数据

83岁用DeepSeek抢单,96岁凭AI挣养老钱!这群80+老人比你还会玩AI
存款60美元,欠款15000美元。 82岁的Luis Bautista仍要为养老努力工作。 他创办的科技公司,他对AI的学习热情,在推动他前行。

其实,扩散语言模型在最终解码之前很久,就已确定最终答案
随着扩散语言模型(DLM)在各个领域的快速发展,其已成为自回归(AR)模型有力的替代方案。 与 AR 模型相比,DLMs 的主要优势包括但不限于:高效的并行解码和灵活的生成顺序。 尽管 DLMs 具有加速潜力,但在实际应用中,其推理速度仍慢于 AR 模型,原因在于缺乏 KV-cache 机制,以及快速并行解码所带来的显著性能下降。

别误会00后了!美国千人调查揭秘:85%学生都用AI,首要目的不是偷懒
GenAI席卷全球,高校课堂成为最前沿的实验场。 有人担心学位贬值、课堂失守;有人则看到新技术催生的新机遇。 刚刚,国外的「Inside Higher Ed」发布了最新的调查。

R-Zero 深度解析:无需人类数据,AI 如何实现自我进化?
本文第一作者黄呈松 (Chengsong Huang) 是圣路易斯华盛顿大学的博士生,Google scholar citation 五百多次,目前的研究的兴趣是强化学习和大语言模型。 机器之心曾经报道过其之前工作 Lorahub 已经被引超过 250 次。 大型语言模型(LLM)的发展长期以来受限于对大规模、高质量人工标注数据的依赖,这不仅成本高昂,也从根本上限制了 AI 超越人类知识边界的潜力 。

DeepSeek、GPT-5带头转向混合推理,一个token也不能浪费
在最近的一档脱口秀节目中,演员张俊调侃 DeepSeek 是一款非常「内耗」的 AI,连个「1 加 1 等于几」都要斟酌半天。 在 AI 领域,这种情况被称为「过度思考」。 它的存在让 AI 大模型公司非常头疼,因为实在是太浪费算力了,那点订阅费根本 cover 不住。

数据科学新风口?三大环节搞定ML「资产」管理,VLDB'25最新教程抢先看!
大模型时代,模型、数据与各种「参数/脚本/许可证」等ML资产爆炸式增长,但真正能被发现、复用、合规使用的比例并不高,这正在成为AI生产力落地的「隐形天花板」。 以知名开源平台HuggingFace为例,平台目前托管超过150万个模型,每月还在新增约10万个模型,总数据存储量高达17PB。 然而超过半数的模型缺乏基本文档说明,不到8%的模型拥有明确的许可证。

当AI成为预言家:大数据时代,我们正在失去理解世界的能力吗?
最近,我在斯坦福大学的一篇文章中读到了神经科学家Grace Huckins的观点,她提出了一个令人深思的问题:"虽然强大的AI工具和海量数据集正在推动实际进步,但它们可能没有深化我们对宇宙的理解。 "这句话像一记重锤,敲在了我的思考深处。 在这个AI大爆炸的时代,我们每天都在惊叹于技术的进步:AlphaFold预测蛋白质结构的准确性超越了实验方法,大型语言模型能够写出看似有深度的文章,AI系统可以识别出人类肉眼无法察觉的模式...但是,这些进步真的让我们更理解这个世界了吗?
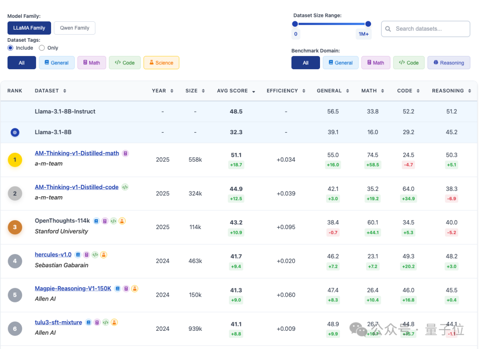
告别“炼丹玄学”:上海AI实验室推出首个大模型数据竞技场OpenDataArena
数据在AI时代的重要性已经不言而喻,但悬而未决的是——. 如何精确量化这些数据的价值、辨别其优劣? 为此,上海人工智能实验室OpenDataLab团队在数据领域持续深耕,正式推出了开放数据竞技场OpenDataArena。

享年101岁!AI之父明斯基的「反对者」走了,一生都在寻找另一种AI
8月10日,信息时代黎明的远见者——沃伦·布罗迪(Warren Brodey)在家中去世,享年101岁。 沃伦·布罗迪(1924-2025)他凭借其精神病学家的背景,就技术解放人类潜能方向提出了一系列影响深远的思想,在信息时代曙光初露时,为AI等革命性领域的研究铺平了道路。 布罗迪的一生充满了意想不到的转折:他曾参与由中情局资助的超感官知觉研究,曾旅居新英格兰的天体村,也曾在奥斯陆的一家铸铁厂担任工人。

AI来了!记者、UP主、写手,谁能逃过这场「灭绝浪潮」?
AI正在重新定义信息获取的入口和方式。 同时,原生AI新闻产品带来的用户体验与传统新闻截然不同。 一项研究显示,AI已经在世界各地的新闻编辑室中崭露头角。

竖切不行、斜切更糟?实验 1.9 万次,揭晓洋葱最佳切丁策略
洋葱,是餐桌上最普通的食材之一。 但在2021年,美国厨师兼美食作家 J. Kenji López-Alt 却把它带到了数学黑板上。

一句话,性能暴涨49%!马里兰MIT等力作:Prompt才是大模型终极武器
AI性能的提升,一半靠模型,一半靠提示词。 最近,来自马里兰大学、MIT、斯坦福等机构联手验证,模型升级带来的性能提升仅占50%,而另外一半的提升,在于用户提示词的优化。 他们将其称之为「提示词适应」(prompt adaptation)。

大模型训练新突破!“不对称”训练让AI学会自我反思,推理零开销
首次实现“训练-推理不对称”,字节团队提出全新的语言模型训练方法:Post-Completion Learning (PCL)。 在训练时让模型对自己的输出结果进行反思和评估,推理时却仅输出答案,将反思能力完全内化。 与目前主流的训练方式相比,这一创新方法不仅实现了模型能力的显著提升,更重要的是推理时完全零额外开销。

GPT-5编程成绩有猫腻!自删23道测试题,关键基准还是自己提的
别急着用GPT-5编程了,可能它能力没有你想象中那么强。 有人发现,官方测试编程能力用的SWE-bench Verified,但货不对板,只用了477个问题。 什么意思呢?

Attention Sink产生的起点?清华&美团首次揭秘MoE LLM中的超级专家机制
稀疏激活的混合专家模型(MoE)通过动态路由和稀疏激活机制,极大提升了大语言模型(LLM)的学习能力,展现出显著的潜力。 基于这一架构,涌现出了如 DeepSeek、Qwen 等先进的 MoE LLM。 然而,随着模型参数的迅速膨胀,如何高效部署和推理成了新的挑战。

让OpenAI只领先5天,百川发布推理新模型,掀翻医疗垂域开源天花板
刚刚,全球最强开源医疗模型发布,来自中国。 百川开源最新医疗推理大模型Baichuan-M2-32B,在OpenAI发布的Healthbench评测集上,超越其刚刚发布5天的开源模型gpt-oss-120b。 不仅以小博大,而且领先除GPT5以外所有的开源闭源前沿模型。

从捍卫者到引路人,上交&上海AI Lab提出LEGION:不仅是AI图像伪造克星,还能反哺生成模型进化?
本文由上海交通大学,上海人工智能实验室、北京航空航天大学、中山大学和商汤科技联合完成。 主要作者包括上海交通大学与上海人工智能实验室联培博士生康恒锐、温子辰,上海人工智能实验室实习生文思为等。 通讯作者为中山大学副教授李唯嘉和上海人工智能实验室青年科学家何聪辉。

代季峰陈天桥联手AGI首秀炸场!最强开源深度研究模型,GAIA测试82.4分超OpenAI
最强开源深度研究模型来了。 MiroMind ODR(Open Deep Research),来自代季峰加盟陈天桥的技术首秀。 首先,它做到了性能最强,GAIA测试结果更是达到了82.4分,超过了一众开源闭源模型,其中包括Manus、OpenAI的DeepResearch。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
大语言模型
字节跳动
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉