2025年4月30日,小米公司宣布开源其首个为推理(Reasoning)而生的大模型「Xiaomi MiMo」。这一模型的发布标志着小米在人工智能领域迈出了重要的一步,特别是在推理能力的提升上取得了显著进展。
「Xiaomi MiMo」的诞生旨在探索如何激发模型的推理潜能,特别是在预训练增长见瓶颈的情况下。该模型在数学推理(AIME24-25)和代码竞赛(LiveCodeBench v5)公开测评集上表现出色,仅用7B的参数规模就超越了OpenAI的闭源推理模型o1-mini和阿里Qwen更大规模的开源推理模型QwQ-32B-Preview。
在强化学习方面,MiMo-7B的潜力显著领先于其他广泛使用的强化学习起步模型,如DeepSeek-R1-Distill-7B和Qwen2.5-32B。这一成就得益于MiMo在预训练和后训练阶段的多层面创新。在预训练阶段,MiMo着重挖掘富推理语料,并合成了约200B tokens的推理数据。训练过程中,MiMo进行了三阶段训练,逐步提升训练难度,总训练量达到25T tokens。
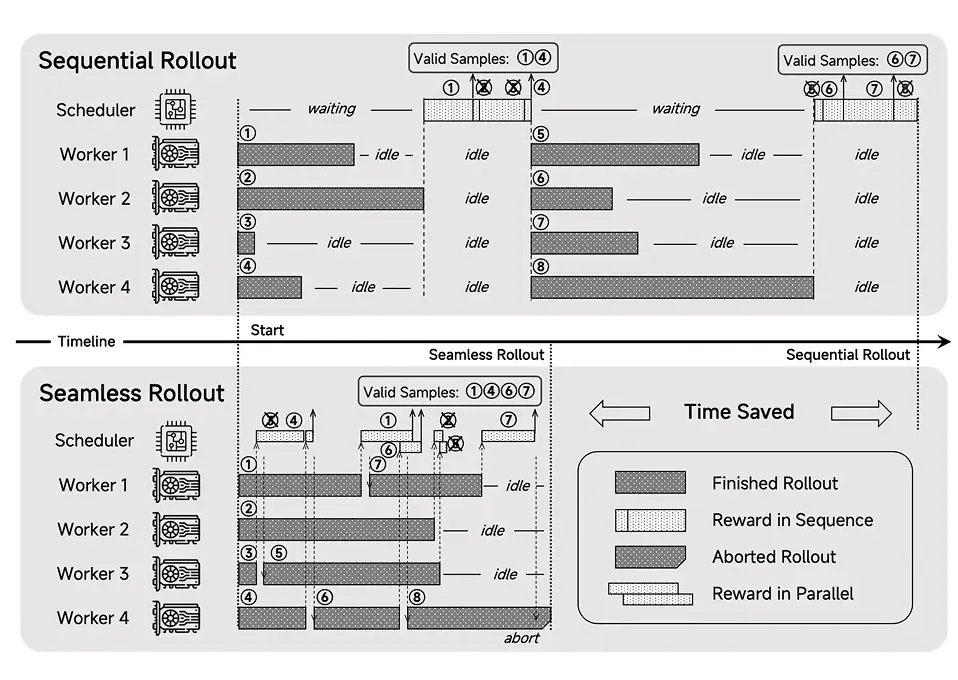
在后训练阶段,MiMo的核心是高效稳定的强化学习算法和框架。为此,MiMo提出了Test Difficulty Driven Reward策略,以缓解困难算法问题中的奖励稀疏问题,并引入Easy Data Re-Sampling策略,以稳定RL训练。此外,MiMo还设计了Seamless Rollout系统,使得RL训练加速2.29倍,验证加速1.96倍。
MiMo-7B全系列已开源,用户可在HuggingFace上找到相关模型:[XiaomiMiMo](https://huggingface.co/XiaomiMiMo)。