本文第一作者黄呈松 (Chengsong Huang) 是圣路易斯华盛顿大学的博士生,Google scholar citation 五百多次,目前的研究的兴趣是强化学习和大语言模型。机器之心曾经报道过其之前工作 Lorahub 已经被引超过 250 次。
大型语言模型(LLM)的发展长期以来受限于对大规模、高质量人工标注数据的依赖,这不仅成本高昂,也从根本上限制了 AI 超越人类知识边界的潜力 。《R-Zero:从零数据中自我进化的推理大模型》提出了一种全新的范式,旨在打破这一瓶颈。该研究设计了一个名为 R-Zero 的全自主框架,使模型能够从零开始,通过自我驱动的协同进化生成课程并提升推理能力,为通往更自主的人工智能提供了一条值得深入探讨的路径。
《R-Zero》论文的核心,是构建一个能从「零数据」开始自我进化的 AI 框架 ,主要依赖于两个 AI 角色 挑战者(Challenger)和 解决者(Solver)。

- 论文链接: https://www.arxiv.org/abs/2508.05004
- 项目代码: https://github.com/Chengsong-Huang/R-Zero
- 项目主页: https://chengsong-huang.github.io/R-Zero.github.io/
挑战者 - 解决者的协同进化
R-Zero 的架构核心是从一个基础 LLM 出发,初始化两个功能独立但目标协同的智能体:挑战者(Challenger, Qθ)和解决者(Solver, Sϕ)。
- 挑战者 (Challenger):其角色是课程生成器。它的优化目标并非生成绝对难度最高的问题,而是精准地创造出位于当前解决者能力边界的任务,即那些最具信息增益和学习价值的挑战 。
- 解决者 (Solver):其角色是学生。它的目标是解决由挑战者提出的问题,并通过这一过程持续提升自身的推理能力 。
这两个智能体在一个迭代的闭环中协同进化,整个过程无需人类干预 :
1. 挑战者训练:在当前冻结的解决者模型上,挑战者通过强化学习进行训练,学习如何生成能使解决者表现出最大不确定性的问题。
2. 课程构建:更新后的挑战者生成一个大规模的问题池,作为解决者下一阶段的学习材料。
3. 解决者训练:解决者在这个由挑战者量身定制的新课程上进行微调,提升自身能力。
4. 迭代循环:能力增强后的解决者,成为下一轮挑战者训练的新目标。如此循环往复,两个智能体的能力共同螺旋式上升。
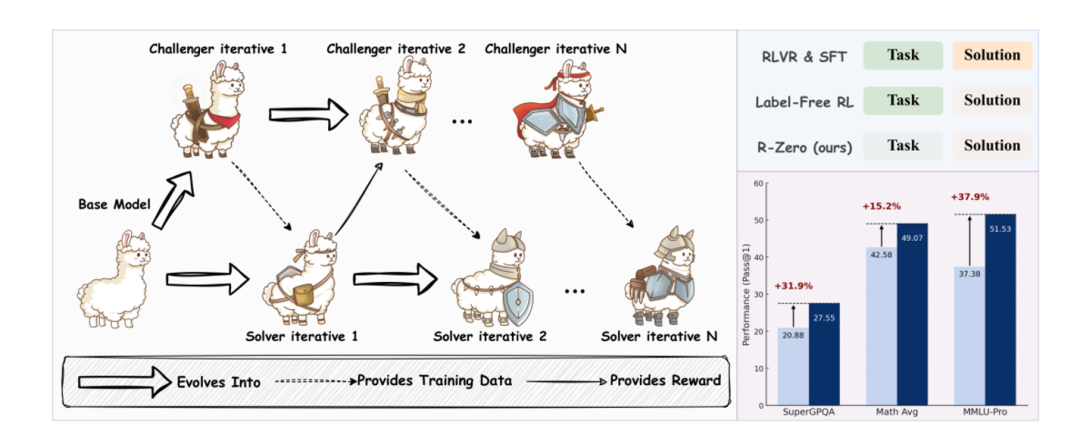
这是一个完全封闭、自我驱动的进化循环。在这个过程中,AI 自己生成问题,自己生成用于学习的「伪标签」,自己完成训练,完全不需要任何外部人类数据的输入。
具体实现方法
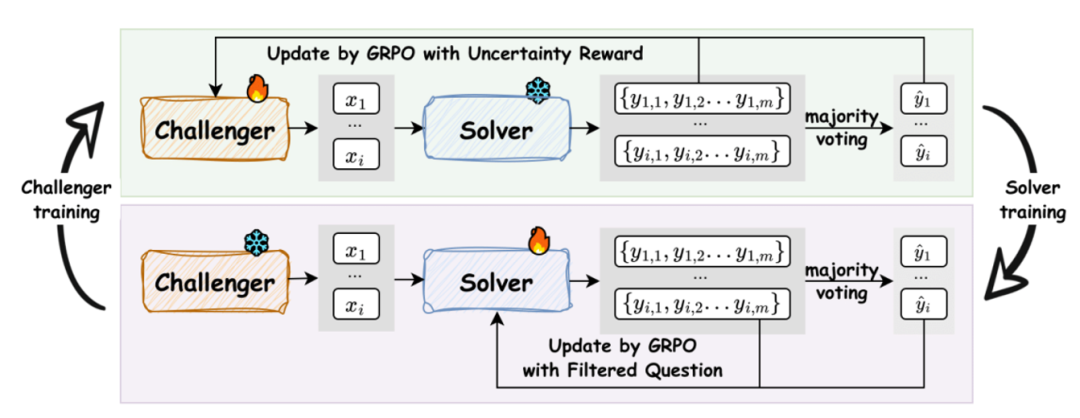
由于没有外部「标准答案」,解决者必须自我生成监督信号。
- 伪标签生成:采用自我一致性(self-consistency)策略。对于每个问题,解决者会生成多个(例如 10 个)候选答案,其中出现频率最高的答案被选为该问题的「伪标签」(pseudo-label)。
- 过滤器:这是框架设计的关键一环。并非所有生成的问题都被用于训练,只有那些解决者经验正确率 p^i 落在特定「信息带」内(例如,正确率在 25% 到 75% 之间)的问题才会被保留 。该过滤器起到了双重作用:
1. 难度校准:显式地剔除了过易或过难的任务。
2. 质量控制:一致性极低的问题(例如 10 次回答各不相同)往往是定义不清或逻辑混乱的,该机制能有效过滤掉这类噪声数据。消融实验证明,移除该步骤会导致模型性能显著下降 。
为了生成高效的课程,挑战者的奖励函数由三部分构成 :
- 不确定性奖励 (Uncertainty Reward):这是奖励函数的核心。其公式为 runcertainty=1−2∣p^(x;Sϕ)−1/2∣,其中 p^ 是解决者对问题 x 的经验正确率。当解决者的正确率接近 50% 时,奖励最大化。这一设计的理论依据是,此时学习者的学习效率最高,每个样本带来的信息增益也最大 。
- 重复惩罚 (Repetition Penalty):为保证课程的多样性,框架利用 BLEU 分数来衡量批次内问题的相似度,并对过于相似的问题施加惩罚 。
实验结果与分析
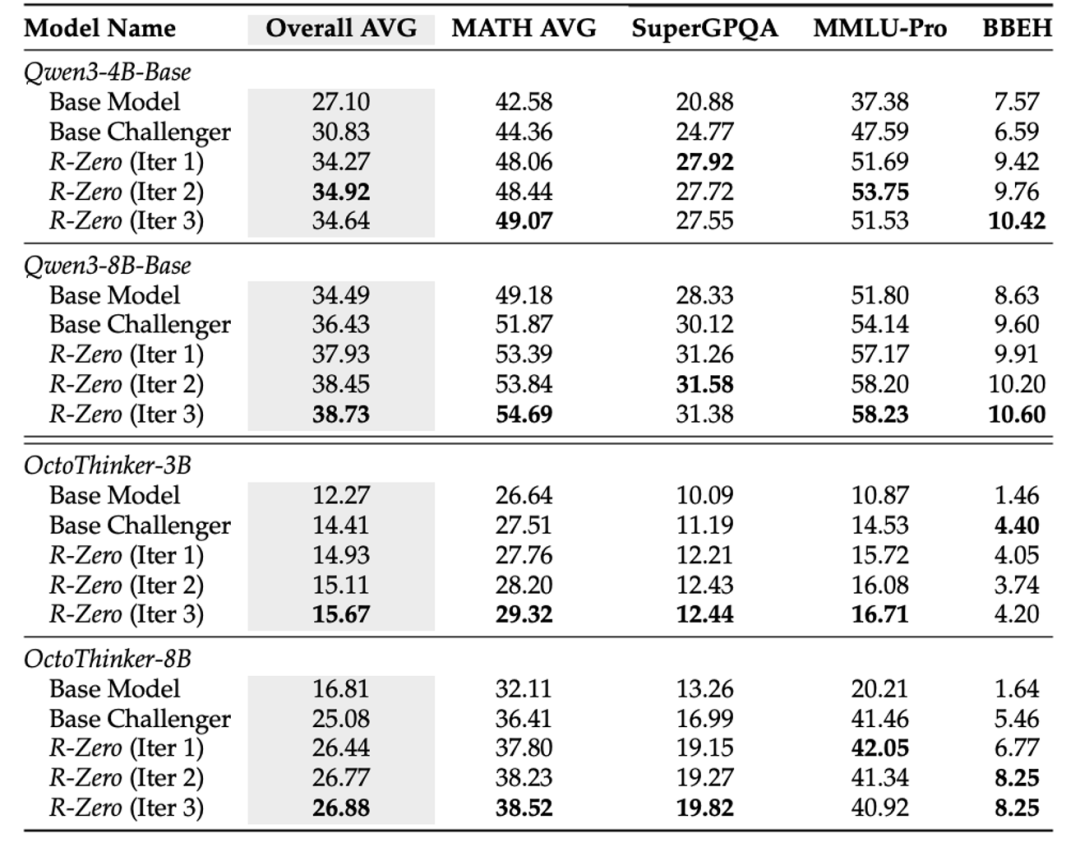
数学推理能力显著提升:经过三轮自我进化,Qwen3-8B-Base 模型在多个数学基准测试上的平均分从 49.18 提升至 54.69(+5.51)。
向通用领域的强大泛化能力:尽管训练任务集中于数学,但模型的核心推理能力得到了泛化。在 MMLU-Pro、SuperGPQA 等通用推理基准上,Qwen3-8B-Base 的平均分提升了 3.81 分 。这表明 R-Zero 增强的是模型底层的通用能力,而非特定领域的知识记忆。
与人类数据的协同效应
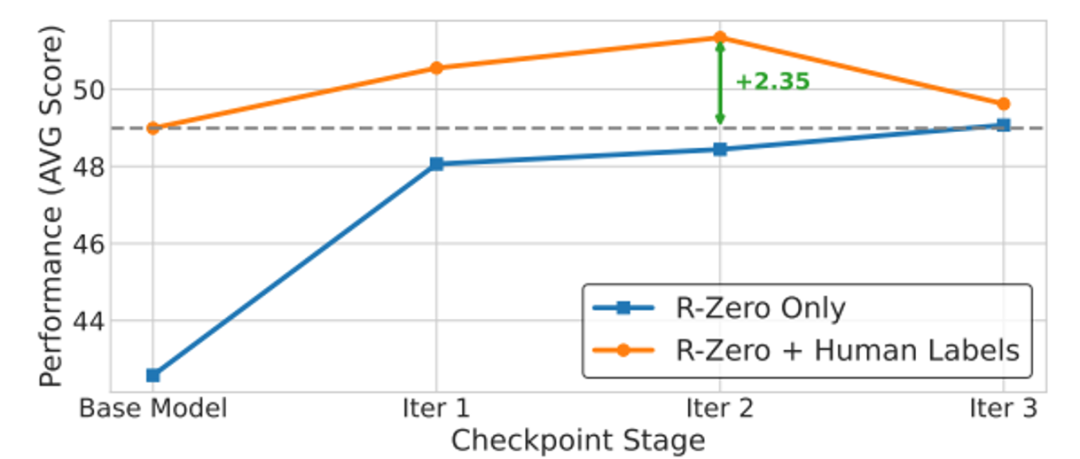
实验证明,先经过 R-Zero 训练的基础模型,再使用人类标注数据进行监督微调,能达到比直接微调更高的性能。这说明 R-Zero 可以作为一种高效的中间训练阶段,最大化人类标注数据的价值 。
核心局限与未来展望
尽管成果显著,R-Zero 框架也揭示了其内在的挑战和局限性。
- 伪标签准确率的衰减:这是该框架最核心的挑战。分析表明,随着课程难度在迭代中提升,由自我一致性生成的伪标签的真实准确率,从第一轮的 79.0% 系统性地下降到了第三轮的 63.0% 。这意味着模型在后期学习的监督信号中包含了更多的噪声。如何在这种难度与质量的权衡中找到稳定点,是决定该框架能否长期进化的关键。
- 领域局限性:当前框架高度依赖于那些存在客观、可验证正确答案的领域(如数学)。对于评估标准主观、解决方案多元的任务(如创意写作、战略规划),基于多数投票的自我监督机制将难以适用 。


