随着扩散语言模型(DLM)在各个领域的快速发展,其已成为自回归(AR)模型有力的替代方案。与 AR 模型相比,DLMs 的主要优势包括但不限于:高效的并行解码和灵活的生成顺序。
尽管 DLMs 具有加速潜力,但在实际应用中,其推理速度仍慢于 AR 模型,原因在于缺乏 KV-cache 机制,以及快速并行解码所带来的显著性能下降。
本文,来自香港理工大学、达特茅斯学院等机构的研究者尝试从一个不同的角度来加速 DLMs 推理,这一思路源于一个长期被忽视却极具潜力的现象:早期答案收敛。

- 论文标题:Diffusion Language Models Know the Answer Before Decoding
- 论文地址:https://arxiv.org/pdf/2508.19982
- 项目地址:https://github.com/pixeli99/Prophet
通过深入分析,研究者观察到:无论是半自回归重掩码还是随机重掩码场景下,有极高比例的样本在解码早期阶段即可获得正确解码。这一趋势在随机重掩码中尤为显著,以 GSMK 和 MMLU 数据集为例,仅需半数优化步骤即可分别实现 97% 和 99% 的样本正确解码。
受此发现启发,该研究提出了 Prophet,一种无需训练的快速解码策略,该策略专为利用早期答案收敛特性而设计。Prophet 通过持续监控解码过程中 top-2 答案候选之间的置信度差距,自适应地判断是否可安全地一次性解码剩余所有 token。
实验表明,该方法在保持高质量生成效果的同时,实现了显著的推理加速(最高达 3.4 倍)。
方法介绍
Prophet 是一种无需训练的快速解码方法,用来加速扩散语言模型的生成。它的核心思路是:在模型预测结果趋于稳定时,一次性提交所有剩余 token 并提前生成答案,这一过程被称为早期提交解码(Early Commit Decoding)。与传统的固定步数解码不同,Prophet 会在每一步主动监测模型的确定性,从而能够即时做出是否终止解码的决策。
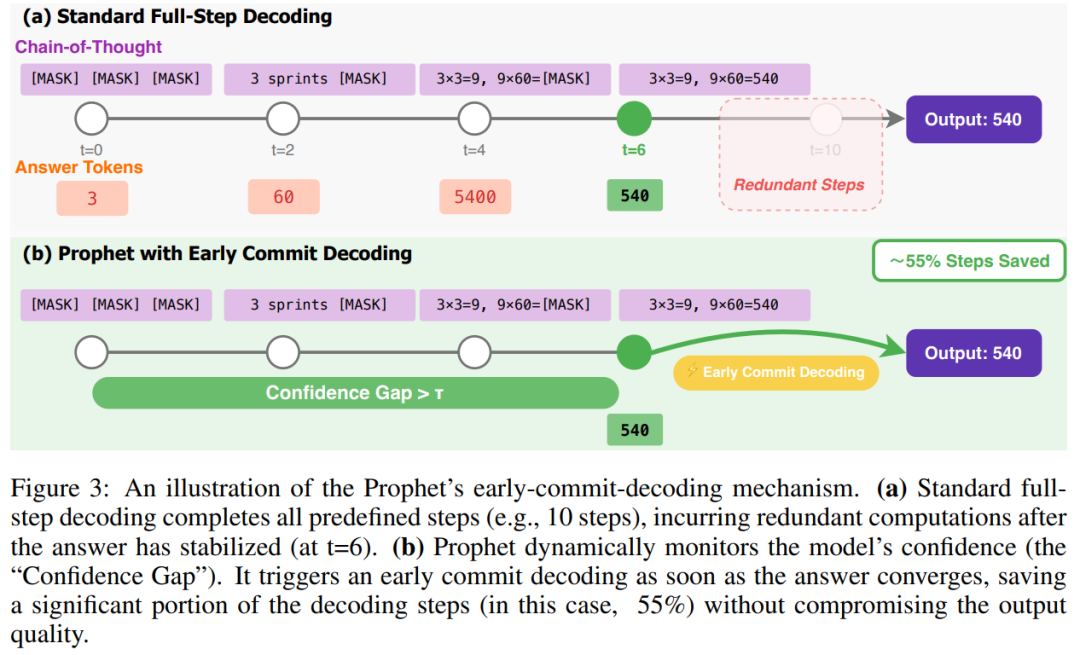
早期提交解码。何时终止解码循环的决定可以定义为最优停止问题。在每一步,都必须在两种互相冲突的成本之间权衡:继续执行额外细化迭代的计算成本,与因过早决定而可能带来错误的风险。计算成本取决于剩余步数,而错误风险则与模型的预测置信度呈负相关,其中「置信差距」可作为其稳健指标。
算法 1 概述了完整的 Prophet 解码过程:

实验
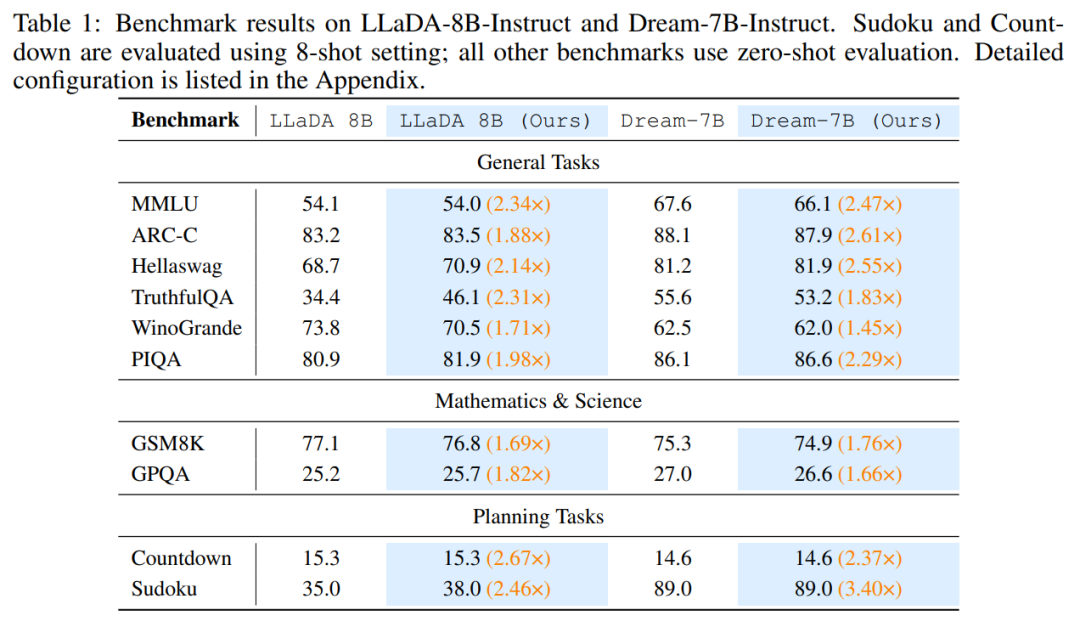
实验结果如表 1 所示。
在通用推理任务上,Prophet 展现了与完整基线相当甚至更优的性能。例如,在使用 LLaDA-8B 时,Prophet 在 MMLU 上达到 54.0%,在 ARC-C 上达到 83.5%,两者在统计上均与完整的 50 步解码结果相当。
更有趣的是,在 HellaSwag 上,Prophet(70.9%)不仅超过了完整基线(68.7%),还优于半步基线(70.5%),这表明早期提交解码能够避免模型在后续带噪声的精炼步骤中破坏已正确的预测。
同样地,在 Dream-7B 上,Prophet 在各项基准测试中依然保持了竞争力:在 MMLU 上达到 66.1%,而完整模型为 67.6%,仅有 1.5% 的微小下降,但带来了 2.47 倍的速度提升。
在更复杂的数学和科学基准测试上,Prophet 同样展现了其可靠性。以 GSM8K 数据集为例,基于 LLaDA-8B 的 Prophet 达到 76.8% 的准确率,几乎与完整基线的 77.1% 相当,并且优于半步基线的 76.2%。
总而言之,实证结果强有力地支持了本文的核心假设:扩散语言模型往往在最终解码步骤之前很早就已经确定了正确答案。
Prophet 成功利用了这一现象,通过动态监测模型预测的置信度,一旦答案趋于稳定,便立即终止迭代精炼过程,从而在几乎不影响任务性能的情况下显著节省计算开销,在某些场景下甚至还能提升表现。这与静态截断方法形成了鲜明对比,后者存在过早终止解码、从而损害准确率的风险。
因此,Prophet 提供了一种稳健且与模型无关的解决方案,有效加速 DLM 的推理过程,提升了其在实际应用中的可行性。
了解更多内容,请参考原论文。


