资讯列表

LeCun在Meta还有论文:JEPA物理规划的「终极指南」
长期以来,AI 领域一直怀揣着一个宏大的梦想:创造出能够像人类一样直观理解物理世界,并在从未见过的任务和环境中游刃有余的智能体。 传统的强化学习方法往往比较笨拙,需要通过无数次的试错和海量的样本才能学到一点皮毛,这在奖励信号稀疏的现实环境中简直是灾难。 为了打破这一僵局,研究者们提出了「世界模型」这一概念,即让智能体在脑海中构建一个物理模拟器,通过预测未来状态来进行演练。

微信炼出扩散语言模型,实现vLLM部署AR模型3倍加速,低熵场景超10倍
腾讯微信 AI 团队提出 WeDLM(WeChat Diffusion Language Model),通过在标准因果注意力下实现扩散式解码,在数学推理等任务上实现相比 vLLM 部署的 AR 模型 3 倍以上加速,低熵场景更可达 10 倍以上,同时保持甚至提升生成质量。 引言自回归(AR)生成是当前大语言模型的主流解码范式,但其逐 token 生成的特性限制了推理效率。 扩散语言模型(Diffusion LLMs)通过并行恢复多个 mask token 提供了一种替代方案,然而在实践中,现有扩散模型往往难以在推理速度上超越经过高度优化的 AR 推理引擎(如 vLLM)。

陶哲轩:AI让数学进入「工业化」时代,数学家也可以是「包工头」
很多人提到数学研究,脑子里浮现的还是那个画面:一个人,一块白板,来回踱步,等灵感突然降临。 但当今世界最伟大的数学家之一、菲尔兹奖得主陶哲轩却告诉我们:这种「手工业时代」的数学研究模式正处于崩溃边缘,一场由 AI 和形式化证明语言(如 Lean)引领的「工业革命」已经悄然开启。 这一洞察来自陶哲轩最近的一次访谈:视频标题:Terry Tao on the future of mathematics视频链接:,陶哲轩指出,数学研究中存在大量的重复性劳动,如查阅文献、调整他人论文中的参数以及繁琐的计算。

AI设计实战!如何用半天搞定一套品牌营销方案?
「像鸟飞往自己的山」. 归乡与心安,是深植于心的真切向往。 当招聘广告超越“岗位罗列”的刻板模式,设计便成为承载这份向往的情感桥梁。

你聊得很开心的AI女友,背后却是被当做耗材的肯尼亚小伙们
更多作者干货:最近看到一个故事。 让我突然有一个想开系列坑的想法,这个系列,就叫。 《AI 时代浪潮下的新职业》。

入门必读!超实用的AI基础知识科普系列(一)
相关文章:一、AI核心概念名词解释. 在 AI 领域,有许多专业术语,覆盖从底层算法到应用层产品设计。 以下是常见 AI 名词解释列表。

人形机器人登台唱戏:学习人类表演,精准复现戏曲身段
AI在线 1 月 3 日消息,据央视报道,2025《中国科技创新盛典》(总台科晚)1 月 2 日在 CCTV-1 频道 20:00 档播出。 今年在录制地安徽合肥,科晚特别策划科技 戏剧创演秀,创新演绎《徽班进京百戏入皖》。 科晚邀请了多位中国戏剧表演艺术最高奖梅花奖得主,让人形机器人穿上戏服装扮成昆曲中的张生、京剧中的项羽、黄梅戏中的女驸马等角色,与戏曲艺术家同台演绎戏曲经典。

Sebastian Raschka万字年终复盘:2025,属于「推理模型」的一年
随着2025年的日历翻过最后一页,AI 领域再次证明了预测未来的难度。 在这一年,Scaling Law 并没有失效,但它的战场已经转移:从单纯的参数堆叠转向了推理侧的强化。 DeepSeek R1 的横空出世,不仅打破了专有模型的神话,更让 RLVR 和 GRPO 算法成为了年度技术风向标。
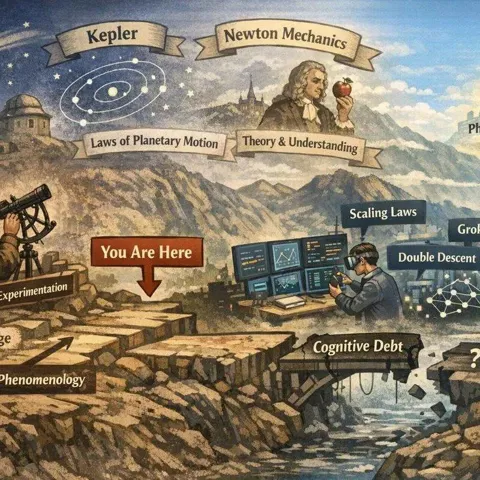
KAN作者刘子鸣:AI还没等到它的「牛顿」
大家新年快乐! 今天和大家分享 KAN 作者刘子鸣最新发布的一篇博客。 过去的一年,我们见证了 Scaling Laws 持续发力,模型能力不断刷新天花板。

自回归也能做强视觉模型?NEPA开启「下一嵌入预测」时代,谢赛宁参与
众所周知,LeCun 不喜自回归,并且还提出了一种名为联合嵌入预测架构(JEPA)的新方向,并且该方向也一直在有新成果涌现。 然而,自回归模型的成功也是有目共睹的,尤其是在语言领域。 那么,生成式预训练在自然语言上的成功能否在视觉领域重现呢?

「辍学创业」的风再次席卷硅谷,但真正的变量从来不是学位
在 80、90 后的成长记忆里,「辍学创业,成为亿万富翁」这类故事流传甚广。 理性分析后都知道,这里面有幸存者偏差,也有个体差异 —— 盖茨、扎克伯格都是哈佛级别,随时能回去拿学位;乔布斯也没有完全离开校园,而是以旁听生的身份自由选课。 但没想到,最近,这股风又刮回来了。

让模型自己找关键帧、视觉线索,小红书Video-Thinker破解视频推理困局
随着多模态大语言模型(MLLM)的飞速发展,“Thinking with Images” 范式已在图像理解和推理任务上取得了革命性突破 —— 模型不再是被动接收视觉信息,而是学会了主动定位与思考。 然而,当面对包含复杂时序依赖与动态叙事的视频推理任务时,这一能力尚未得到有效延伸。 现有的视频推理方法往往受限于对外部工具的依赖或预设的提示词策略,难以让模型内生出对时间序列的自主导航与深度理解能力,导致模型在处理长视频或复杂逻辑时显得捉襟见肘。

Meta重磅:让智能体摆脱人类知识的瓶颈,通往自主AI的SSR级研究
众所周知,「超级智能」是 Meta 持续不变的宏大愿景。 为了尽早达到构建超级智能的目标,扎克伯格在这一年里可谓是大刀阔斧,搞得 Meta 研究部门鸡飞狗跳。 前 Meta FAIR 领军人物 Yann LeCun 锐评:「通往超级智能… 在我看来完全是胡扯,这条路根本行不通。

告别KV Cache枷锁,将长上下文压入权重,持续学习大模型有希望了?
人类已经走上了创造 AGI(通用人工智能)的道路,而其中一个关键方面是持续学习,即 AI 能通过与环境互动而不断学习新的知识和能力。 为此,研究社区已经在探索多种不同的道路,比如开发能够实时更新状态的循环神经网络(RNN),或者试图通过极大的缓存空间来容纳海量历史。 然而,真正的 AGI 或许不应仅仅被动地「存储」信息,而应像人类一样在阅读中「进化」。

LSTM之父率队造出PoPE:终结RoPE泛化难题,实现Transformer的极坐标进化
Transformer 架构中的注意力机制是根据内容(what)和序列中的位置(where)将键(key)与查询(query)进行匹配。 而在近期 LSTM 之父 Jürgen Schmidhuber 的 USI & SUPSI 瑞士 AI 实验室团队的一项新研究中,分析表明,当前流行的旋转位置嵌入(RoPE)方法中的 what 与 where 是纠缠在一起的。 这种纠缠会损害模型性能,特别是当决策需要对这两个因素进行独立匹配时。

重新定义视频大模型时序定位!南大腾讯联合提出TimeLens,数据+算法全方位升级
随着多模态大模型(MLLMs)的飞速发展,模型已经能够很好地理解视频中 “发生了什么(What)”,却无法精准地定位到事件在视频中 “何时发生(When)”。 这种视频时序定位(Video Temporal Grounding, VTG)能力的严重缺陷,已成为制约 MLLM 迈向更精细化的视频理解的主要瓶颈。 长期以来,大量研究致力于设计复杂的模型结构,却忽视了两个关键问题:在数据层面,我们依赖的评测基准是否可靠?

Instagram 负责人莫塞里谈 AI:现如今“眼见已不一定为实”
AI在线 1 月 2 日消息,在 2025 年收官之际,Instagram 负责人亚当・莫塞里用一组长达 20 张图片的内容,集中阐述自己对“无限合成内容”时代的看法。 随着合成影像越来越逼真,现实与虚构正在迅速混淆,而他口中那种更私人化的老式 Instagram 信息流,实际上早已退出历史舞台。 莫塞里说,过去很长一段时间里,人们几乎可以默认照片和视频记录的都是现实发生过的瞬间。

智元机器人将在 CES 2026 展示全系列产品群控舞蹈等
AI在线 1 月 2 日消息,智元机器人今日发布预告,CES 2026 期间,公司将展示全系列产品的群控舞蹈,智元远征 A2 交互 / 运动智能,智元灵犀 X2 交互 / 运动智能,智元精灵 G2 力控臂展示,智元 D1 系列群控展示,灵巧手灵动展示等。 时间:2026 年 1 月 6 日-1 月 9 日地点:美国・拉斯维加斯会议中心展位号:北馆 10715CES(国际消费电子展)是全球顶级消费科技盛会,每年于美国拉斯维加斯举办。 汇聚全球顶尖科技企业与创新者,集中展示人工智能、智能家居、汽车科技等前沿产品及技术,是洞察行业趋势、促成商业合作的核心平台。