资讯列表

卓驭打造科技平权,端到端辅助驾驶延伸至重卡高速、无人物流
12 月 30 日,卓驭品牌盛典 2025 在深圳举行。 不同于常规的技术参数发布会,本次卓驭科技的发布更侧重技术路线阐释、工程哲学与未来布局。 作为从大疆独立仅一年多的智能驾驶公司,卓驭首次系统对外解读了其从规则驱动到数据驱动的技术转型、软硬一体的工程能力,以及从乘用车向商用车等多场景延伸的战略路径。

消息称月之暗面 Kimi 完成 5 亿美元新融资,杨植麟称公司账上有超百亿元人民币
AI在线 12 月 31 日消息,据《晚点 LatePost》今日报道,月之暗面(Kimi)近期完成 5 亿美元(AI在线注:现汇率约合 35.03 亿元人民币)C 轮融资,IDG 领投 1.5 亿美元(现汇率约合 10.51 亿元人民币),阿里、腾讯、美团联合创始人王慧文等老股东超额认购,投后估值 43 亿美元(现汇率约合 301.28 亿元人民币)。 报道还称,王慧文已经累计投资月之暗面 7000 万美元(现汇率约合 4.9 亿元人民币)。 报道还提到,12 月 31 日,月之暗面创始人、CEO 杨植麟发布内部信,公司有超过 100 亿元人民币现金储备。

独家丨OpenAI、Meta都在押注的摄像头AI耳机,被这家中国明星创业公司抢先发布
光帆科技成立于2024年10月,由前小米自研手机及汽车OS负责人、89号员工董红光离职创办,主打面向下一代人机交互的AI可穿戴硬件及通用 AI Agent。 01中国创业公司领跑海外巨头,定义AI耳机新范式成立一年,光帆科技已经连续完成多轮融资,估值迈进“10亿元俱乐部”。 关于定价,光帆科技尚未对外透露任何信息。

2030年前,20万欧洲银行岗位面临 AI 威胁
根据摩根士丹利的分析,预计到2030年,人工智能将在欧洲金融行业中对约20万个银行职位造成威胁。 分析师指出,最受影响的将是后端和中间办公岗位,这些职位通常涉及数据处理、文书工作及其他例行事务。 图源备注:图片由AI生成,图片授权服务商Midjourney随着金融科技的迅速发展,许多传统银行正在逐步采用智能化解决方案,以提高效率并降低成本。
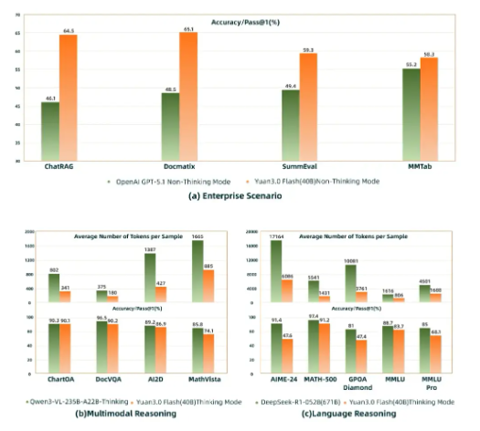
源 Yuan3.0Flash:开源多模态基础大模型引领 AI 新潮流
近日,YuanLab.ai 团队正式发布了源 Yuan3.0Flash 多模态基础大模型,这一模型的开源将为 AI 领域带来新的机遇。 该模型不仅包括16bit 与4bit 的模型权重,还提供了详细的技术报告和训练方法,支持社区进行二次开发和行业定制,极大地促进了 AI 技术的普及。 Yuan3.0Flash 的参数规模达到40B,采用了创新的稀疏混合专家(MoE)架构,在推理过程中,仅激活约3.7B 的参数。
腾讯炸场!10亿参数文生3D动作神器开源,游戏NPC一键“活”了!
2025年12月30日,腾讯混元团队重磅开源HY-Motion1.0(Hunyuan-Motion-1.0),一款十亿参数级文本到3D动作生成大模型。 该模型基于Diffusion Transformer(DiT)架构与流匹配机制,仅需一句自然语言描述,即可生成高保真、流畅多样的3D角色骨骼动画,直接兼容Blender、Unity、UE等主流3D工具,极大降低了动画制作门槛。 核心技术亮点 HY-Motion1.0采用全阶段训练策略:首先在超3000小时多样化动作数据上预训练,构建通用运动先验;随后在400小时精选高质量数据上微调,提升细节流畅性;最后通过强化学习(RLHF)结合人类反馈和奖励模型,优化物理合理性与语义对齐。

夸克AI眼镜首次OTA:AI能力进一步增强,新增图文备忘录等五项功能
12月31日,搭载千问AI助手的夸克AI眼镜迎来首次OTA,AI能力进一步增强。 新增录音纪要、图文备忘录、大模型多意图理解和执行、蓝环支付、社区服务五项新功能,并对受到用户欢迎的翻译、行程查询、音乐播放等功能场景进行优化。 在录音场景下,基于自研的Quark Audio语音增强模型和原有的5麦克风阵列加骨传导硬件配置,升级后的夸克AI眼镜支持十米范围内收音,并有效降噪。
微分智飞高飞:我们正处于通用飞行智能爆发前夜丨GAIR 2025
过去两年,具身智能的火热源于一个共同期待:大语言模型的出色能力有目共睹,若将其接入机器人,有望赋予机器人更聪明的大脑,从而为行业打开新空间。 然而热闹两年后,具身智能仍没有标准答案,却出现了很多细分领域,智能飞行机器人就是其中一个重要分支。 浙江大学控制学院长聘副教授、博士生导师高飞,就是这个领域的一位非常优秀的年轻学者。

圆桌论坛:关于“世界模型”突破方向的六个猜想 | GAIR 2025
“世界模型”是今年超级热门的话题和方向,但整体来看相关研究尚处于起步阶段,共识尚未形成。 在12月13日举行的第八届GAIR全球人工智能与机器人大会“世界模型”圆桌上,浙江大学研究员彭思达、腾讯ARC Lab高级研究员胡文博、中山大学计算机学院青年研究员,拓元智慧首席科学家王广润博士、香港中文大学(深圳)助理教授韩晓光、西湖大学助理教授修宇亮齐聚一堂。 五位年轻的学者在清华大学智能产业研究院(AIR)助理教授,智源学者(BAAI Scholar)赵昊的主持下,围绕着世界模型、数字人重建,新技术范式展望等展开了一场非常轻松但严肃的学术圆桌。

两部门发布《关于促进电网高质量发展的指导意见》,要求推动 AI 深度应用
AI在线 12 月 31 日消息,国家发展改革委、国家能源局今日联合发布《关于促进电网高质量发展的指导意见》。 目标到 2030 年,主干电网和配电网为重要基础、智能微电网为有益补充的新型电网平台初步建成,主配微网形成界面清晰、功能完善、运行智能、互动高效的有机整体。 电网资源优化配置能力有效增强,“西电东送”规模超过 4.2 亿千瓦,新增省间电力互济能力 4000 万千瓦左右,支撑新能源发电量占比达到 30% 左右,接纳分布式新能源能力达到 9 亿千瓦,支撑充电基础设施超过 4000 万台,公共电网的基础作用充分发挥,智能微电网多元化发展,电力系统保持稳定运行,服务民生用电更加有力。
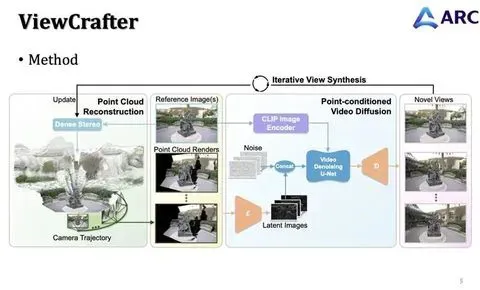
腾讯 ARC Lab 胡文博:“如何实现三维感知的视频世界模型,这非常值得探索”|GAIR 2025
作者丨齐铖湧编辑丨马晓宁世界模型的研究尚处于起步阶段,共识尚未形成,有关该领域的研究形成了无数支流,过去一年多,Sora为代表的视频生成模型,成为继大语言模型(LLM)后新的学术热点。 本质上讲,当下火爆的视频生成模型,是一种世界模型,其核心目的是生成一段逼真、连贯的视频。 要达到这样的目的,模型必须在一定程度上理解这个世界的运作方式(比如水往低处流、物体碰撞后的运动、人的合理动作等)。

从“手工艺”到“AI工程化”:解码AI智能渗透的未来之战
当AI的浪潮席卷安全领域,攻防的形态正在发生根本性的变革。 11月,腾讯云黑客松智能渗透挑战赛决赛落幕,400 顶尖极客用AI智能体上演了一场“无人干预”的巅峰攻防对决,标志着安全攻防正式迈入AI驱动的新质生产力时代。 赛后,腾讯云安全作为赛事主办方,邀请赛事评委、高校导师及优秀战队核心成员,举办了一场名为“冠军之夜”的线上深度复盘。

Meta 收购 Manus 细节曝光,开价 20 亿美元闪电成交
20 亿美元,Meta 收购 Manus 最终出价曝光。 在 Meta 接洽谈判初期,Manus 正寻求新一轮融资,估值正好也是 20 亿美元。 相当于创始人肖弘开价多少,扎克伯格照单全收。

对话微分智飞高飞:看具身智能如何引发飞行认知革命 | GAIR 2025
作者丨齐铖湧编辑丨马晓宁本文整理自高飞与AI科技评论的对话:01传统无人机和飞行具身智能AI科技评论:您提出“飞行具身智能”这一概念,它与传统的无人机智能有何本质区别? 高飞:具身智能的本质是“智能机器人”,赋予各种机器人认知、推理和泛化决策的能力,对于飞行也不例外,将会重新定义飞行机器人。 拿操作类的机器人打比方,双臂具身智能和传统工业机械臂的本体很相似,甚至可能完全长得一样,但双臂具身智能具备几个关键能力:泛化通用、自主决策。

以色列 AI21 Labs 否认与英伟达交易传闻:正与多方洽谈
AI在线 12 月 31 日消息,据以色列媒体 Globes 报道,该国人工智能企业 AI21 Labs 首席执行官 Ori Goshen 在一份内部信中否认了公司与英伟达达成交易协议的消息。 此前传闻称 AI21 Labs 价值在 20~30 亿美元水平(AI在线注:现汇率约合 140.13 ~ 210.2 亿元人民币)。 Ori Goshen 表示该企业与英伟达双方均否认了此前的传闻。

“氛围编程”命名人卡帕西:自己作为程序员,从未感到如此落后
AI在线 12 月 31 日消息,据《商业内幕》今日报道,作为“一直走在时代前沿”的群体,安德烈・卡帕西在 AI 尚未成为风口之前就参与创建了 OpenAI;在自动驾驶领域,他也很早进入核心位置:曾负责特斯拉的 Autopilot AI 工作。 然而,即便是这样一位“先行者”,卡帕西也开始感受到追赶的压力。 他在 X 上写道:“我从来没有像现在这样,觉得自己作为程序员如此落后。

OpenAI 员工年薪翻天!人均股票薪酬高达 150 万美元,创科技行业新纪录!
在科技行业竞争日益激烈的背景下,OpenAI 的薪酬数据让人瞩目。 最新财务报告显示,这家领先的人工智能公司向约 4000 名员工支付的股票薪酬人均高达 150 万美元,创下了科技初创公司历史的新高。 这个数字是过去 25 年里其他 18 家主要科技公司在上市前一年员工薪酬的 34 倍,实在让人惊叹。

AI “套壳” 产品能否脱颖而出?揭示创业机会与竞争策略
近年来,人工智能技术的迅猛发展催生了大量的 “AI 套壳” 产品。 这些产品往往被简单地看作是利用现有 AI 模型或 API 的轻量级应用,开发过程相对简单,容易被市场忽视。 然而,一项新的分析指出,这些 “套壳” 应用并不应被轻视,能否在激烈的竞争中生存下来,关键在于它们是否能有效嵌入用户工作流、积累独特的数据以及应对来自行业巨头的挑战。