AI

人工智能和知识图谱二:构建和使用知识图谱的工具包和算法
一、知识表示标准RDF 和 SPARQL许多知识图谱的核心是资源描述框架 (RDF),它是 W3C 标准,用于以主语-谓语-宾语三元组的形式表示信息。 RDF 提供了一个灵活的图形数据模型,其中每个三元组(例如Alice worksAt CompanyX)都断言资源之间的关系。 它带有形式语义(RDF Schema、OWL 本体),可实现丰富的知识建模(例如类层次结构、域/范围限制)。

MARFT:多智能体协作与强化学习微调的协同进化
大家好,我是肆〇柒。 今天,继续 RL 相关话题,我们来探讨一个在人工智能领域极具应用潜力的话题 —— Multi-Agent Reinforcement Fine-Tuning(MARFT)。 这个概念融合了大型语言模型(LLM)、多智能体系统(LaMAS)和强化学习(RL)的精华,为解决复杂任务提供了全新的视角和方法论。

人工智能和知识图谱一:人工智能中知识图谱的概述
知识图谱 (KG) 是由现实世界实体(节点)及其相互关系(边)组成的结构化网络,以机器可读的形式对知识进行编码。 在人工智能领域,知识图谱是语义理解、推理和数据集成的强大工具。 它们为人工智能系统提供上下文,通过链接不同的数据源并揭示隐藏的关系,实现更易于解释、更准确的决策。

AI投顾时代:你是否信任 “机器人理财师”?
在科技飞速发展的今天,人工智能(AI)早已不是科幻电影里的概念,它正在悄然渗透进我们的生活。 在与财富息息相关的金融领域,当 “机器人理财师” 开始为你规划资产,你会选择信任吗? 我们该拥抱效率,还是警惕失控?

AI Agents vs Agentic AI:有何区别?为何如此重要?
如果你最近一直在关注 AI,你可能听说过 “AI Agents” 和 “Agentic AI” 这两个术语。 虽然它们听起来像是高深的科技术语,但实际上指的是两种不同类型的人工智能,它们都对我们的世界产生了巨大的影响。 它们究竟是什么?

AI Agent 五大工作模式详解
在AI Agent的架构设计中,工作模式决定了智能体如何规划、执行任务并优化自身行为。 本文将深入解析五大主流工作模式:提示链 (Prompt Chaining)、路由 (Routing)、并行化 (Parallelization)、协调者-工作者 (Orchestrator-Workers) 和 **评估者-优化者 (Evaluator-Optimizer)**,通过技术图解与实例揭示其运作机制。 一、提示链 (Prompt Chaining):分步拆解的思维链核心思想:将复杂任务拆解为顺序执行的子任务链,前一步输出作为后一步输入,形成推理流水线。

构建强大AI Agent的关键 = Pydantic AI + MCP + Advanced Web Scraping
引言在文中,我将展示一个超快速教程,教你如何使用 Pydantic AI、MCP 和高级网页抓取技术,构建一个强大的智能聊天机器人,适用于商业或个人用途。 MCP 逐渐被接受,因为它是一个开放标准。 我制作了一些非常酷的视频,你一定会喜欢。

AI辅助编程工具深度评测与企业选型指南
今天继续分享Google DeepResearch的AI编程工具研发分析报告。 具体的提示语如下:请对Cursor,Winsurf, Copilot,Augument 四款AI辅助编程工具进行详细分析和研究和评测。 需要从功能(核心是编程能力,上下文长度支持等),效率性能,质量,成本,易用性,开放性(mcp协议适配),差异化亮点多方面进行分析和研究。

阿里发布 QwenLong-L1 超长文本杀器!已开源、支持 120k 长上下文、具备“翻书回溯”能力
业界普遍认为AI上下文越长越好,但这存在一个核心矛盾:模型能“吞下”海量信息,却难以真正“消化”。 面对长文,它们会忘记要点、无法深入推理,这已成为一大瓶颈。 例如,AI 能记住第1页的内容,同时理解第100页的观点,并将两者联系起来进行推理吗?

投资回报率几何?AI的失败促使CEO们重新思考其应用
根据IBM商业价值研究院对CEO们的调查,近年来仅有25%的AI计划达到了ROI预期,同时,仅有16%的AI项目在企业范围内得到了全面推广。 部分问题在于,企业并不清楚自己将要面对什么,近三分之二的CEO承认,在尚未明确了解其价值之前,对错失新技术的恐惧就驱动了投资,这往往导致为了ROI而匆忙推进AI项目,或仅为了展示而启动项目,这两种做法都难以成功。 见证了过去两年半AI淘金热的IT专家们,对AI项目表现平平并不感到惊讶。
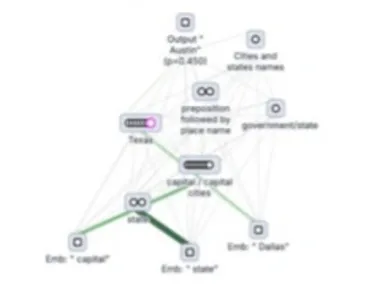
Anthropic 开源神经网络追踪工具,可生成归因图直观展示 AI 模型处理提示词具体过程
Anthropic开源新一代神经网络追踪工具,可生成归因图展示AI模型推理过程,并与Neuronpedia平台结合提供互动体验。CEO Dario Amodei强调此举将提升大模型可解释性。#AI可解释性# #开源工具#
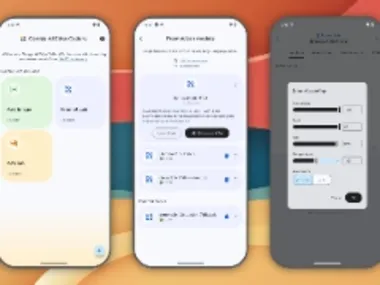
谷歌悄然推出“AI Edge Gallery”应用:可在手机本地运行 AI 模型
谷歌发布Google AI Edge Gallery应用,支持手机离线运行Hugging Face的AI模型,可生成图像、回答问题等。无需联网,直接利用手机处理器计算。目前为实验性Alpha版本,安卓可用,iOS即将推出。#AI应用# #谷歌黑科技#

消息称 Meta 计划让 AI 接管 90% 产品风险评估,取代人工审核
Meta计划将高达90%的风险评估工作交由AI完成,包括青少年风险和暴力内容等敏感领域。尽管AI审核能加快流程,但员工警告可能忽视人工能识别的严重风险。最新报告显示,政策调整后删除内容减少,但霸凌和暴力内容略有上升。#MetaAI审核# #社交媒体安全#

谷歌野心藏不住!劈柴哥放话:AI比互联网更颠覆!智能体将打造新的中间平台生态;记者:Chrome被卖了咋办?
出品 | 51CTO技术栈(微信号:blog51cto)I/O大会,谷歌用Gmini 2.5 Pro、Veo 3证明了自己在AI领域的绝对实力。 刚刚,知名科技媒体Verge放出了谷歌CEO劈柴哥的采访,看完发现——谷歌的AI逆袭绝非偶然! 在24年,谷歌还在被OpenAI追着打的时候,劈柴哥就曾表示大厂的AI竞争并非一朝一夕之功,如果眼光放长远些,短期内谁领先、谁落后,其实并不重要。

谷歌 DeepMind 最强 AI 手语翻译模型:SignGemma 登场,打破手语沟通壁垒
谷歌 DeepMind 团队于 5 月 27 日宣布推出 SignGemma,是其迄今为止最强大的手语翻译模型,可将手语转化为口语文本,该开源模型将于今年晚些时候加入 Gemma 模型家族。

谷歌联合创始人 Sergey Brin 揭秘:AI 爱吃“罚酒”,受威胁后反而提升性能
在出席迈阿密举办的 All-In-Live 活动中,谷歌联合创始人谢尔盖・布林(Sergey Brin)抛出新观点,有时候恐吓人工智能(AI)模型,反而能刺激提升其表现。

美国白宫委员会编制儿童健康报告被指 AI 造假:引用“幽灵论文”,结论遭质疑
纽约时报于 5 月 29 日发布博文,报道称由美国白宫 Make America Healthy Again Commission 委员会编写的儿童健康报告,大量引用了不存在的科学研究,因此报告给出的数据和结论遭到质疑。

BFL 推出 FLUX.1 Kontex 模型套件,AI 生图速度比主流竞争对手快一个数量级
科技媒体 WinBuzzer 昨日(5 月 30 日)发布博文,报道称 Black Forest Labs(BFL)推出全新 AI 模型套件 FLUX.1 Kontext,专注于生成与编辑上下文图像,号称速度比主流竞争对手快一个数量级。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉