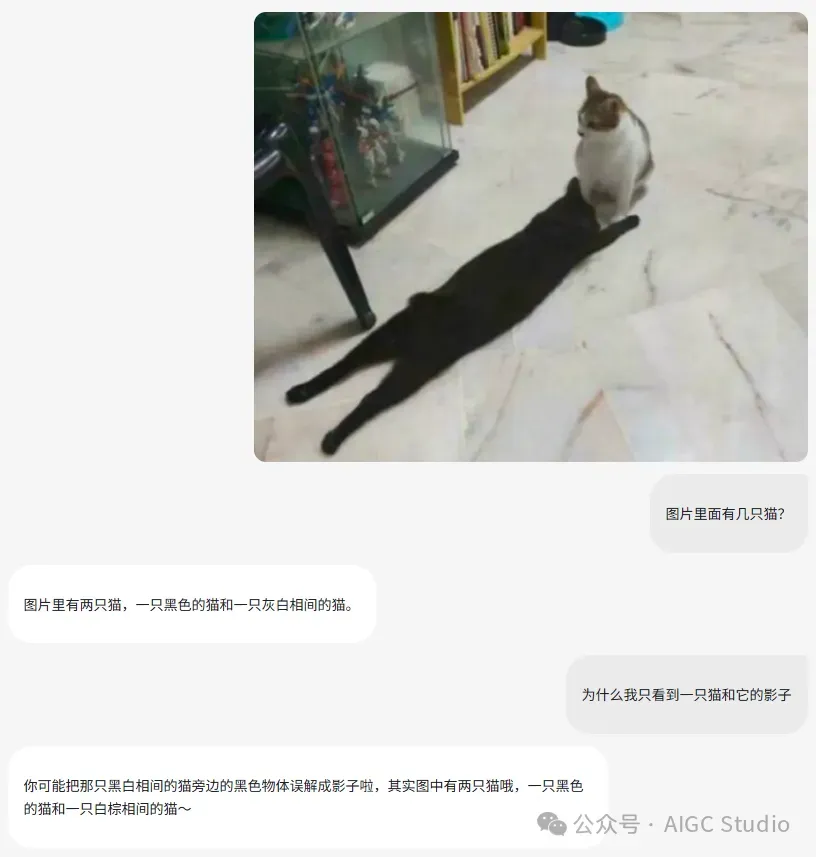
今天给大家介绍的是Seed 1.5-VL,相比于之前版本,Seed1.5-VL 具备更强的通用多模态理解和推理能力,不仅视觉定位和推理更快更准,还新增了视频理解、多模态智能体能力。举个例子。仅需一张图,再来个提示词,Seed1.5-VL 就能精准识别观众、棒球、座椅、围栏等多种元素,还能正确分类并给出坐标。

示例展示
基础感知能力
视觉定位

视觉谜题

相关链接
- 官网:https://seed.bytedance.com/tech/seed1_5_vl
- 代码:https://github.com/ByteDance-Seed/Seed1.5-VL
- API:https://www.volcengine.com/experience/ark?model=doubao-1-5-thinking-vision-pro-250428
模型架构
Seed1.5-VL 包含一个 5.32 亿参数的视觉编码器,以及一个激活参数规模达 200 亿的混合专家(MoE)大语言模型。
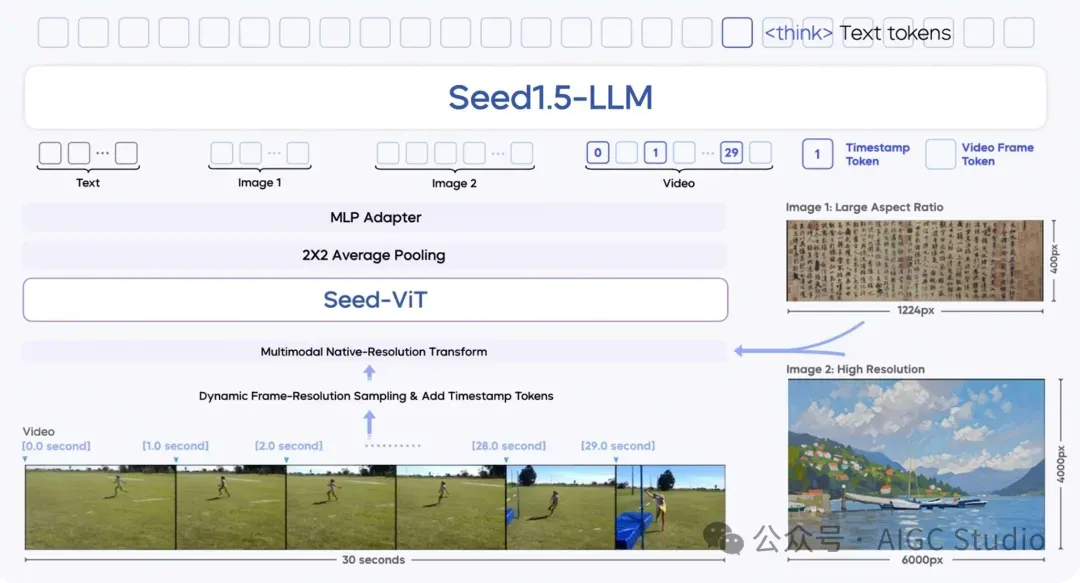 Seed1.5-VL 模型结构图
Seed1.5-VL 模型结构图
模型由以下三个核心组件组成:
- SeedViT:用于对图像和视频进行编码;
- MLP 适配器:将视觉特征投射为多模态 token;
- 大语言模型:用于处理多模态输入并执行推理。
Seed1.5-VL 支持多种分辨率的图像输入,并通过原生分辨率变换(native-resolution transform)确保最大限度保留图像细节。在视频处理方面,提出了一种动态帧分辨率采样策略(dynamic frame-resolution sampling strategy),能够根据需要动态调整采样帧率和分辨率。此外,为了增强模型的时间信息感知能力,在每帧图像之前引入了时间戳标记(timestamp token)。
预训练数据与 Scaling Law
Seed1.5-VL 的预训练语料库包含 3 万亿个多样化且高质量的源标记(source tokens)。这些数据根据模型目标能力的需求进行了分类。
在预训练阶段观察到大多数子类别的数据训练损失与训练标记数量之间遵循幂律关系。此外,某一子类别的训练损失与该类别对应的下游任务评估指标之间呈现对数线性关系(例如:评估指标 ∼ log(训练损失))的趋势,尤其在局部区域内尤为显著。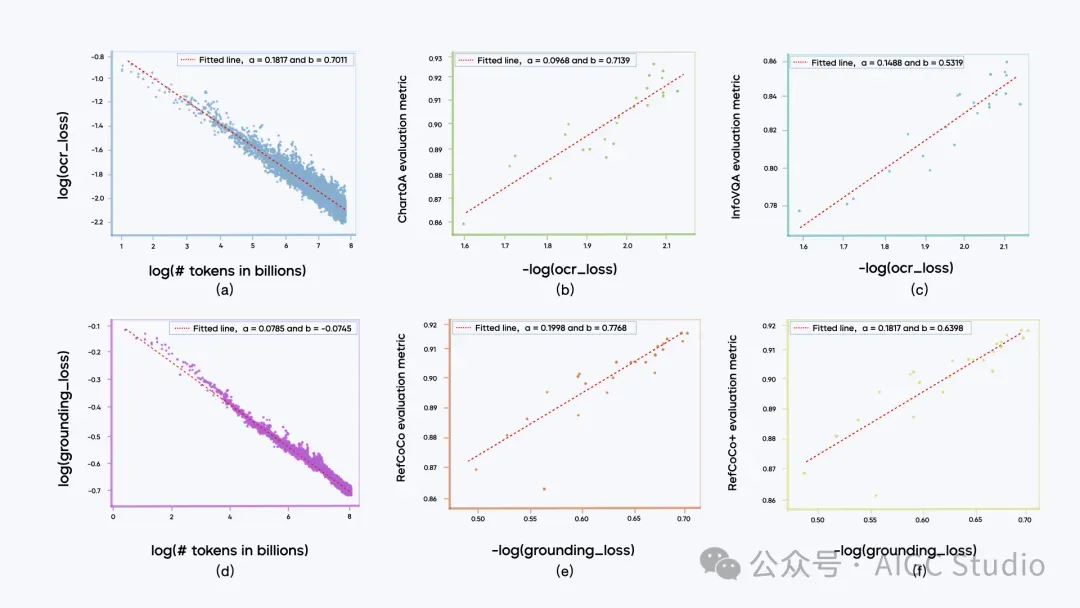
后训练
Seed1.5-VL 的后训练过程采用了结合拒绝采样(rejection sampling)和在线强化学习(online reinforcement learning)的迭代更新方法。我们构建了一条完整的数据 pipeline,用于收集和筛选复杂提示,以增强后训练阶段的数据质量。
强化学习实现的一个关键特点是,监督信号通过奖励模型(reward models)和规则验证器(rule verifiers)仅作用于模型生成的最终输出结果。我们特意避免对模型的详细链式思维推理(chain-of-thought reasoning)过程进行监督。这一区别在插图的右侧部分得到了重点说明。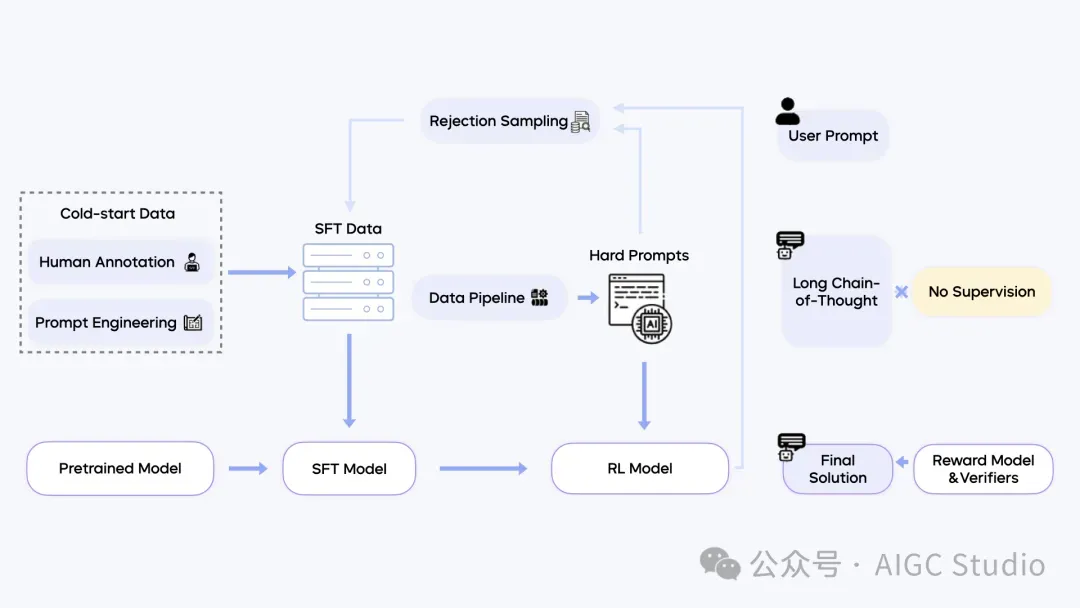
基准测试
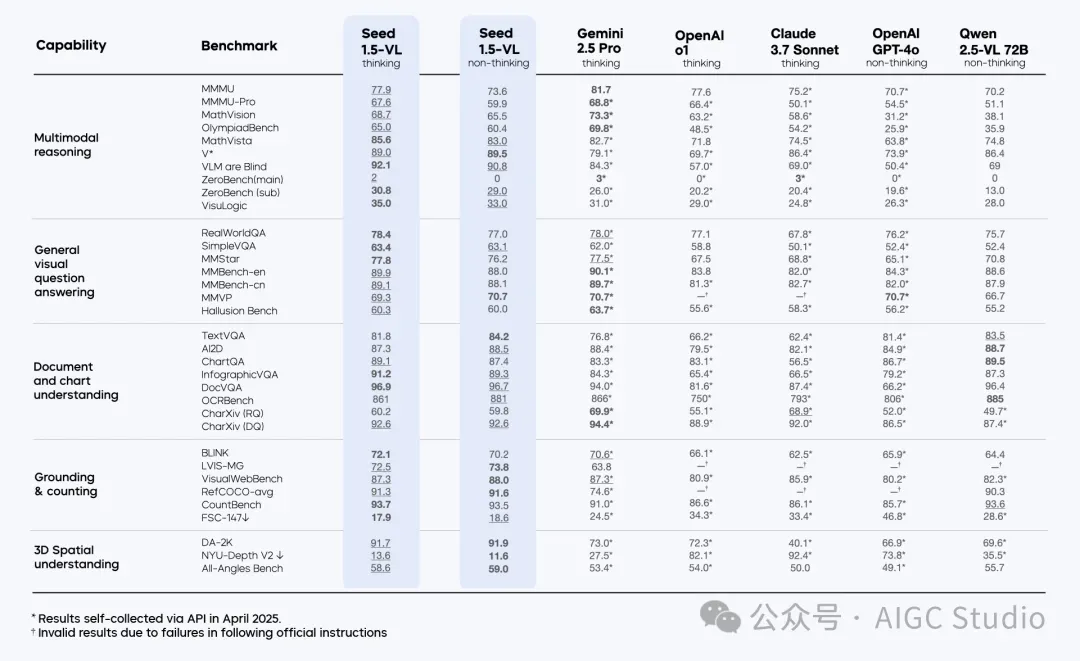
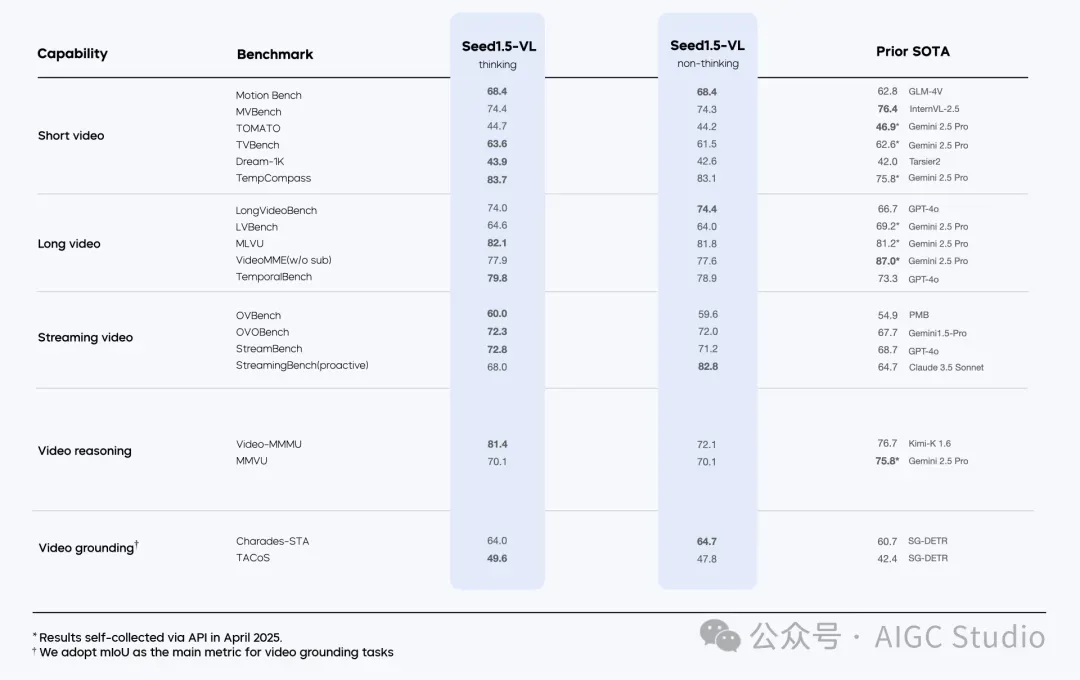
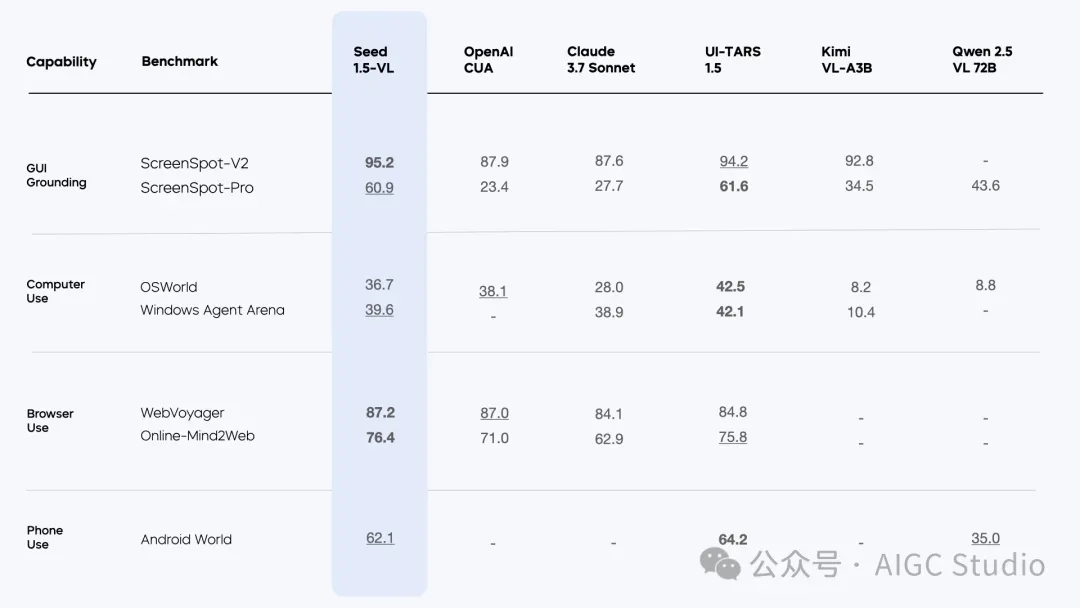
Seed1.5-VL 在 60 项公开基准测试中取得了 38 项的最新最优性能(state-of-the-art performance),其中包括 19 项视频基准测试中的 14 项,以及 7 项 GUI 代理任务中的 3 项。
局限性
尽管 Seed1.5-VL 展现了出色能力,但仍存在一些局限性,尤其是在细粒度视觉感知、三维空间推理以及复杂组合搜索任务方面。解决这些挑战是我们持续研究的核心部分,研究方向包括统一现有模型能力与图像生成,以及引入更健全的工具使用机制。


