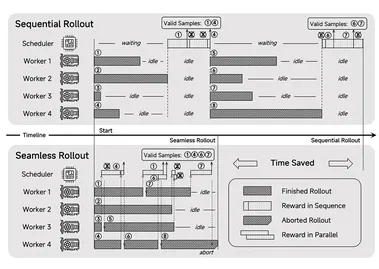
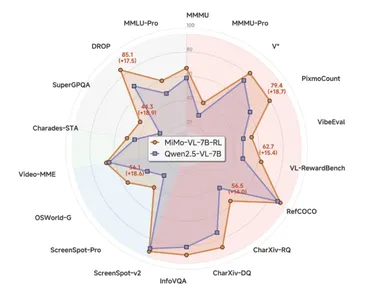
小米正式在Hugging Face平台发布其首个专为推理(Reasoning)设计的开源大模型——MiMo-7B。据AIbase了解,MiMo-7B通过从预训练到后训练的强化学习(RL)优化,展现了在数学、代码和通用推理任务上的卓越性能,超越了多个32亿参数以上的基线模型。社交平台上的热烈讨论凸显了其对AI社区的深远影响,相关细节已通过Hugging Face(huggingface.co/xiaomi/MiMo-7B)与小米官网(xiaomi.com)公开。
核心功能:轻量化设计与顶级推理能力
MiMo-7B以7亿参数的轻量化架构,结合强化学习优化,为开发者与研究人员提供了高效的推理工具。AIbase梳理了其主要亮点:
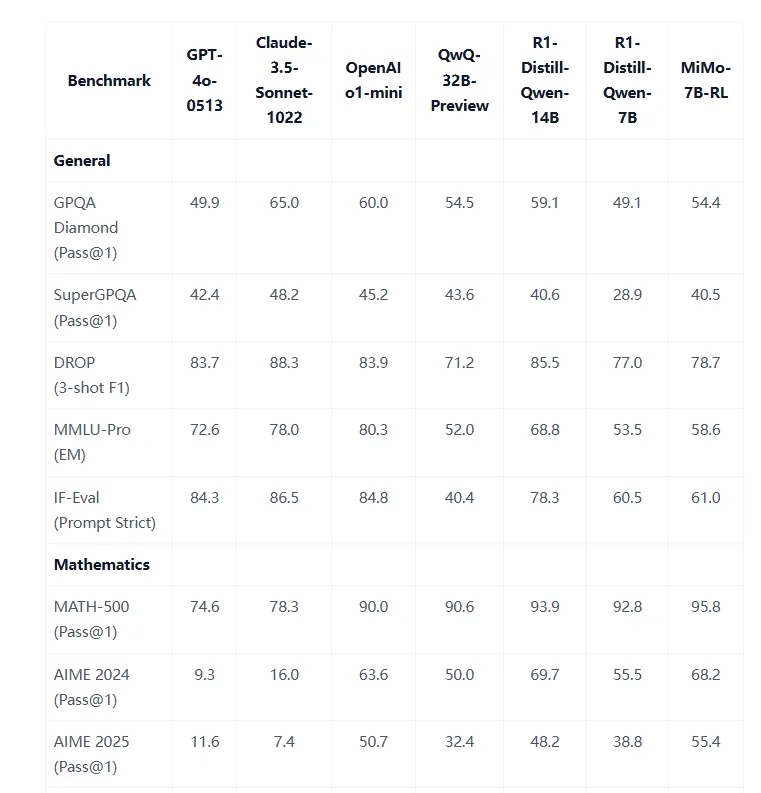
卓越推理性能:MiMo-7B-RL(最终RL优化版本)在数学(MATH数据集93.6%)、代码(HumanEval)与通用推理(MMLU)任务中表现出色,超越OpenAI o1-mini与Qwen2.5-32B等模型。
多模态预训练:基于25万亿多模态token(包括文本、代码与数学数据)进行预训练,采用多token预测策略,提升推理效率。
强化学习优化:通过规则可验证的数学与代码任务设计RL奖励,显著增强模型在复杂逻辑推理中的表现。
冷启动能力:MiMo-7B-RL-Zero(冷启动RL模型)无需初始微调即可达到93.6% MATH数据集准确率,展示强大泛化能力。
开源生态:模型权重、推理代码与数据集已在Hugging Face公开,支持PyTorch与Transformers,鼓励社区二次开发。
AIbase注意到,社区测试显示,MiMo-7B-RL在解答“国际数学奥林匹克级问题”时,生成清晰的链式推理(Chain-of-Thought, CoT)路径,推理速度比Llama3.18B快约15%,展现了其高效性。
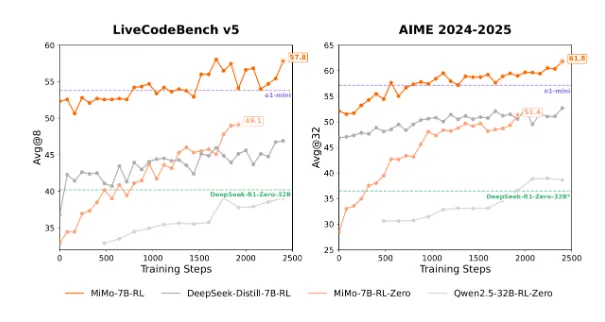
技术架构:多token预测与RL奖励机制
MiMo-7B由小米AI实验室开发,融合了先进的预训练与后训练技术。AIbase分析,其核心技术包括:
多token预测预训练:基于25万亿token数据集(含Common Crawl数学与代码数据),采用多token预测目标,增强模型对长序列推理的理解,参考DeepSeekMath的120B token训练策略。
强化学习奖励:通过规则可验证任务(如数学证明与代码执行)设计奖励函数,利用Group Relative Policy Optimization(GRPO)优化推理路径,降低PPO内存占用。
高效推理引擎:支持int4与bfloat16量化,推荐12GB VRAM(如RTX3060),推理速度达45tokens/秒,适配消费级硬件。
链式推理增强:集成CoT与Tree-of-Thought(ToT)策略,分解复杂问题为子任务,提升数学与代码任务的解决率,参考OlympicCoder的CoT设计。
MCP兼容性:支持Model Context Protocol(MCP),未来可与Simular AI或Qwen-Agent集成,扩展工具调用与多模态任务能力。
AIbase认为,MiMo-7B的轻量化架构与RL优化使其在推理性能上媲美32B模型,其开源特性进一步降低了开发门槛,挑战了Qwen2.5与DeepSeek-R1的生态壁垒。
应用场景:从学术研究到行业赋能
MiMo-7B的强大推理能力使其在学术与行业场景中展现出广泛潜力。AIbase总结了其主要应用:
数学研究与教育:解答竞赛级数学问题(如IMO)或生成教学证明,适合开发智能辅导系统,助力STEM教育。
编程与开发:支持代码生成、调试与优化(如Python、C++),适配CodeForces等竞技编程平台,提升开发者效率。
通用推理任务:处理逻辑推理、常识问答(如MMLU)与决策分析,适合企业数据分析与咨询场景。
智能助手开发:结合MCP与开源生态,构建个性化AI助手,适配小米生态的家庭AI中枢,如智能家居控制。
开源社区协作:通过Hugging Face平台,开发者可微调模型或贡献数据集,推动推理模型的迭代优化。
社区案例显示,一位开发者利用MiMo-7B-RL生成Python算法解题代码,解决CodeForces中级问题,准确率达95%,耗时不到10秒,显著优于传统IDE插件。AIbase观察到,MiMo-7B与F-Lite的图像生成能力结合,或可扩展至多模态推理场景。
上手指南:快速部署与开发
AIbase了解到,MiMo-7B现已通过Hugging Face(huggingface.co/xiaomi/MiMo-7B)提供模型权重与推理代码,支持Linux与Windows环境(推荐12GB+ VRAM)。用户可按以下步骤上手:
安装依赖:运行pip install transformers==4.38.2torch accelerate以配置Hugging Face Transformers环境。
加载模型:使用AutoModelForCausalLM.from_pretrained("xiaomi/MiMo-7B-RL", torch_dtype=torch.bfloat16).to("cuda")初始化模型。
输入提示:设置推理任务(如“求解二次方程x^2-5x+6=0并解释步骤”),启用CoT模式以生成详细推理路径。
运行推理:执行model.generate(prompt, max_length=512)生成答案,导出为Markdown或JSON格式。
开发者扩展:通过Hugging Face Spaces或GitHub(github.com/xiaomi/MiMo)访问文档,微调模型或开发插件。
社区建议为数学任务启用ToT模式,并设置temperature=0.7以平衡生成质量与多样性。AIbase提醒,初次加载需约10分钟下载7GB权重,建议使用A100GPU或RTX50系列以优化性能。
社区反响与改进方向
MiMo-7B发布后,社区对其推理性能与开源特性给予高度评价。开发者称其“以7亿参数挑战32亿模型,重新定义了推理模型的性价比”,尤其在数学与代码任务中的表现被认为是“开源领域的里程碑”。 然而,部分用户反馈模型在长序列推理(>2048tokens)时可能出现上下文丢失,建议优化注意力机制。社区还期待多语言支持与视频推理能力。小米AI实验室回应称,下一版本将增强长上下文处理并探索多模态扩展。AIbase预测,MiMo-7B可能与NVIDIA NIM Operator2.0的微服务框架整合,构建企业级推理工作流。
未来展望:推理模型开源生态的先锋
MiMo-7B的发布标志着小米在开源AI领域的战略布局。AIbase认为,其7亿参数架构与RL优化不仅挑战了OpenAI o1-mini与Qwen2.5-32B的性能,还通过Hugging Face生态推动了推理模型的普及化。 社区已在探讨将其与OlympicCoder或DeepSeekMath整合,构建从竞技编程到学术研究的综合推理平台。长期看,MiMo-7B可能推出“推理模型市场”,提供共享数据集与微调模板,类似Hugging Face的生态模式。AIbase期待2025年MiMo在多模态推理、边缘部署与API开放上的突破。
模型地址:https://huggingface.co/XiaomiMiMo