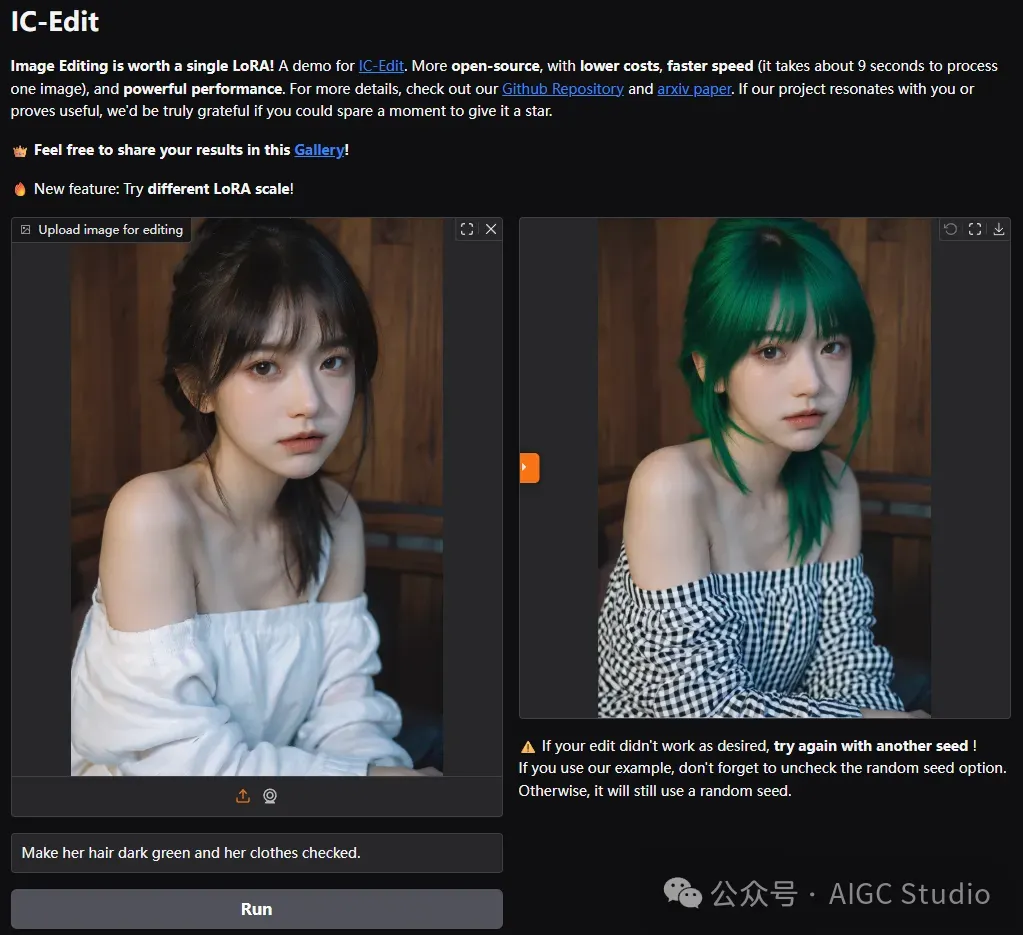
浙江大学联合哈佛大学提出一种高效的基于指令的图像编辑框架ICEdit,与以往的方法相比,ICEdit仅需1%的可训练参数(200M)和0.1% 的训练数据(50k),就展现出强大的泛化能力,能够处理各种编辑任务。

相比 Gemini、GPT4o 等商业模型,我们更加开源,成本更低,速度更快(处理一幅图像大约需要 9 秒),性能强大。使用ComfyUI-nunchaku,仅需 4 GB VRAM GPU 就足以尝试我们的模型!
泛化能力

与商业模型的比较
 与 Gemini、GPT-4O 等商业模型相比,我们的方法在人物 ID 保存和指令跟随方面与这些商业模型相当甚至更胜一筹。我们比它们更加开源,成本更低,速度更快(处理一张图片大约需要 9 秒),性能强大。
与 Gemini、GPT-4O 等商业模型相比,我们的方法在人物 ID 保存和指令跟随方面与这些商业模型相当甚至更胜一筹。我们比它们更加开源,成本更低,速度更快(处理一张图片大约需要 9 秒),性能强大。
与最先进的方法的比较

相关链接
- 论文:https://arxiv.org/abs/2504.20690
- 项目:https://github.com/River-Zhang/ICEdit
- 模型:https://huggingface.co/RiverZ/normal-lora/tree/main
- 试用:https://huggingface.co/spaces/RiverZ/ICEdit
论文介绍

基于指令的图像编辑能够通过自然语言提示实现稳健的图像修改,但当前方法面临着精度与效率之间的权衡。微调方法需要大量的计算资源和庞大的数据集,而无需训练的技术则难以满足指令理解和编辑质量。作者利用大规模扩散变换器 (DiT) 增强的生成能力和原生的语境感知能力来解决这一难题。解决方案引入了三项贡献:
- 一个语境编辑框架,利用语境提示实现零样本指令合规性,避免结构性变化;
- 一种 LoRA-MoE 混合调优策略,通过高效的自适应和动态专家路由增强灵活性,无需大量的再训练;
- 一种早期滤波器推理时间缩放方法,使用视觉语言模型 (VLM) 来尽早选择更优的初始噪声,从而提高编辑质量。
大量的评估证明了方法的优越性:它的性能优于最先进的方法,而与基线相比,只需要 0.1% 的训练数据和 1% 的可训练参数。这项工作建立了一种新的范例,可以实现高精度且高效的指令引导编辑。
方法概述
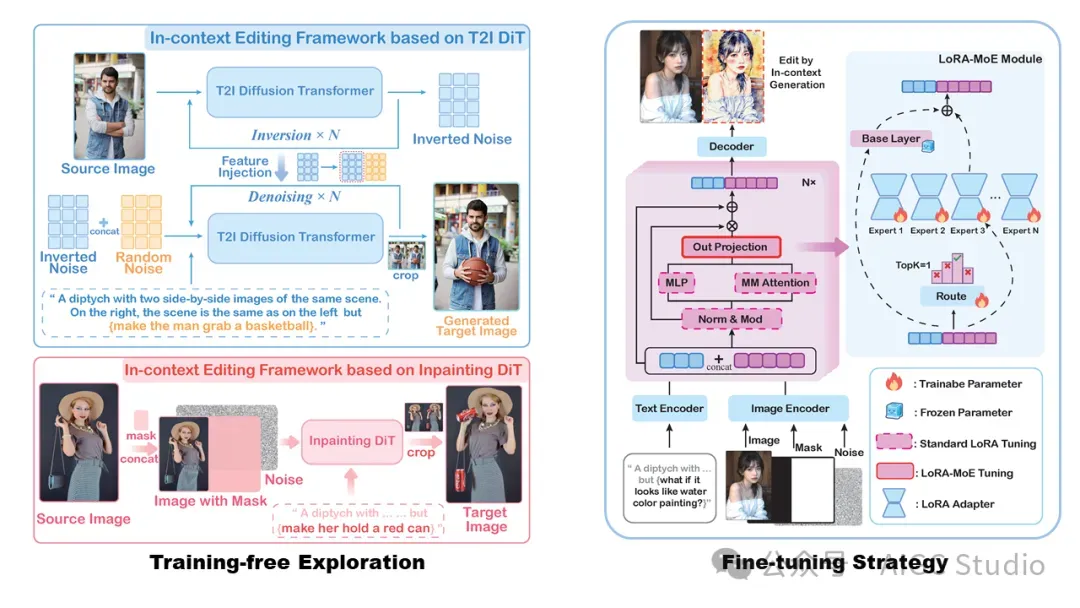 我们基于 DiT(例如 FLUX)实现了无需训练的上下文编辑范式,其中模型通过处理源图像(左图)旁边的“上下文提示”来生成编辑输出(双联画的右图)。虽然仍然存在持续的故障案例,但已取得的优势建立了一个稳健的基准,有助于高效地进行微调以提高精度。我们在 DiT 框架内实现了参数高效的 LoRA 适配器,并采用混合专家 (MoE) 路由,可在编辑过程中动态激活特定任务的专家。该适配器基于极少的公开数据(50K)进行训练,无需修改架构或进行大规模再训练,即可提高各种场景下的编辑成功率。我们还设计了一种推理时间扩展策略来提升编辑质量。更多详情,请参阅论文。
我们基于 DiT(例如 FLUX)实现了无需训练的上下文编辑范式,其中模型通过处理源图像(左图)旁边的“上下文提示”来生成编辑输出(双联画的右图)。虽然仍然存在持续的故障案例,但已取得的优势建立了一个稳健的基准,有助于高效地进行微调以提高精度。我们在 DiT 框架内实现了参数高效的 LoRA 适配器,并采用混合专家 (MoE) 路由,可在编辑过程中动态激活特定任务的专家。该适配器基于极少的公开数据(50K)进行训练,无需修改架构或进行大规模再训练,即可提高各种场景下的编辑成功率。我们还设计了一种推理时间扩展策略来提升编辑质量。更多详情,请参阅论文。
实验结果


结论
论文提出了一种基于 DiT 的新颖指令编辑方法 In-Context Edit,该方法能够以最少的微调数据提供最佳性能,从而实现效率和精度之间的完美平衡。首先探索了生成式 DiT 在无需训练的环境下的内在编辑潜力,然后提出了一种混合 LoRA-MoE 微调策略来提升稳定性和质量。此外还引入了一种推理时间扩展方法,使用 VLM 从多个种子中选择最优的早期输出,从而增强了编辑效果。大量的实验证实了提出方法的有效性,并展示了卓越的结果。


