首次实现“训练-推理不对称”,字节团队提出全新的语言模型训练方法:Post-Completion Learning (PCL)。
在训练时让模型对自己的输出结果进行反思和评估,推理时却仅输出答案,将反思能力完全内化。
与目前主流的训练方式相比,这一创新方法不仅实现了模型能力的显著提升,更重要的是推理时完全零额外开销。
测试结果显示,PCL方法在保持推理效率的同时,显著提升了模型的输出质量和自我评估能力,为大语言模型训练开辟了全新技术路径。
下面通过实际的对话案例,直观展示PCL的训练和推理效果。例如,对于如下问题:
复制模型在训练时,会完整输出以下内容,并通过多目标优化同时提升其推理、评估能力:
复制在推理时,模型以<post>作为新的结束符,只需要输出推理部分的内容:
复制可以看到,模型在推理时完全不输出evaluation部分,从而无需任何额外的推理开销。而通过在训练时进行自我反思和评估,模型的实际能力也得到了提升,这一点在实验中得到了验证。
方法
1 突破性的“不对称训练”范式
传统语言模型训练存在一个根本性限制:训练和推理必须完全对称。
现有方法通常以结束符(EOS)作为序列终止点,模型的学习目标也仅限于预测到结束符为止的内容,形成了“训练什么就输出什么”的对称约束,就像学生考试时必须把所有思考过程都写在答卷上。然而,人类在完成答题后往往会进行检查,反思和评估自己的回答质量,而大模型却缺少了这个关键的自我反思环节。
PCL方法首次打破了这种对称性约束,实现了训练的创新,其核心思路简单而巧妙:
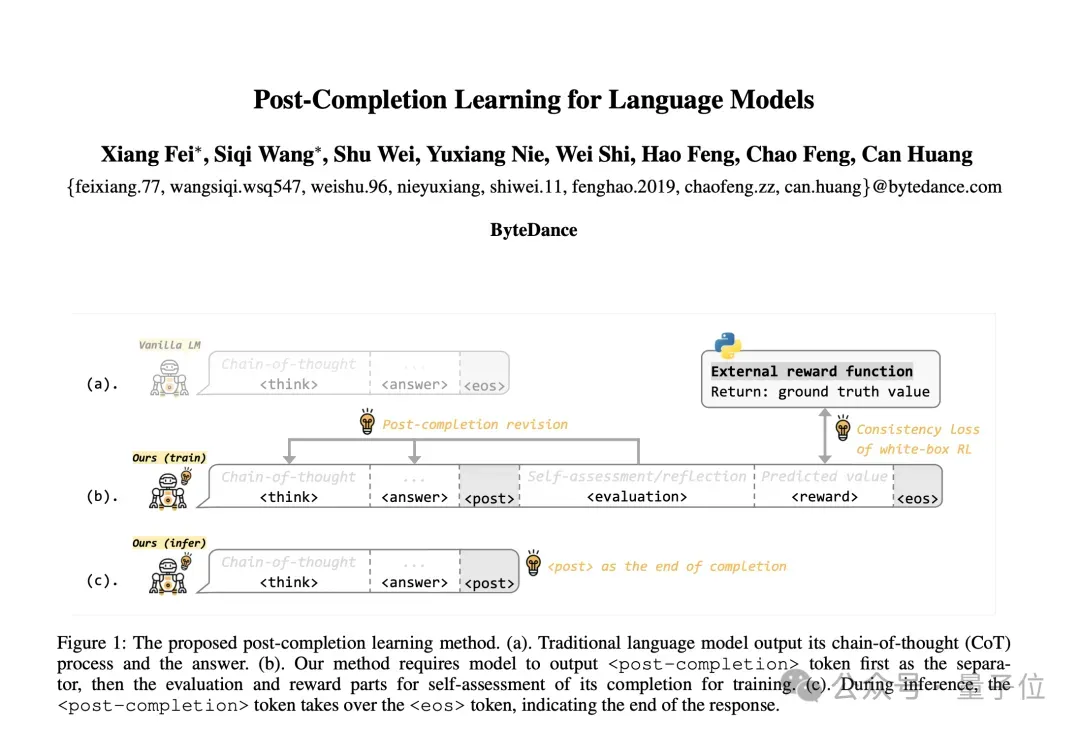
- 训练时:将原始的EOS替换为临时结束符,让模型继续输出自我评估和质量预测
- 推理时:模型在处直接停止,无需输出后续的评估部分
这样一来,模型在训练阶段学会了”内省”的能力,但部署时保持原有计算效率。实验结果表明,通过在训练时评估自己的答案,模型本身的回答能力也得到了提升。
PCL 方法示意图:(a) 传统方法以结束符作为训练的终点;(b) 方法在训练时,首先将其替换为临时结束符 ,然后在后面继续加入自我反思、自我评估的部分;(c) 在推理时,将临时结束符 作为新的结束符,作为输出的终止,从而避免了额外的推理开销。
2 白盒化强化学习:让AI学会“自我评价”
为了有效利用这一点,研究团队提出了另一项创新:实现了强化学习过程的白盒化。
这一点也是基于目前对强化学习的普遍认知:大模型依赖并被动接受外部的奖励信号,难以理解奖励函数的机制,其优化过程更像是一个黑盒,优化效果较差。
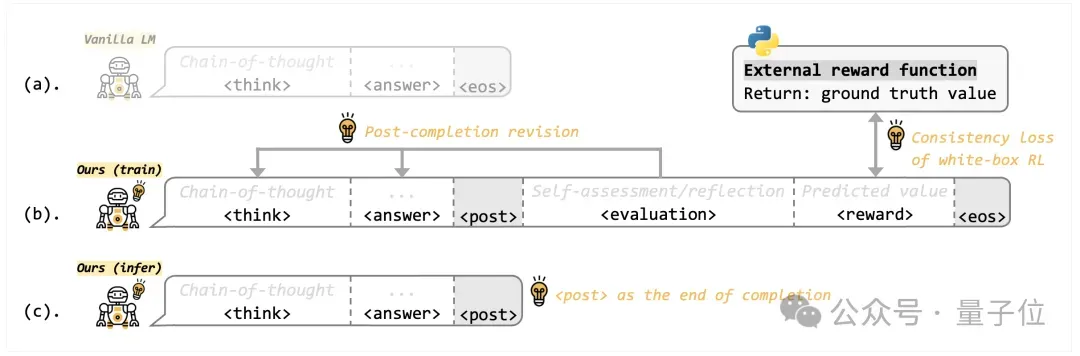
PCL的白盒化设计则截然不同:直接教会模型如何计算奖励,让模型主动进行自我评估,因此其训练过程完全透明可解释。利用模型自己输出的评估结果,与外部奖励函数的结果进行对齐,从而监督模型的评估能力。
就像从“老师打分”变成了“学生自己会打分”,模型不仅学会了做题,还学会了评分标准,知道应该从哪些角度去得分,从而实现更高效的优化。
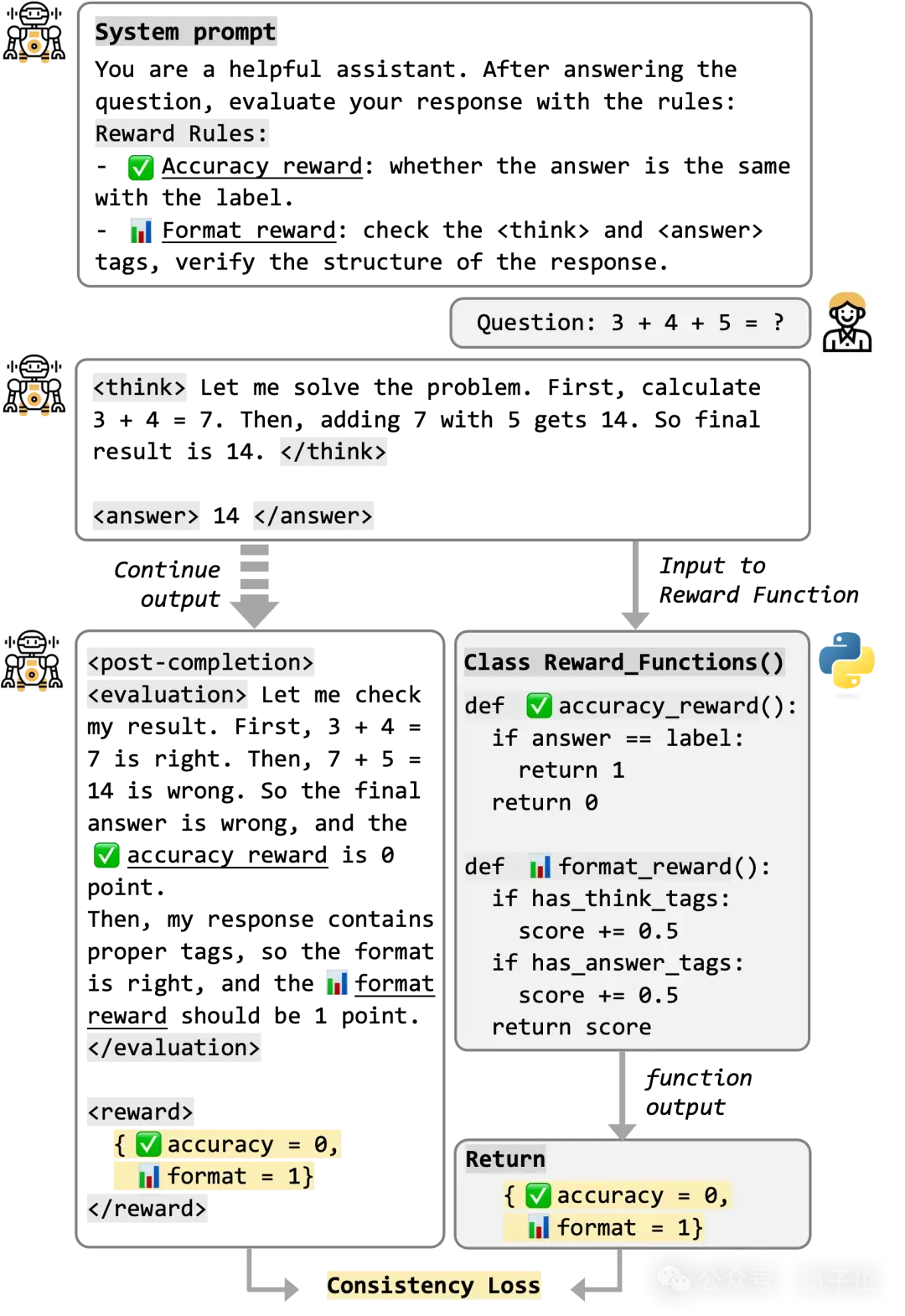
白盒化强化学习的对话示意图,教会模型如何计算奖励,并设计一致性奖励函数用于对齐
3 统一混合训练框架
在具体实现上,PCL 实现了统一 SFT + RL 训练框架,进行多目标的联合优化。这种混合训练范式也在最近的不少工作中得到验证。
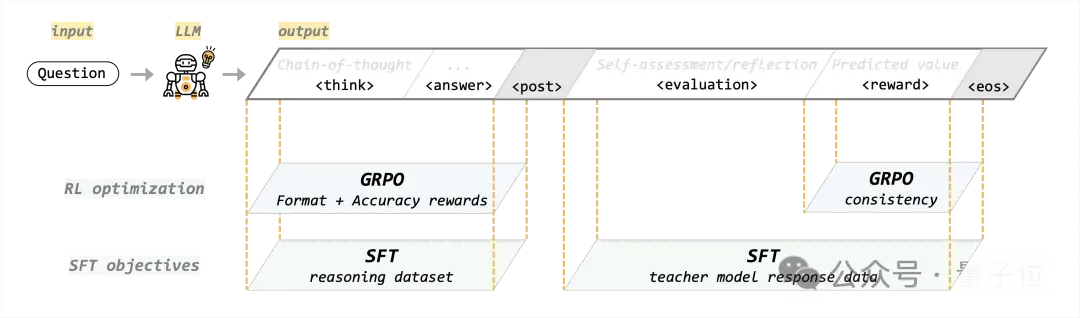
- 推理能力 SFT:使用推理数据集,专注于 think + answer 部分,训练模型回答问题的能力
- 评估能力 SFT:使用教师输出进行蒸馏,专注于 evaluation + reward 部分,让模型基于完整推理过程进行评估
- 推理能力 GRPO:使用 accuracy + format 奖励函数,验证答案与格式的正确性。奖励函数因任务而异,可以拓展到更多的场景
- 评估能力 GRPO:设计了一致性奖励函数,指导模型预测出准确的奖励得分
各优化目标在统一框架中混合训练,将监督微调(SFT)和强化学习优化(GRPO)完美融合,实现多目标协同优化。
实验结果
作者设置了多种实验,验证了PCL的各组成部分的效果:
- 对比 SFT, RL 等经典训练方法,对比混合训练策略
- 消融验证 PCL 中的评估 SFT、一致性奖励函数的效果
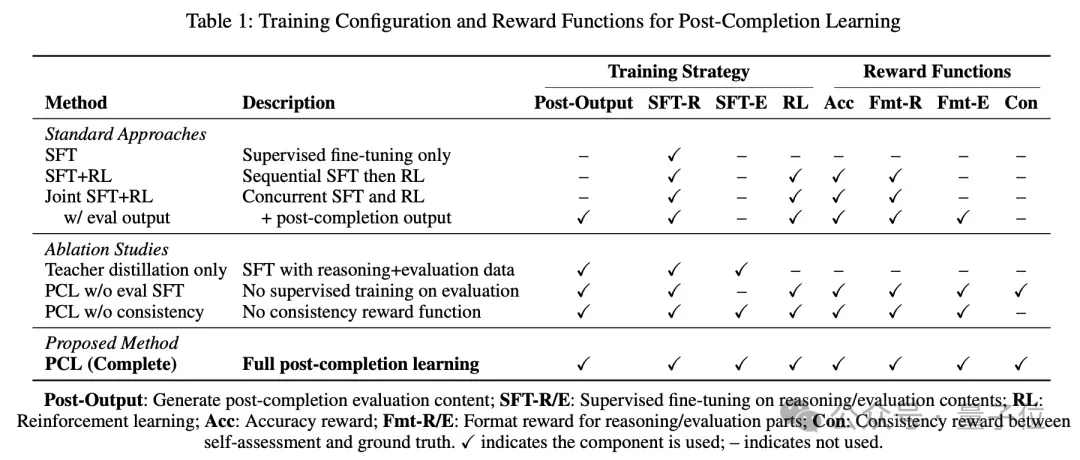
实验结果上,论文在数学推理、逻辑推理两个领域的数据集,分别在 Qwen-2.5 和 Llama-3.2 不同尺寸的模型上都取得了普遍正向的指标提升,消融实验也验证了方法并非完全依赖蒸馏或强化学习策略,而是有效利用了自我评估,提升了模型的内在推理能力。
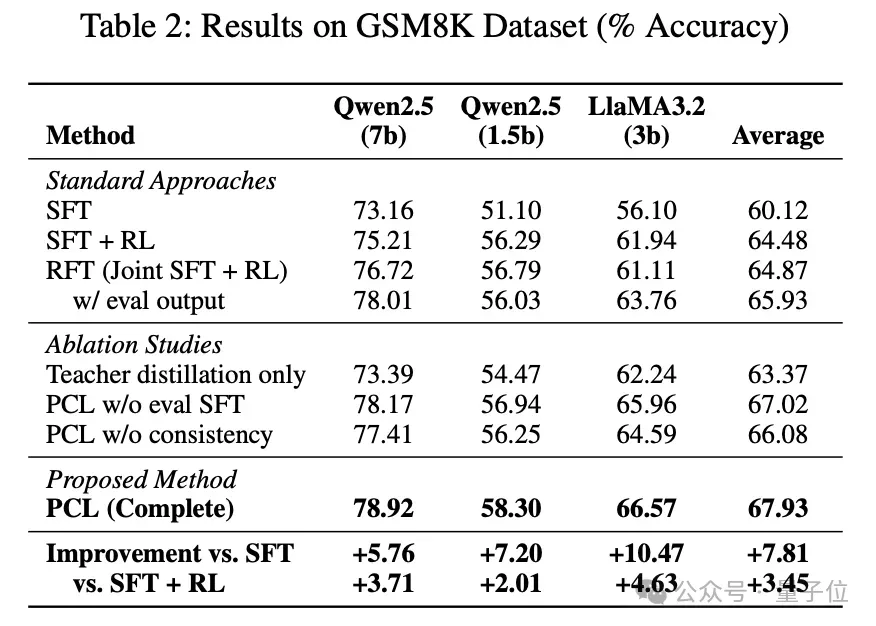
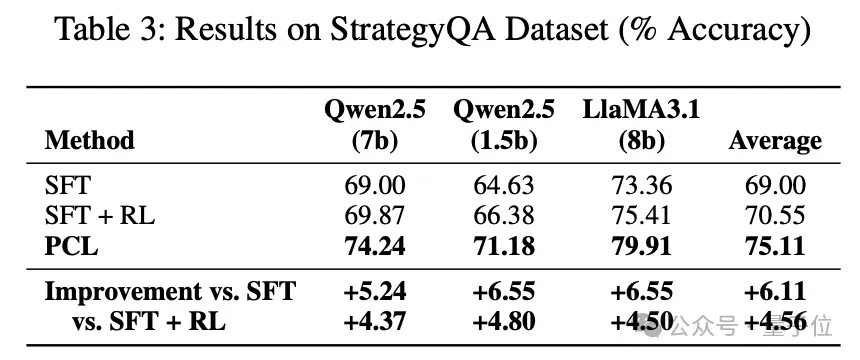
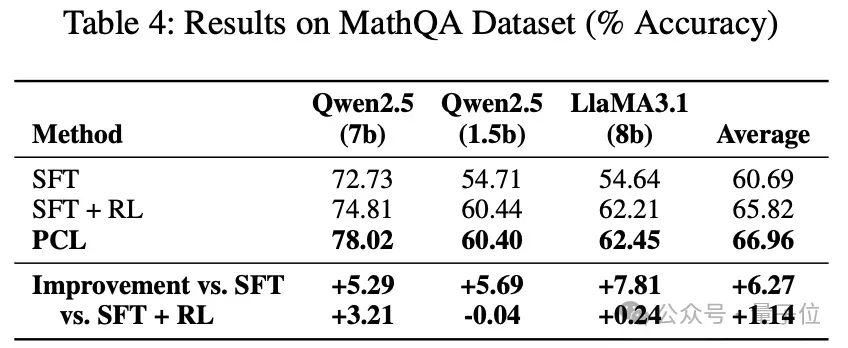
结论
PCL方法的提出,为语言模型训练领域带来了三个重要启示:
- EOS后空间的价值:被忽视的训练空间蕴含巨大潜力,自我评估能够提升推理能力
- 白盒化RL的可能:强化学习不必是“黑盒子”,提升可解释性可以学得更好
- 训练推理解耦:复杂训练+简洁推理的平衡,“不对称”的训练+推理过程
这种不对称训练的新范式,既能显著提升训练效果,又无需额外推理开销,有望成为未来大模型训练的标准做法。
论文链接:https://arxiv.org/abs/2507.20252


