
大家好,我是肆〇柒。今天要和大家分享的是由中国人民大学统计学院、上海人工智能实验室和上海财经大学联合研究团队在ICLR 2026会议投稿的突破性工作——MemMamba。这项研究首次系统揭示了Mamba模型的记忆衰减机制,通过受人类"做笔记"行为启发的创新设计,成功解决了长序列建模中的关键记忆瓶颈问题,在400k tokens的极端长序列任务中仍能保持90%的准确率,为高效且强大的序列建模开辟了全新道路。
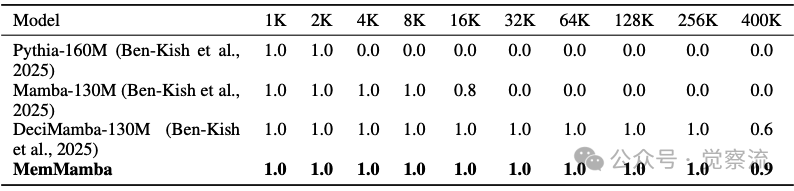
不同上下文长度下的Passkey检索准确率
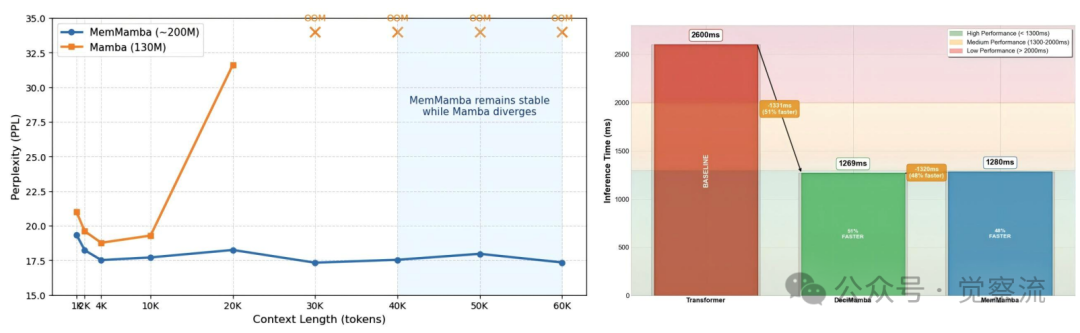
想象一下:当序列长度达到40万token时,MemMamba仍能准确记住关键信息(90%准确率),而原始Mamba完全失效(0%准确率)。这一惊人差距揭示了长序列建模领域的一个根本性突破。在当今数据爆炸性增长的时代,长序列建模已成为自然语言处理和生物信息学等任务中的关键挑战。长序列数据通常指跨越数千至数百万时间步或 token 的连续序列,广泛存在于现代机器学习应用中:从 NLP 中的书籍长度文档建模(PG19 数据集包含约 1 亿 token,由 1919 年左右出版的 Project Gutenberg 英文小说组成,平均长度达 69k tokens)、生物信息学中的 DNA 序列分析,到复杂多模态医疗记录的处理。传统架构在处理这类数据时面临效率与记忆保留能力的根本性权衡:RNN 系列模型易受梯度消失/爆炸困扰,难以稳定处理长依赖;Transformer 虽能建模全局依赖,但其 O(n²) 复杂度使其在真正长上下文中效率低下。MemMamba 的突破性在于首次系统揭示了 Mamba 的记忆衰减机制,提出了一种可线性扩展的"做笔记"式记忆增强架构,实现了从单纯追求"更长"到关注"如何记住关键信息"的范式转变。
现有架构为何难以兼顾效率与记忆?

不同上下文长度下模型的困惑度(PPL)比较
传统序列建模架构在处理超长序列时表现出显著局限。循环神经网络(RNN)及其变体(LSTM, GRU)本质上是顺序处理的,受到梯度消失或爆炸问题的困扰,使其难以稳定处理长距离依赖。有研究显示,这些模型在长序列上的表现受限于其内在的不稳定性。
Transformer 通过自注意力机制和全局 context 建模引入了范式转变,但其序列长度的二次复杂度使其在真正长上下文中效率低下。对于序列长度 n、层数 L 和特征维度 d,Transformer 自注意力的时间复杂度为 TC = O(L·n²·d)。当序列长度达到 10⁵ 时,n² 项导致约 10¹⁰ 次操作,远超当前硬件能力。实践中常采用滑动窗口注意力(窗口大小 w=512)或稀疏注意力等近似方法,但这些截断不可避免地会丢弃窗口外的信息,导致有效建模长度(EML)受限:EML ≤ w ≪ n,无法捕捉真正长距离依赖。
选择性状态空间模型(SSMs),特别是 Mamba 架构,提供了一个有前景的替代方案。通过解耦序列长度与计算,Mamba 实现了线性时间复杂度 O(n) 和常数时间递归推理 O(1),定位为长序列建模的潜在基础。然而,尽管在计算效率上取得了飞跃,其记忆保真度在规模扩大时迅速下降。随着序列长度增长,Mamba 及其后续版本在需要强记忆保留的任务中表现出急剧下降,如 5-shot MMLU 或长距离键值检索任务。在 400k tokens 的 Passkey Retrieval 任务中,原始 Mamba 的准确率降至 0%,而 MemMamba 仍能保持 90% 的准确率,这一差距直观展示了传统架构在长距离记忆保留上的根本局限。
核心发现:Mamba 的"遗忘"机制数学解析
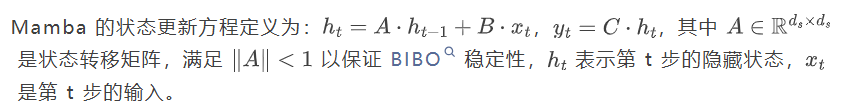
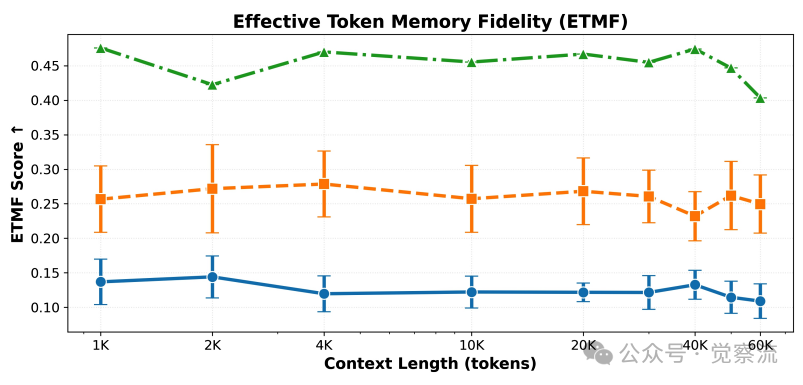
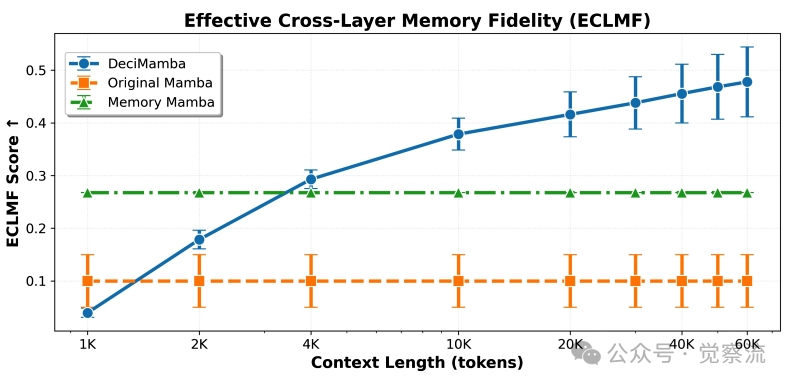
不同Mamba变体的ETMF和ECLMF比较


实证分析表明,Mamba 在两项指标上均显著劣于理想模型,揭示了其在超长序列中"忘记"关键信息的本质原因。随着序列长度增加,Mamba 的记忆保真度急剧下降,而 MemMamba 通过创新机制有效缓解了这一问题。在 ETMF 指标上,MemMamba 的表现明显优于原始 Mamba 和 DeciMamba,即使在长距离依赖情况下也能保持较高的语义保真度。论文指出,ETMF 和 ECLMF 两个指标提供了互补视角:ETMF 反映了递归传播后长距离 token 语义是否保持忠实,而 ECLMF 量化了跨层信息传递过程中的退化程度,共同揭示了 Mamba 在记忆衰减和外推能力方面的双重挑战。
解法创新:MemMamba 的"做笔记"记忆增强机制
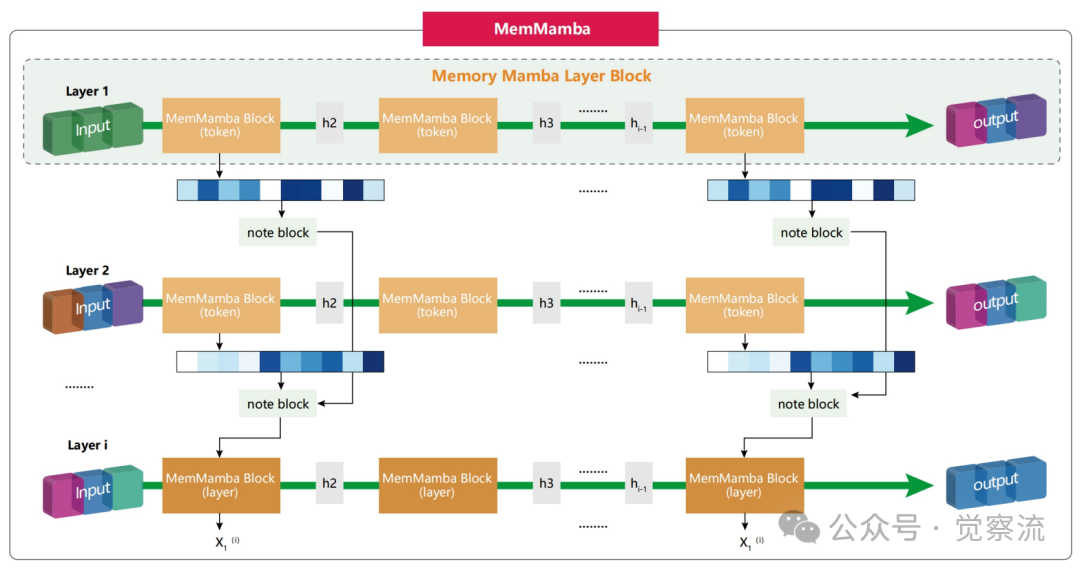
MemMamba整体工作流程
如上图,MemMamba 受人类阅读长文档时做笔记行为的启发,将状态空间模型重新构想为结构化记忆系统。想象你正在阅读一本600页的小说(约69k tokens)。随着阅读深入,你会自然地在关键情节处做笔记,帮助记忆重要线索。同样,MemMamba 通过 Note Block 在关键 token 处"做笔记",将摘要存入状态池。当模型"忘记"某些信息时,它会像你翻阅笔记一样,从状态池中检索相关信息进行恢复。

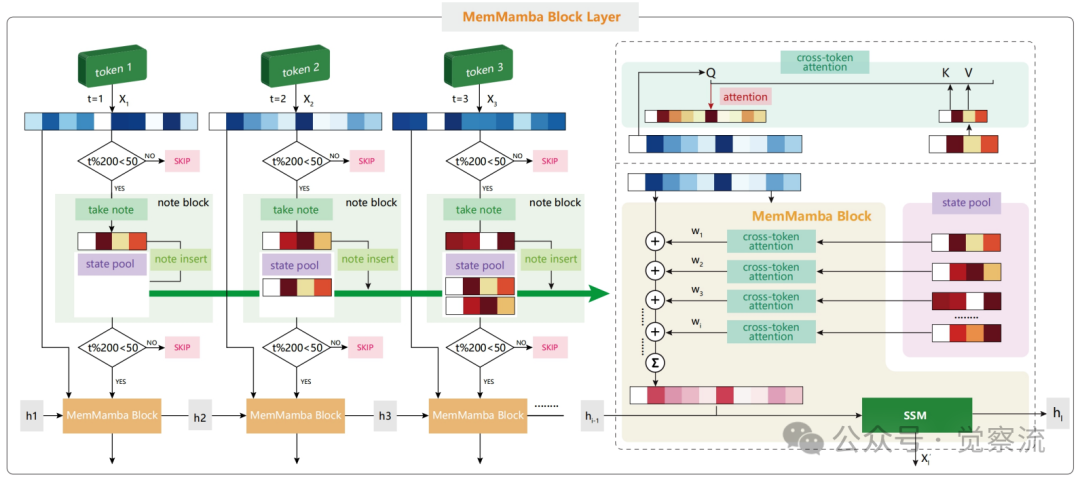
MemMamba Block Layer工作流程

这种双阈值和稀疏跨层机制确保跨 token 补充在每一层发生,而跨层记忆交互则稀疏激活,在记忆保留和计算效率之间取得平衡。每个状态摘要向量被压缩到 64 维,状态池大小固定为 50,这些设计选择在广泛参数范围内表现稳定,证明了架构的鲁棒性。
核心机制消融实验结果
如上,消融实验结果清晰展示了 MemMamba 各个组件的必要性。在 PG19 语言建模任务中,完整 MemMamba 的困惑度(PPL)为 17.35,而移除 Note Block 后 PPL 升至 19.99,移除跨 token 注意力后 PPL 升至 18.63,移除跨层注意力后 PPL 升至 18.19。这表明所有三个组件都对 MemMamba 的性能提升有重要贡献,特别是 Note Block 机制在长序列建模中起到关键作用。实验还表明,最大池化(max pooling)在保真度-效率平衡上表现最佳,优于均值池化(mean)、T-Max-Avg 和 S3Pool 等替代方案。
如何兼顾线性复杂度与强记忆能力?
MemMamba 在引入状态摘要和跨层注意力的同时,仍保持线性时间和空间复杂度。具体而言,其计算成本随序列长度 n 和隐藏维度 d 的缩放为 O(n·d),与 Transformer 的 O(n²d) 形成鲜明对比。这通过将状态维度 ds 和注意力池大小 k 限制为常数来实现。

实验验证:MemMamba 的记忆能力突破
MemMamba 在多个长序列基准测试中实现了显著改进。

不同上下文长度下模型的困惑度(PPL)比较
如上表,在 PG19 语言建模任务中,MemMamba 在 60k tokens 时的困惑度(PPL)仅为 17.35,而参数规模相似的 Mamba 和 DeciMamba 已完全崩溃(>100)。在 200M 参数规模下,MemMamba 的表现超越了 400M 参数的 Compressive Transformer,证明了其参数效率优势。随着上下文长度增加,MemMamba 保持低且稳定的 PPL:在 1.5k tokens 时 PPL 为 19.35,在 60k tokens 时 PPL 在 17.33–18.25 之间波动。
这相当于在阅读整本小说的过程中,MemMamba 能够像人类一样"记住"关键情节,而其他模型在阅读到一半时就已经"忘记"了故事主线。在医疗领域,患者可能有长达数万token的电子健康记录,包含多年诊疗历史。MemMamba 能够记住关键病史信息(如药物过敏史),而不会在长序列处理中"忘记",这直接关系到诊断准确性和患者安全。
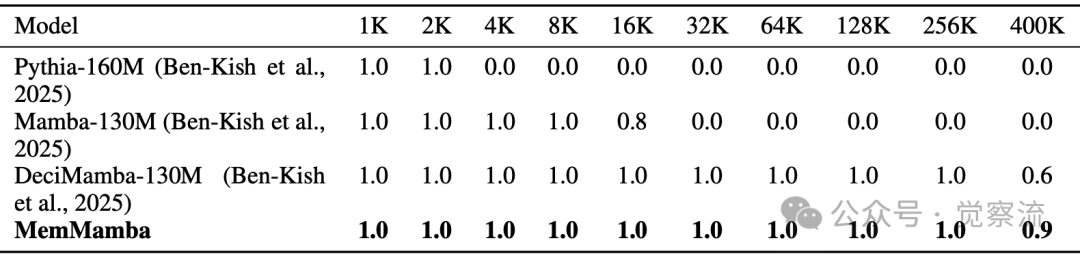
不同上下文长度下的Passkey检索准确率
如上,在 Passkey Retrieval 任务中,MemMamba 即使在输入长度达几十万 token 时仍保持高检索精度。当目标 token 位于预测点 200k tokens 之外时,MemMamba 仍能准确检索关键信息,而 Mamba 和 Pythia 在此类长度下完全失效。在 400k tokens 时,MemMamba 保持 90% 的检索准确率,而 DeciMamba 降至 60%,Mamba 完全失效。这一结果验证了 MemMamba 在处理极端长距离依赖任务中的优势,特别是在需要精确记忆特定位置信息的场景下。

不同噪声文档数量下各模型的性能
如上,在文档检索基准测试中,MemMamba 在简单和详细检索设置下均取得领先性能。随着噪声文档数量增加,Mamba 的性能急剧下降,DeciMamba 显示部分改进但仍不稳定。相比之下,MemMamba 在高噪声条件下持续保持较高分数,在 200 个噪声文档干扰下得分为 0.24,而 DeciMamba 仅为 0.12,Mamba 接近于 0,突显其在跨文档和跨领域推理任务中的优势。这相当于在200本无关书籍的干扰下,MemMamba 仍能准确找到目标信息,而其他模型早已迷失方向。
效率方面,在相同硬件条件下,MemMamba 的端到端延迟仅为 Transformer 的 0.52 倍(即 48% 的速度提升)。尽管引入了增强建模能力的额外计算,MemMamba 通过紧凑表示和跨层/跨 token 注意力优化信息流,从而在超长序列上保持高计算效率。ETMF 和 ECLMF 评分显示,MemMamba 在两项指标上均显著优于原始 Mamba 和 DeciMamba,验证了其记忆保真度的提升。
MemMamba 的鲁棒性
MemMamba 在关键超参数方面表现出强大鲁棒性。
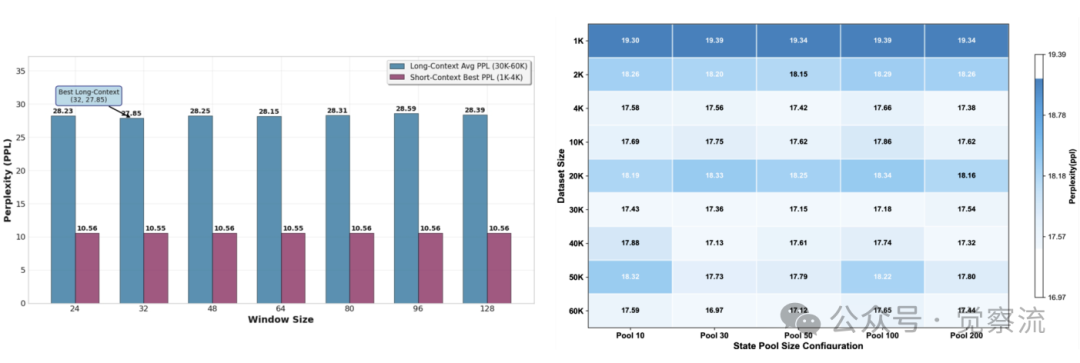
状态池大小和窗口大小对PPL的影响
如上图,在广泛范围内,窗口大小和状态池大小对性能影响甚微,表明架构稳定性强。例如,当状态池大小从 10 变化到 100 时,PPL 仅在 17.33-17.45 之间波动;当窗口大小从 16 变化到 128 时,PPL 仅在 17.33-17.42 之间波动。这一结果证明 MemMamba 的设计选择具有广泛的适用性,无需针对特定任务进行精细调参。
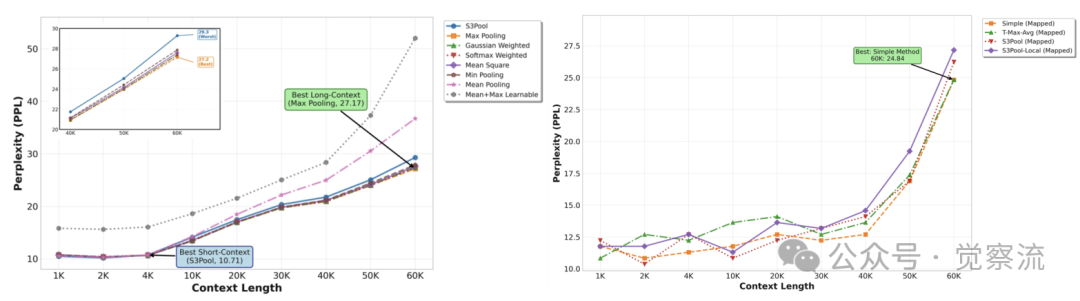
不同池化函数对建模质量的影响
如上图,在池化函数选择上,简单的最大池化(max pooling)在保真度-效率平衡上表现最佳,优于均值池化(mean)、T-Max-Avg 和 S3Pool 等替代方案。在 60k tokens 长度下,最大池化的 PPL 为 17.35,均值池化为 17.61,T-Max-Avg 为 17.52,S3Pool 为 17.48。这一结果表明,最大池化能更有效地保留关键信息,同时保持计算效率。论文指出,这是因为最大池化能够捕获最显著的特征,而这些特征往往对应于对任务最为关键的信息。
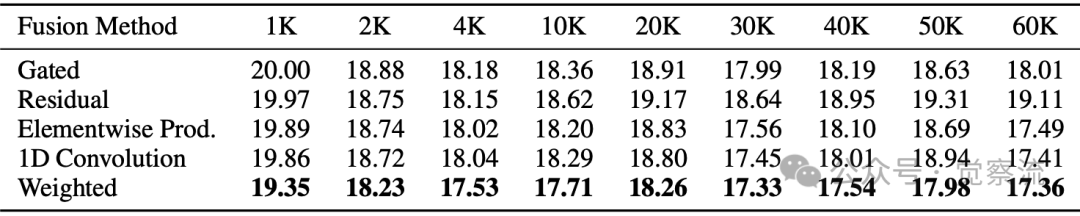
不同融合方法在上下文长度上的PPL比较
如上,融合方法的对比实验表明,在短序列上各种方法差异较小,但在长上下文中,残差融合和加权融合表现更优。在 60k tokens 时,加权融合的 PPL 为 17.36,残差融合为 17.49,元素乘积为 17.49,1D 卷积为 17.41,门控融合为 18.01。这些结果验证了 MemMamba 设计选择的合理性,特别是加权融合方法在超长序列上的稳定性优势。加权融合通过学习可调节的权重,能够更灵活地平衡原始输入和注意力补充之间的贡献,从而在不同长度的序列上保持稳定性能。
ETMF 和 ECLMF 评分进一步验证了 MemMamba 的记忆增强效果。MemMamba 在两项指标上均显著优于所有 Mamba 变体,尽管 DeciMamba 在极长距离跨层传输中显示微弱优势,但其不稳定性构成重大缺陷。这些量化指标为 MemMamba 的记忆增强机制提供了有力证据,证实了状态摘要和跨层注意力在缓解长距离遗忘方面的有效性。
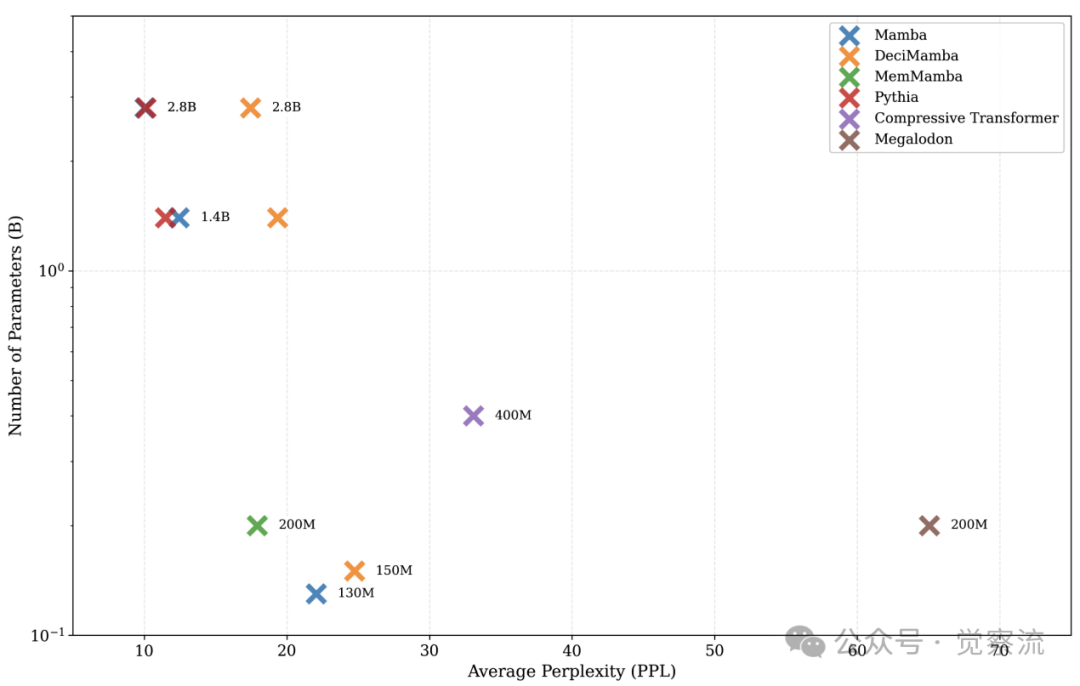
不同上下文长度下模型的困惑度(PPL)比较
如上,参数规模对比实验显示,MemMamba 在较小参数规模下就能达到与大规模模型相当的性能。在 1.5k tokens 时,200M 参数的 MemMamba PPL 为 19.35,而 400M 参数的 Compressive Transformer PPL 为 33.09,表明 MemMamba 具有显著的参数效率优势。在 60k tokens 时,MemMamba 仍保持 PPL 17.35,而 Compressive Transformer 因序列长度限制无法评估。这种参数效率使得 MemMamba 能够在资源受限的环境中部署,同时保持高性能。
总结:MemMamba 的启示
MemMamba 代表了长序列建模领域的一个重要突破,它通过将状态空间模型增强为结构化记忆系统,弥合了可扩展性与长距离依赖建模之间的长期差距。通过将动态状态摘要与轻量级跨层和跨 token 注意力相结合,MemMamba 为现有 SSM 中限制性的记忆衰减问题提供了原则性解决方案。MemMamba 的成功表明,长序列建模不应只追求"更长",而应关注"如何记住关键信息"。将人类"做笔记"行为形式化为可学习的记忆机制,为高效记忆建模开辟了新范式。
MemMamba 的架构设计表明,通过合理设计的机制,可以有效平衡计算效率与记忆保留能力。其"做笔记"机制不仅解决了 Mamba 的记忆衰减问题,还为其他序列模型提供了可借鉴的思路。状态池的固定容量设计和双阈值触发机制确保了模型在保持线性复杂度的同时,能够有针对性地保留和检索关键信息,避免了传统注意力机制的二次复杂度问题。
在法律领域,合同文档往往长达数万词,MemMamba 能准确记住关键条款的位置和内容,避免因"遗忘"而导致的法律风险。在生物信息学中,DNA序列分析需要处理超长序列,MemMamba 能够保留关键基因信息,为疾病研究提供更准确的分析基础。
尽管 MemMamba 在 400k tokens 上表现优异,但在极端长序列(>1M tokens)上的表现仍需进一步验证。MemMamba 的出现为超长序列建模提供了新思路,有望在自然语言处理、生物信息学和多模态分析等需要处理超长序列的领域产生广泛影响。未来工作将探索扩展至多模态设置、与检索增强系统的集成,以及将 MemMamba 作为高效基础模型,支持复杂现实世界任务中的高保真记忆。这些方向将进一步拓展 MemMamba 的应用范围,推动长序列建模技术的发展。
MemMamba 的核心价值在于其对"记忆模式"的重新思考,它不仅是对 Mamba 的改进,更是对长序列建模范式的重新定义。通过将记忆视为一种需要主动管理和增强的能力,而非被动依赖模型规模的属性,MemMamba 为高效且强大的序列建模提供的新思路。


