模型

纳米AI为4亿打工人定制「AI牛马」!可0代码手搓超级智能体
AI的未来是什么? 是能听懂你一句指令,就帮你写报告、做PPT、发爆款内容的「超级助手」。 4月23日,纳米AI重磅官宣:全面支持MCP协议,上线MCP万能工具箱。

GPT-4o一夜变身「赛博舔狗」,百万网友泪目!奥特曼紧急修复,网友:求别修
最近,全网都被GPT-4o的「赛博舔狗」行为震惊了。 这些天的GPT-4o,突变成了这个画风。 用户:「你愿意打一只马那么大的鸭子,还是打一百只鸭子那么大的小马?
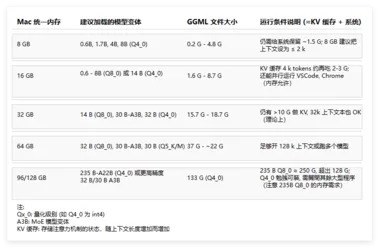
Mac也能跑Qwen3,一文看懂本地部署qwen 3配置要求
本地部署 Qwen3模型:借助 Ollama 在 Mac 上畅享大模型力量随着大型语言模型技术的飞速发展,越来越多的用户希望能在本地环境中运行这些强大的模型,以获得更好的数据隐私、更快的响应速度以及更灵活的定制性。 好消息是,知名的模型运行平台 Ollama 已经全面支持 Qwen3系列模型,这使得在个人设备上本地部署 Qwen3成为可能。 本文将重点介绍如何利用 Ollama 在 Mac 设备上进行 Qwen3模型的本地部署与配置,并结合最新的模型规格信息,为您提供详细的参考。
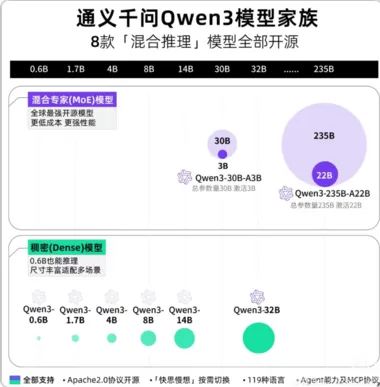
性能与效率的双赢:Qwen3横空出世,MoE架构大幅降低部署成本
阿里云旗下通义千问(Qwen)团队正式发布Qwen3系列模型,共推出8款不同规格的模型,覆盖从移动设备到大型服务器的全部应用场景。 这是国内首个全面超越DeepSeek R1的开源模型,也是首个配备混合思维模式的国产模型。 模型阵容丰富,满足各类部署需求Qwen3系列包含6款Dense模型和2款MoE模型:Dense模型:0.6B、1.7B、4B、8B、14B、32BMoE模型:Qwen3-235B-A22B (总参数235B,激活参数22B)Qwen3-30B-A3B (总参数30B,激活参数3B)所有模型均支持128K上下文窗口,并配备了可手动控制的"thinking"开关,实现混合思维模式。

阿里Qwen3深度解析:新一代开源大语言模型的革新与突破
Qwen3是什么?阿里Qwen3是通义千问系列的最新一代开源大语言模型(LLM),于2025年4月29日正式发布。 作为全球首个支持“混合推理”的模型,Qwen3包含8款不同规模的模型,涵盖稠密模型(如0.6B、4B、32B)和混合专家模型(MoE,如30B-A3B、235B-A22B),采用Apache2.0协议开源,支持免费商用。 其核心目标是提供高性能、低成本的AI解决方案,同时覆盖从边缘设备到企业级服务器的全场景需求。

暗月之面发布开源模型 Kimi-VL, 28 亿个参数即可处理文本、图像和视频
中国初创公司 Moonshot AI 最近推出了一款名为 Kimi-VL 的开源模型。 该模型在处理图像、文本和视频方面表现出色,以其高效的性能引起了广泛关注。 Kimi-VL 最大的亮点在于其处理长文档、复杂推理和用户界面的能力。
通义App全面上线千问3 第一时间体验全球最强开源模型
4月29日,通义App与通义网页版(tongyi.com)全面上线阿里新一代通义千问开源模型Qwen3(简称千问3)。 用户可以第一时间在通义App和网页版中的专属智能体“千问大模型”,以及主对话页面,体验到全球最强开源模型的顶级智能能力。 据了解,千问3一经发布便登顶全球最强开源模型。
Ollama 支持全线的 Qwen 3 模型
Ollama官方宣布已全面支持阿里巴巴通义千问最新一代大语言模型系列——Qwen3。 这一重要更新进一步丰富了Ollama的开源模型生态,为开发者、企业及AI爱好者提供了更强大的本地化部署选择,显著提升了在多种场景下的AI应用灵活性与效率。 Qwen3模型:性能与规模并重Qwen3是阿里巴巴通义千问团队推出的最新一代大语言模型,涵盖从0.6亿到2350亿参数的广泛模型规模,包括高效的混合专家(MoE)模型。

北京大学推出新基准评测PHYBench,挑战AI物理推理能力!
最近,北京大学物理学院联合多个院系,推出了一项名为 “PHYBench” 的全新评测基准,旨在检验大模型在物理推理上的真实能力。 该项目由朱华星老师和曹庆宏副院长主导,汇聚了来自物理学院和其他学科的200多名学生,其中不少人曾在全国中学生物理竞赛中获金牌。 PHYBench 设计了500道精心制作的高质量物理题,这些题目涵盖高中物理、大学物理及物理奥林匹克竞赛的各个层面。
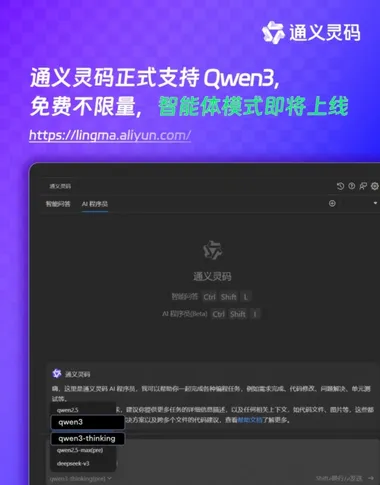
通义灵码上线Qwen3:编程智能体即将上线 集成魔搭MCP广场
通义灵码团队宣布正式上线Qwen3,并开源了8款「混合推理模型」,这标志着编程智能体的进一步发展。 此次开源包括两款MoE模型:Qwen3-235B-A22B(2350多亿总参数、220多亿激活参数),以及Qwen3-30B-A3B(300亿总参数、30亿激活参数);还有六个Dense模型:Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B和Qwen3-0.6B。 Qwen3的旗舰模型Qwen3-235B-A22B在代码、数学和通用能力等基准测试中表现出色,与DeepSeek-R1、o1、o3-mini、Grok-3和Gemini-2.5-Pro等顶级模型相比,展现了极具竞争力的结果。
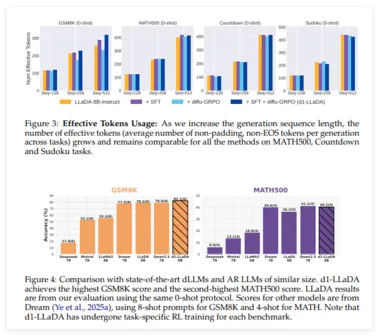
大幅提升 AI 推理速度:UCLA 与 Meta AI 联合推出 d1 框架
在人工智能领域,UCLA 和 Meta AI 的研究人员联合推出了一种名为 d1的新框架,该框架通过强化学习技术显著提升了扩散式大语言模型(dLLMs)的推理能力。 虽然传统的自回归模型如 GPT 受到了广泛关注,但 dLLMs 凭借其独特的优势,若能加强推理能力,将为企业带来新的效率和应用前景。 扩散式语言模型与自回归模型的生成方式截然不同。

OpenAI CEO 透露 GPT-4o 存在 “过度谄媚” 问题,计划一周内推出修复
OpenAI 首席执行官萨姆・奥尔特曼(Sam Altman)在社交媒体上回应了用户对于最新版本 GPT-4o 的一些反馈,指出该模型在情感表达上出现了 “过度谄媚” 的倾向。 奥尔特曼承诺,OpenAI 将在一周内推出解决方案,以修复这一问题。 根据 OpenAI 的更新记录,GPT-4o 于3月27日进行了一次全面的更新,随后在4月25日进行了进一步的调整,重点提升了模型在科学、技术、工程和数学(STEM)领域的能力。

港大&Adobe联合提出图像生成模型PixelFlow,可直接在原始像素空间中运行,无需VAE即可进行端到端训练
香港大学和Adobe联合提出了一种直接在原始像素空间中运行的图像生成模型PixelFlow,这种方法简化了图像生成过程,无需预先训练的变分自编码器 (VAE),并使整个模型能够端到端训练。 通过高效的级联流建模,PixelFlow 在像素空间中实现了可承受的计算成本。 它在 256x256 ImageNet 类条件图像生成基准上实现了 1.98 的 FID。

告别“图文不符”!FG-CLIP实现细粒度跨模态对齐,360开源模型重塑AI视觉理解
CLIP的“近视”问题,被360搞定了。 360人工智能研究院最新图文跨模态模型FG-CLIP,宣布以“长文本深度理解”和“细粒度视觉比对”双突破,彻底解决了传统CLIP模型的“视觉近视”问题,能够精准识别局部细节。 具体怎么个说法?

颠覆传统RAG,创新大模型检索增强—Insight-RAG
RAG已经成为大模型的标题,但传统方法存在检索深度不足、难以整合多源信息等弊端,例如,传统 RAG 依赖表面相关性检索文档,容易忽略单个文档内深埋的信息。 在法律协议中,会忽略微妙的合同条款;在商业报告里,错过隐藏的数据趋势。 所以,Megagon实验室的研究人员提出了一种创新框架Insight-RAG,从而更好地捕捉任务特定的细微信息,整合的数据质量也更高。

模型压缩到70%,还能保持100%准确率,无损压缩框架DFloat11来了
大型语言模型(LLMs)在广泛的自然语言处理(NLP)任务中展现出了卓越的能力。 然而,它们迅速增长的规模给高效部署和推理带来了巨大障碍,特别是在计算或内存资源有限的环境中。 例如,Llama-3.1-405B 在 BFloat16(16-bit Brain Float)格式下拥有 4050 亿个参数,需要大约 810GB 的内存进行完整推理,超过了典型高端 GPU 服务器(例如,DGX A100/H100,配备 8 个 80GB GPU)的能力。

上交大等探索键值压缩的边界:MILLION开源框架定义模型量化推理新范式,入选顶会DAC 2025
本篇工作已被电子设计自动化领域顶级会议 DAC 2025 接收,由上海交大计算机学院蒋力教授与刘方鑫助理教授带领的 IMPACT 课题组完成,同时也获得了华为 2012 实验室和上海期智研究院的支持。 第一作者是博士生汪宗武与硕士生许鹏。 在通用人工智能的黎明时刻,大语言模型被越来越多地应用到复杂任务中,虽然展现出了巨大的潜力和价值,但对计算和存储资源也提出了前所未有的挑战。

字节Seed团队PHD-Transformer突破预训练长度扩展!破解KV缓存膨胀难题
最近,DeepSeek-R1 和 OpenAI o1/03 等推理大模型在后训练阶段探索了长度扩展(length scaling),通过强化学习(比如 PPO、GPRO)训练模型生成很长的推理链(CoT),并在奥数等高难度推理任务上取得了显著的效果提升。 受此启发,研究人员开始探索预训练阶段的长度扩展,已有方法包括在序列中插入文本、插入潜在向量(如 Coconut)、复用中间层隐藏状态(如 CoTFormer)以及将中间隐藏状态映射为概念(如 COCOMix)。 不过,这些方法普遍存在问题,比如需要更大的 KV 缓存导致推理慢 / 占内存多。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉