
业界普遍认为AI上下文越长越好,但这存在一个核心矛盾:模型能“吞下”海量信息,却难以真正“消化”。面对长文,它们会忘记要点、无法深入推理,这已成为一大瓶颈。
例如,AI 能记住第1页的内容,同时理解第100页的观点,并将两者联系起来进行推理吗? 多数情况下,答案是令人失望的。
这就像开卷考试,书太厚,你找不到答案在哪,开卷也等于零分。 研究者把这种瓶颈正式命名为“长上下文推理 RL”,强调模型必须先检索并定位片段,再进行多步逻辑链生成,而不是直接“凭存货作答”。
近日,阿里巴巴把一套可阅读 120 k token 超长文档、还能“回头修正”的训练框架“QwenLong-L1”完整开源,给上述瓶颈了一个清晰的、可行的解决思路。

《QwenLong-L1: A Framework for Long-Context Reasoning RL》论文。
GitHub地址:https://github.com/Tongyi-Zhiwen/QwenLong-L1
论文地址:https://arxiv.org/abs/2505.17667
QwenLong-L1的解法:一套“三步走”的战略
QwenLong-L1 并不是一个新模型,而是一套训练已有大模型的新方法——它采用了三阶段训练流程:
第一步有监督学习(SFT)阶段。模型在这一阶段接受的是大量经过标注的长文本推理样本,比如“从一份 20 页的财报中,找出企业未来三年关键成本控制策略”。这一步帮助模型建立对“长内容”的基础适应力:哪里该找信息?信息之间有什么逻辑链?如何根据内容生成回答?这一阶段不是靠猜答案,而是靠“看例子学”。
第二步是“分级强化”——随着文档长度逐步增加,模型被分阶段推进强化学习过程。训练初期,输入文档较短;模型表现稳定后,再逐步拉长输入。这就像教孩子写作业,从看一页材料回答问题,慢慢过渡到处理整本教材。“突然上难度”的方法常常训练崩盘,而这套“课程表”式的推进方式,使得模型策略进化更可控、更稳定。
第三步是“难题反复训练”——用最难的样本反复优化模型的策略空间。这一步被称为“困难感知的回顾采样”(Difficulty-Aware Retrospective Sampling):它刻意选择那些模型曾经做错、但又具有代表性的难题进行强化学习,从而鼓励模型尝试不同思路路径,并形成反思、回溯、验证的能力。
更妙的是,它还引入了一套混合奖励机制。 不同于传统解数学题那样“答案对就给满分”的死板规则,QwenLong-L1同时引入了“规则裁判”和“LLM裁判”。 “规则裁判”确保答案的精确性,而“LLM裁判”则从语义上判断模型生成的内容和标准答案是否意思相近。这给了模型更大的灵活性,尤其是在处理那些没有唯一标准答案的开放性问题时,效果拔群。
效果如何?它学会了“自我纠错”
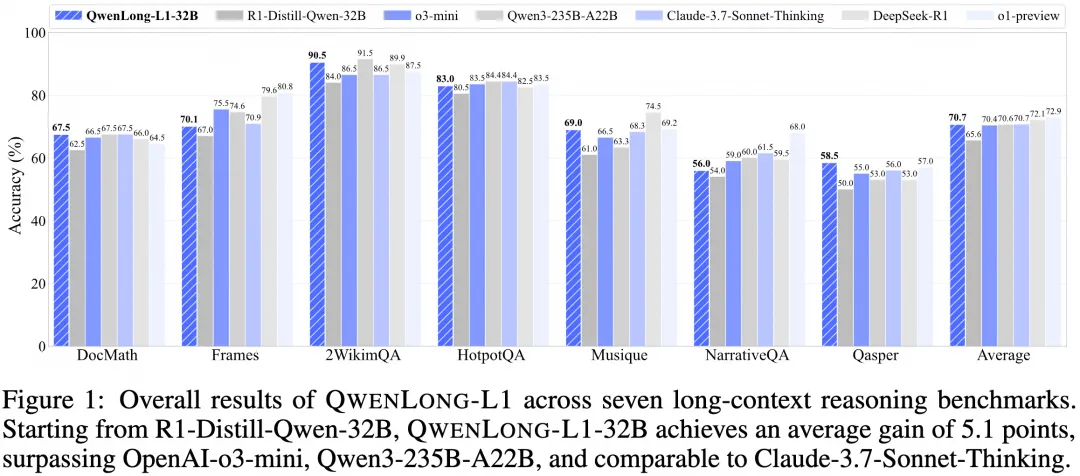
阿里团队在7个长文本问答(DocQA)基准上测试了QwenLong-L1。结果非常亮眼。 基于DeepSeek-R1-32B训练出的QWENLONG-L1-32B模型,其性能足以和Anthropic的Claude-3.7 Sonnet Thinking相媲美,并且优于OpenAI的o3-mini等一众强手。
但比分数更重要的,是模型在推理过程中展现出的“行为变化”。 论文提到,经过QwenLong-L1训练后,模型明显更擅长信息定位(Grounding)、子目标设定(Subgoal Setting)、回溯(Backtracking)和验证(Verification)。
这是什么意思呢? 举个例子,一个普通模型在分析一份冗长的财报时,可能会被无关的细节带跑偏,或者陷入某个死胡同里出不来。 而QwenLong-L1训练的模型,则表现出了惊人的自我反思和纠错能力。它在推理过程中如果发现一条路走不通,会主动“回溯”,退回到上一步,排除干扰信息,然后选择另一条路继续探索,直至找到正确答案。


