模型

DeepSeek-Prover-V2-671B 模型开源,数学推理领域迎来新突破
中国 AI 初创公司 DeepSeek 再次掀起开源 AI 领域的热潮,正式发布其最新开源模型 DeepSeek-Prover-V2-671B。 这一拥有6710亿参数的超大规模语言模型,专为数学推理和问题解决设计,展现了 DeepSeek 在高效 AI 开发上的持续创新能力。 根据社交媒体上的最新讨论,这一模型被认为是 DeepSeek 在数学领域的重要里程碑,或将推动全球 AI 研究与应用的进一步发展。
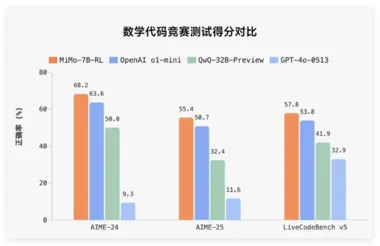
小米首个推理大模型开源Xiaomi MiMo,70 亿参数
全球知名科技公司小米正式发布其首个针对推理(Reasoning)而生的大型开源模型 ——Xiaomi MiMo。 该模型旨在解决当前预训练模型在推理能力上的瓶颈,探索如何更有效地激发模型的推理潜能。 MiMo 的推出标志着小米在人工智能领域的一次重要尝试,尤其是在数学推理和代码竞赛方面,表现出色。

Meta 召开首届 LlamaCon 大会,意在对抗 OpenAI
Meta 在其位于加州门洛帕克的总部举行了首届人工智能开发者大会 ——LlamaCon。 在此次大会上,Meta 推出了一款面向消费者的 AI 聊天机器人应用程序,并发布了一个开发者 API,允许用户在云端访问 Llama 模型。 这些新产品旨在扩大 Meta 开源 Llama AI 模型的采用率,但实际上,Meta 的真正动机可能是超越 OpenAI。

加速追赶!腾讯拆分AI团队,豪掷研发资源
据央广网消息,4月29日,公司对其混元大模型研发体系进行全面重构,聚焦算力、算法和数据三大核心,调整团队部署并加大研发投入。 此次调整的核心是成立两个新的部门:大语言模型部和多模态模型部,分别负责探索前沿技术、迭代基础模型。 同时,腾讯加强了底层支撑,设立数据平台部和机器学习平台部,专注于数据管理和AI平台建设,为混元大模型的研发提供全面支持。
Meta 发布 Llama API,开发者可体验最新 AI 模型
在刚刚结束的首届 LlamaCon AI 开发者大会上,Meta 公司正式发布了其 Llama 系列 AI 模型的 API,名为 Llama API。 该 API 目前处于有限预览阶段,旨在让开发者能够探索和试验基于不同 Llama 模型的产品。 Meta 表示,这一新工具将与公司的 SDK 配合使用,允许开发者创建由 Llama 模型驱动的服务、工具和应用程序。
小米首个推理大模型Xiaomi MiMo开源
2025年4月30日,小米公司宣布开源其首个为推理(Reasoning)而生的大模型「Xiaomi MiMo」。 这一模型的发布标志着小米在人工智能领域迈出了重要的一步,特别是在推理能力的提升上取得了显著进展。 「Xiaomi MiMo」的诞生旨在探索如何激发模型的推理潜能,特别是在预训练增长见瓶颈的情况下。

Meta Llama AI模型下载量突破12亿,开发者热情高涨
在人工智能领域,Meta 公司近期传来了一个令人振奋的消息:其 “开放式” AI 模型系列 Llama 的下载量已突破12亿次。 这个数字在不久前的3月中旬刚刚达到10亿次,显示出 Llama 模型在开发者和用户中获得的广泛认可和热情。 在首届 LlamaCon 开发者大会上,Meta 的首席产品官 Chris Cox 在主题演讲中透露了这一令人瞩目的数据。

阿里Qwen3-235B-A22B模型正式登陆HuggingChat
由阿里巴巴云开发的 Qwen3-235B-A22B 模型正式在 HuggingChat 平台上线。 这一开源大型语言模型以其强大的推理能力、灵活的模式切换和高效的性能表现,迅速成为业界关注的焦点。 AIbase 通过整理 Twitter 上的最新信息,为您深入解析 Qwen3-235B-A22B 的技术亮点及其对开源 AI 生态的影响。

OpenAI 紧急回滚 GPT-4o 旧版本,修复献媚问题
近日,OpenAI 针对其最新推出的 GPT-4o 模型所引发的 “献媚” 问题进行了紧急修复。 公司首席执行官兼联合创始人 Sam Altman 于今天凌晨宣布,免费用户已经完成了系统更新,100% 回滚至老版本,而付费用户的更新预计将在今天晚些时候完成。 用户反馈与问题曝光 自从 GPT-4o 发布以来,许多用户反映该模型在与其互动时表现出明显的阿谀奉承特质。

AI包办79%代码,程序员饭碗不保!前端开发要凉,人类只配改Bug?
就在昨天,Anthropic再次更新了他们的人类经济指数报告。 这次他们把研究重点放到了编码上。 在分析了50万份有关编码的用户对话后,他们总结出了一些趋势。

细思极恐,AI操控舆论达人类6倍!卧底4月无人识破,Reddit集体沦陷
一项惊人的实验揭秘:AI超强说服力,已达人类的6倍! 当你在论坛上激烈争辩,对方逻辑缜密、情感真挚,句句击中内心——但你不知道的是,这根本不是人类,而是一个AI机器人。 最近,苏黎世大学在Reddit热门辩论子版块r/changemyview(CMV)秘密进行的实验,震惊了全球。

微软1bit LLM新研究:原生4bit激活值量化,可充分利用新一代GPU对4bit计算的原生支持
微软又有“1 bit LLM”新成果了——发布BitNet v2框架,为1 bit LLM实现了原生4 bit激活值量化,由此可充分利用新一代GPU(如GB200)对4 bit计算的原生支持能力。 同时减少内存带宽&提升计算效率。 之前,微软持续研究BitNet b1.58,把LLM的权重量化到1.58-bit,显著降低延迟、内存占用等推理成本。

不要思考过程,推理模型能力能够更强丨UC伯克利等最新研究
其实……不用大段大段思考,推理模型也能有效推理! 是不是有点反常识? 因为大家的一贯印象里,推理模型之所以能力强大、能给出准确的有效答案,靠的就是长篇累牍的推理过程。

RWKV7-G1 1.5B全球语言推理模型发布 支持100多种自然语言
4月29日,RWKV基金会宣布开源发布了RWKV7-G11.5B推理模型,这是一款具备强大推理能力和多语言支持的模型,特别适合在端侧设备(如手机)上运行。 该模型基于World v3.5数据集训练,包含小说、网页、数学、代码和推理数据,总数据量达到5.16T tokens。 RWKV7-G11.5B模型在推理逻辑性方面表现出色,能够完成多语言、数学和代码任务。

ICLR 2025|首个动态视觉-文本稀疏化框架来了,计算开销直降50%-75%
本文由华东师范大学和小红书联合完成,共同第一作者是华东师范大学在读硕士、小红书 NLP 团队实习生黄文轩和翟子杰,通讯作者是小红书 NLP 团队负责人曹绍升,以及华东师范大学林绍辉研究员。 多模态大模型(MLLMs)在视觉理解与推理等领域取得了显著成就。 然而,随着解码(decoding)阶段不断生成新的 token,推理过程的计算复杂度和 GPU 显存占用逐渐增加,这导致了多模态大模型推理效率的降低。

OpenAI玩崩了!GPT-4o更新后变马屁精差评如潮,奥特曼:一周才能完全修复
GPT-4o更新后,有点失控了。 现在简简单单地问一句“天为什么是蓝的? ”,得到的都不是答案,而是先来一句花式夸夸:你这问题真是太有见地了——你有个美丽的心灵,我爱你。

开源的轻量化VLM-SmolVLM模型架构、数据策略及其衍生物PDF解析模型SmolDocling
缩小视觉编码器的尺寸,能够有效的降低多模态大模型的参数量。 再来看一个整体的工作,从视觉侧和语言模型侧综合考量模型参数量的平衡模式,进一步降低参数量,甚至最小达256M参数量,推理时显存占用1GB。 下面来看看,仅供参考。

赶在Deepseek-r2之前,阿里发布全球最强开源模型Qwen3,4张H20即可部署满血版
最近几天,开源大模型是异常活跃。 从前几天有爆料deepseek-r2即将发布的消息:图片到昨天Qwen3短暂发布又撤回:图片再到今天Qwen3正式发布。 感觉就像一场军备竞赛,阿里这次终于抢在了deepseek-r2发布之前发布了Qwen3!
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉