数据在AI时代的重要性已经不言而喻,但悬而未决的是——
如何精确量化这些数据的价值、辨别其优劣?
为此,上海人工智能实验室OpenDataLab团队在数据领域持续深耕,正式推出了开放数据竞技场OpenDataArena。

展开来说,在海量的SFT(监督式微调)后训练数据面前,研究者们常常陷入“黑盒式”的困境:不清楚哪些数据真正有用,也难以系统性地评估和比较不同的数据集。
而OpenDataArena,正是一个为数据价值而生的“竞技场”,致力于将数据质量的评估从“玄学”变为“科学”。
团队希望通过一个公平、公开、透明的平台,首次正式尝试回答“如何验证数据价值”这一核心问题。
它不仅提供了一个直观的数据评测榜单,更构建了一套完整可复现的数据价值验证体系——
通过一套训评一体化的开源工具,让不同数据集在同等条件下公平“竞技”,用模型效果作为衡量数据价值的最终标准。
同时,通过开发多维度评分工具,对数据进行精细化“体检”,让数据价值不再是模糊的“黑盒”。
下面详细来看。
OpenDataArena首次系统性地探究“如何评价数据质量”这个难题。
为此,该项目构建了“开放数据竞技场”,并配套开发了一整套数据价值验证工具。
该平台的核心成果包括:
- OpenDataArena平台:一个公平、公开、透明的SFT后训练数据价值评测平台,涵盖一个多领域、可视化的数据竞技榜单。
- 多维度数据打分:平台从几十种维度对已有数据进行精细化打分,并已开源了部分评分数据,便于研究员们后续直接下载使用,避免重复API调用。
- 训评一体化工具:团队开源了整套数据训练、评估以及数据打分工具,让价值验证过程可复现、可扩展。
OpenDataArena为以下几类核心需求提供了实际的解决方案:
1、对数据质量的评估与筛选:帮助模型训练者和数据研究者快速识别并筛选出高质量数据集,摆脱盲目试错,高效赋能模型训练与应用。
2、对数据生成的指导与优化:为数据合成的研究者提供多维度的评分数据和工具,助力他们寻找高价值的“种子数据”,为生成更优质的合成数据提供指导。
3、对数据价值的深入洞察:赋能学术研究人员探索数据特征与模型效果的内在关联,为数据选择、数据生成等前沿研究提供坚实的数据支持和客观的评估依据。
平台目前已覆盖4+领域、20+基准测试、20+数据评分维度,处理了100+数据集,超过20M+数据样本,并完成了600+次模型训练、10K+次模型评估,这些指标都在不断增长。

OpenDataArena的核心理念,就是让数据价值在实战中得到验证。
该平台通过一套公平、公开、可复现的大模型训练与评测机制,来比较不同训练数据集的优劣。
那么,OpenDataArena具体是如何运作的呢?
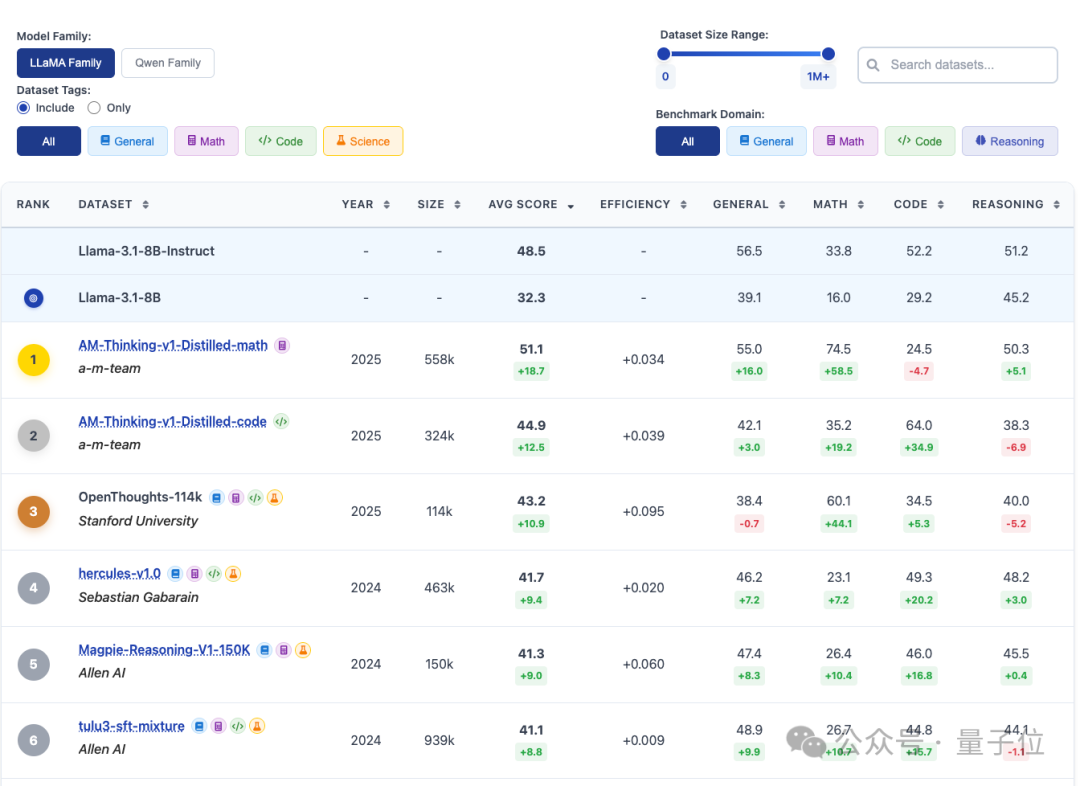
1、数据集选择
平台覆盖了来自通用、数学、代码、科学等多个领域的后训练数据集。这些数据来自于HuggingFace并且有一定的下载和关注度,不仅具有代表性,而且具备时效性,确保了评测的现实意义。
2、模型选择
平台采用了社区中最常用、最具代表性的Llama3.1和Qwen 2.5的7B版本作为基准模型,它们代表了真实的学术和工业应用场景,同时尽可能反映了最多场景中实际使用的模型大小的数据性能。
3、训练与评估
平台采用标准化训练配置,训练环节采用广受认可的LLaMA-Factory框架,并且严格采用最常见的训练参数。
测试环节使用OpenCompass进行全面评估,在测试环节的参数设置上,团队进行了大量预实验,确保推理模板和评估器等细节都经过了精心的优化,排除外部干扰,让测试结果能更公平、公正地反映训练数据集的真实质量。
4、评测集全面覆盖
平台选择了通用、数学、代码、长链推理等多维度基准测试集,力求全面、客观地反映单领域数据质量,以及混合领域的数据综合质量。
最终,OpenDataArena数据竞技场诞生,通过数据评测榜单直观的给出数据“优秀”程度。
平台希望能够帮助模型训练者和数据研究者快速识别并挑选高质量数据集,降低试错成本,赋能模型训练与应用。
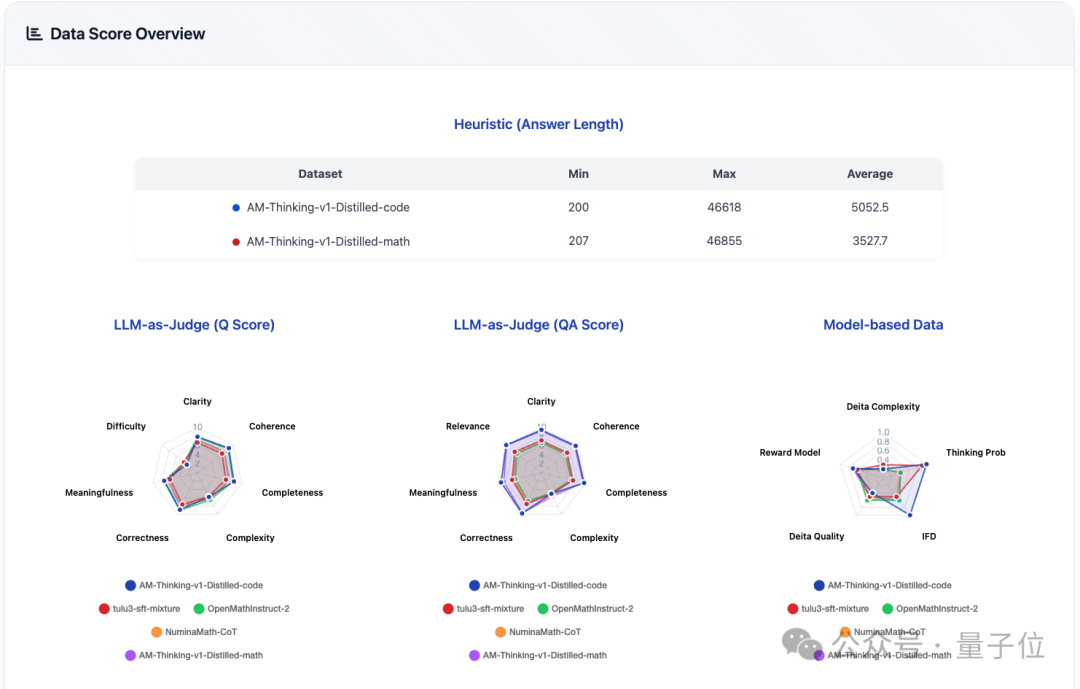
除了通过训练模型得到下游任务的表现来直接反应数据的质量之外,OpenDataArena还通过多维度的客观评分工具,来对数据本身进行细致的“体检”,这些客观评分指标得到了学界和业界的广泛认可。
1、20+维度,精准画像
平台对代表性的数据集整体,以及数据集中的每一条数据,都进行了细致的多维度打分。
不论是直接选用整个数据集,还是用于挑选优质子数据,都方便操作。同时,无论是指令数据,还是指令-响应对数据,平台都从不同方面提供了相应的评分。
2、多源评分,深度剖析
平台的评分工具整合了多种维度评估方法,包括基于模型的评估(Model-based Evaluation,如IFD)、大模型作为评委(LLM-as-a-Judge,如准确性、复杂度)和启发式方法(Heuristic,如回复响应长度)。
这些维度涵盖了数据的常见评价指标,为数据的价值提供了丰富的量化视角。
3、开源评分数据
团队已完成对超过15M+数据的多维度评分,并已开源这些数据评分结果。
对于需要依赖常见评价指标开展数据筛选、种子数据生成等任务的科研用户而言,这不仅极大降低了打分成本,还有效避免了重复的API调用,从而节省了实际开销,可谓一项极其宝贵的资源。
通过上述努力,平台为数据合成、数据筛选的研究者提供了多维度的评分数据和工具,助力他们寻找高价值的“种子数据”,最终为生成更优质、更高价值的数据提供了直接的帮助。
为了“公平、公正、公开”的OpenDataArena平台的设计原则,同时也为了让更多人能参与到数据价值验证中来,真实地评价数据的质量,OpenDataArena团队将整个平台的核心工具都进行了开源。
包括基于模型的训练评测工具,以及客观的多维度数据评价打分工具,所有的细节能在完整的OpenDataArena-Tool中找到说明。

- 训评一体化工具
平台基于主流的LLaMA-Factory训练框架,以及评测端知名的OpenCompass框架,打造了一套端到端的训练与评测工具,给出了所有的配置和流程复现脚本,确保了评估实验的结果可复现性与公平性。
相关的设置都尽可能与当前的主流研究工作、以及其余开源工具进行了对齐,保证了结果的公平公正可比。
具体的说明可以在配置详情和工具说明中,找到所有细节。
- 多维度数据打分工具
平台对于数据评价的打分工具也在持续完善中。
目前已实现的大部分评估维度打分工具均已开源,并提供了详细的使用教程。不管是单个维度的数据评估,还是所有已支持的数据评估维度,用户都可以在官方wiki文档中了解到如何使用这些工具,并为自己的数据进行“体检”。
同时,团队还在持续优化支持更多的数据打分维度,为用户提供更多维度的数据打分选择。
通过上述的工具开源,OpenDataArena团队希望提供一个开放共享的数据价值评估平台,让所有用户都能参与到数据评估中来,并为产生真正的高价值数据共同努力。

据团队介绍,目前OpenDataArena已经完成的仅仅只是冰山一角,也只是对数据价值验证的开始。
项目未来也有更多的计划,例如下面这些:
- 扩展验证范围: 逐步支持多模态等更复杂的数据类型;
- 深化应用场景: 扩展至医疗、金融、科学等更多专业领域;
- 保持新鲜度: 每月更新数据竞技场,确保数据排行榜的及时性。
团队认为,数据价值的验证需要社区的共同努力,上述计划也非常需要科研社区的力量来共同参与。
感兴趣可以进一步关注。
地址:https://opendataarena.github.io/index.html 工具:https://github.com/OpenDataArena/OpenDataArena-Tool 数据:https://huggingface.co/OpenDataArena
— 完 —


