资讯列表

Adobe Firefly视频功能大升级:支持精准提示编辑、集成FLUX.2与Astra,告别“重做整段视频”时代
Adobe 正全力加码AI视频创作赛道。 其AI生成平台 Firefly 近日迎来重大更新:正式推出全新视频编辑器,首次支持基于文本提示的精准局部修改,并集成 Black Forest Labs 的 FLUX.2图像模型、Topaz Labs 的 Astra 视频超分模型,以及 Runway 的 Aleph 模型,大幅拓展创作自由度与画质上限。 过去,Firefly 视频功能仅支持“端到端生成”——若对成片中任意细节不满(如天空太亮、镜头太远),用户只能重新输入完整提示词,从头生成整段视频,效率低下且难以控制。

普渡大学提出类脑 AI 算法:旨在打破“内存墙”,大幅降低能耗
随着大型人工智能模型对海量数据的依赖日益加深,传统计算机架构中内存与处理能力分离所导致的**“内存墙”**瓶颈正消耗巨大的时间和能源。 普渡大学和佐治亚理工学院的研究人员在《科学前沿》杂志上发表了一项新研究,提出了一种利用类脑算法构建新型计算机架构的方法,以期大幅降低人工智能模型的能耗。 冯·诺依曼架构的瓶颈:内存墙当前大多数计算机仍基于1945年提出的冯·诺依曼架构,该架构将内存和处理能力分置,导致数据在两者之间快速流动时形成性能瓶颈。

罗福莉加入小米后首秀,解释 MiMo-V2-Flash 模型如何做到推理速度飞快
AI在线 12 月 17 日消息,2025 小米人车家全生态合作伙伴大会于今日举行,Xiaomi MiMo 大模型负责人罗福莉迎来入职后首秀。 小米昨日晚间惊喜发布了 Xiaomi MiMo-V2-Flash 开源 MoE 模型,总参数量 309B,活跃参数量 15B,专为智能体 AI 设计,专注于快。 不少AI在线小伙伴体验后发现,该模型推理速度非常快。

UniEdit:首个大型开放域大模型知识编辑基准
随着大语言模型(LLM)的广泛应用,它们在医疗、金融、教育等关键行业扮演着愈发重要的角色。 然而,一个被忽视的现实是:大模型的知识并不会自动更新,更不总是准确。 当模型输出过时信息、错误事实甚至自信满满的“胡说八道”时,如何快速、精准、低成本地纠正它?

上海创智学院菁智人才论坛 | 海内外顶尖青年人才召集令暨海优政策宣讲会

VGGT4D:无需训练,挖掘3D基础模型潜力,实现4D动态场景重建
如何让针对静态场景训练的 3D 基础模型(3D Foundation Models)在不增加训练成本的前提下,具备处理动态 4D 场景的能力? 来自香港科技大学(广州)与地平线 (Horizon Robotics) 的研究团队提出了 VGGT4D。 该工作通过深入分析 Visual Geometry Transformer (VGGT) 的内部机制,发现并利用了隐藏在注意力层中的运动线索。

刚刚,OpenAI推出全新ChatGPT Images,奥特曼亮出腹肌搞宣传
如果你刚刚打开 X 并且正好关注了 OpenAI 和山姆・奥特曼,那么你可能会看到这样的照片:是的,确实有点辣眼睛。 就连 OpenAI 官方号也忍不住吐槽(其实是刷热度):sam.而在评论区,更是一片吐槽和调侃:但不管怎么说,热度是有了。 实际上,山姆・奥特曼之所以发这样一张辣眼睛的图片,正是为 OpenAI 刚刚推出的全新 ChatGPT Images 造势。

反超Nano Banana!OpenAI旗舰图像生成模型上线
Jay 发自 凹非寺量子位 | 公众号 QbitAIOpenAI的红色预警,还在发力。 憋了大半年的图像生成模型——GPT-Image-1.5,终于发布。 官方表示,本次更新主要有四个亮点:更严谨的指令遵循;.

浙大联手字节:开源大规模指令跟随视频编辑数据集OpenVE-3M
本文的作者分别来自浙江大学和字节跳动。 第一作者何昊阳是来自浙江大学的博士生,研究方向聚焦于视频生成与编辑。 通讯作者为浙江大学谢磊教授。
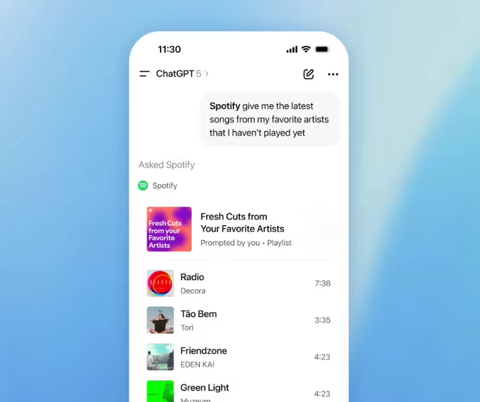
Apple Music 将与 ChatGPT 实现全新集成,用户可轻松创建歌单!
近日,OpenAI 宣布,Apple Music 即将加入与 ChatGPT 的合作阵营,用户将能够通过自然语言指令,轻松创建音乐歌单。 OpenAI 的应用业务首席执行官菲吉・西莫在一篇 Substack 帖子中透露了这一消息,表示这一集成功能很快就会推出。 在过去的一年中,OpenAI 已经与多个平台进行了成功的集成,包括 Spotify、Booking.com 等。

终结AI图像“变脸”噩梦:OpenAI推出GPT Image1.5,主打精准编辑与视觉一致性
OpenAI 正在推出新一代图像生成模型 GPT Image1.5,以抗衡谷歌在人工智能领域的强势崛起。 据 AIbase 报道,这款新模型承诺带来显著的性能提升,包括更精确的指令遵循、更细致的编辑控制以及高达四倍的图像生成速度。 速度与精度升级:GPT Image1.5全面对抗谷歌GPT Image1.5已于本周二面向所有 ChatGPT 用户和 API 用户开放。

OpenAI 推出全新图像生成模型 GPT Image 1.5,性能显著提升!
OpenAI 于正式发布了其最新的图像生成模型 GPT Image1.5,标志着 ChatGPT 在视觉创作能力上的重大突破。 这一新模型不仅能够生成高保真的图像,还在理解用户指令方面表现优异,具备极强的提示词遵循能力。 新版本的 GPT Image1.5能够从零开始创作图像,或者在用户上传的照片基础上进行编辑,同时保留原图的核心要素,准确执行用户的各种指令。

微软确认:Win11 AI 智能体访问用户文件前会先请求许可
AI在线 12 月 17 日消息,微软证实,在允许人工智能智能体访问存储于六个常用文件夹(包括桌面、文档、下载、音乐、图片和视频)的文件前,Windows 11 会先征求用户的同意。 用户也可为每个智能体单独自定义文件访问权限。 外界对微软大力推进人工智能智能体深度融入 Windows 系统的担忧日益加剧。

Adobe Firefly 更新:说句话就能修改视频元素、镜头角度
AI在线 12 月 17 日消息,Adobe 正在为其人工智能视频生成应用 Firefly 推送更新,新增一款支持基于文本指令精准编辑的视频编辑器,同时引入多款用于图像和视频生成的第三方模型,其中包括 Black Forest Labs 的 FLUX.2 以及 Topaz Labs 的 Astra 模型。 在此之前,Firefly 仅支持基于文本指令的视频生成功能,若视频中某部分效果不符合预期,用户只能重新生成整个片段。 而借助这款全新的编辑器,用户可以通过文本指令对视频元素、色彩及镜头角度进行修改;同时,应用还新增了时间轴视图,便于用户轻松调整画面帧、音频及其他视频属性。

免费用:OpenAI 最强 AI 生图模型登场,奥尔特曼变身性感消防员
AI在线 12 月 17 日消息,OpenAI 昨日(12 月 16 日)发布博文,推出“全新旗舰 ChatGPT 图像生成模型”GPT Image 1.5,并罕见公开了该项目背后的庞大研发团队名单,并同步在 ChatGPT 中推出了专用的“Images”(图像)标签页。 此次更新被视为 ChatGPT 图像生成能力的重大飞跃,新模型不仅能生成高保真图像,更在“听懂人话”方面表现出色,即具备极强的提示词遵循能力。 无论是从零创作还是基于上传照片进行编辑,GPT Image 1.5 都能在保留原图核心要素的同时,精准执行用户的指令。

OpenAI 宣布:苹果 Apple Music 即将与 ChatGPT 集成
AI在线 12 月 17 日消息,很快用户就能让 ChatGPT 快速创建 Apple Music 歌单,以及完成其他各类操作了。 在今日早些时候发布的一篇 Substack 帖子中,OpenAI 应用业务首席执行官菲吉・西莫表示,Apple Music 将加入即将与 ChatGPT 实现集成的合作伙伴阵营。 AI在线注意到,去年 10 月,OpenAI 在 ChatGPT 中正式推出应用功能,首批合作与集成的平台包括 Spotify、Booking.com、Canva、Coursera、Figma、Expedia 和 Zillow。

设计师会被 AI 取代?看懂这个“人机协同”工作流,你的焦虑减半!
前言. 当AI能一键生成界面、自动分析数据,设计师的核心工作是会被取代,还是被重新定义? 我们认为,真正的变化并非替代,而是分工的进化。

资讯/神器/素材全都有!2025年12月设计素材周刊第三波
往期回顾:一、设计资讯. Figma 新增「图像功能」. 最近 Figma 上线了全新的 AI 图像编辑工具,全部集中在一个上下文工具栏中扩展图像— 将图像扩展到其原始边界之外.