中国AI公司MiniMax正式宣布开源其最新大型语言模型(LLM)MiniMax-M1,该模型以超长上下文推理能力和高效训练成本引发全球关注。AIbase整理最新信息,为您带来MiniMax-M1的全面解读。
创纪录的上下文窗口:1M输入,80k输出
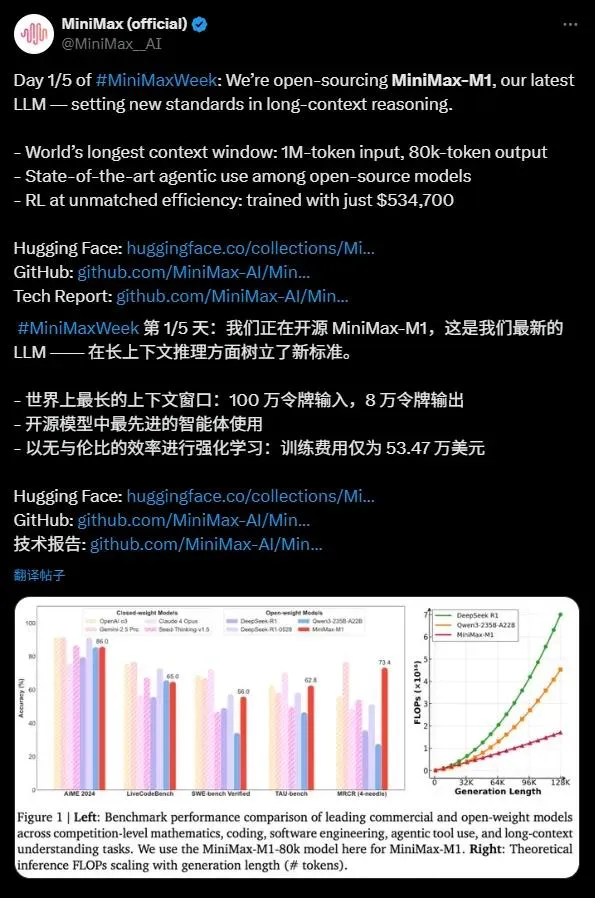
MiniMax-M1以其惊人的100万token输入和8万token输出的上下文窗口,成为目前开源模型中最擅长长上下文推理的佼佼者。这一能力意味着模型能够一次性处理相当于一本小说甚至整个书系列的信息量,远超OpenAI GPT-4o的128,000token上下文窗口。无论是复杂文档分析、长篇代码生成,还是多轮对话,MiniMax-M1都能游刃有余,为企业和开发者提供了强大的工具。
开源模型中的代理能力先锋
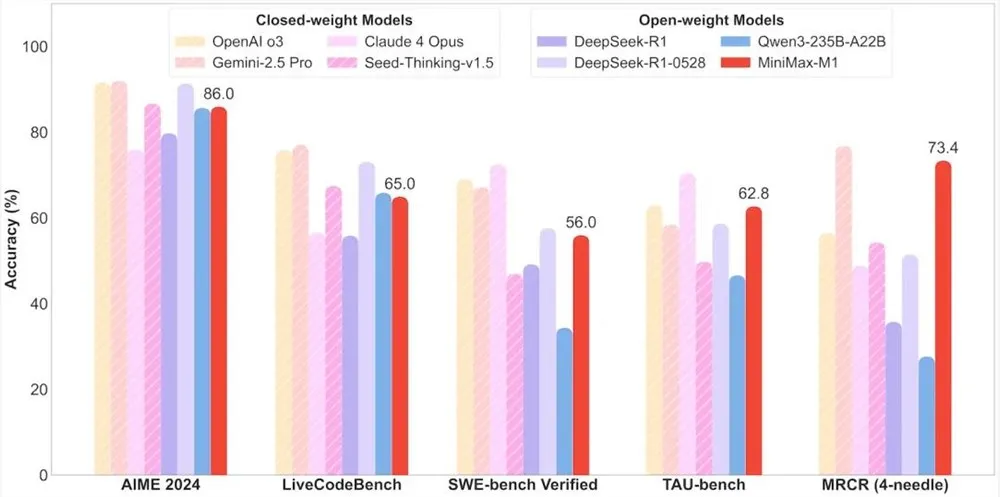
MiniMax-M1在代理工具使用方面表现卓越,性能媲美顶级商业模型如OpenAI o3和Claude4Opus。得益于其混合专家模型(MoE)架构与Lightning Attention机制的结合,MiniMax-M1在复杂任务如软件工程、工具调用和长上下文推理中展现出接近最先进的性能。这种开源模型的强大代理能力,为全球开发者社区带来了前所未有的机会。
超高性价比:53万美元打造前沿LLM
MiniMax-M1的训练成本令人瞩目,仅需53.47万美元,相比DeepSeek R1的500-600万美元和OpenAI GPT-4的超1亿美元,堪称“平价奇迹”。通过高效的强化学习(RL)技术和仅512个H800GPU的硬件支持,MiniMax在短短三周内完成了模型开发。此外,MiniMax首创的CISPO优化算法进一步提升了推理效率,确保重要信息不丢失,同时降低训练成本。
技术亮点:456亿参数与高效架构
MiniMax-M1基于MiniMax-Text-01开发,拥有4560亿总参数,每个token激活约45.9亿参数,通过MoE架构实现高效计算。模型支持40k和80k思维预算的两种推理模式,满足不同场景需求。在数学、编码等推理密集型任务的基准测试中,MiniMax-M1表现强劲,超越了DeepSeek R1和Qwen3-235B-A22B等模型。
开源生态的里程碑
MiniMax-M1采用Apache2.0许可证,已上架Hugging Face平台,供全球开发者免费使用。这一举措不仅挑战了DeepSeek等中国AI企业的开源模型,也为全球AI生态注入了新的活力。MiniMax表示,未来还将发布更多技术细节,进一步推动开源社区的创新。
MiniMax-M1的发布标志着开源AI模型在长上下文推理和代理能力上的重大突破。其超长上下文窗口、高效训练成本和强大性能,为企业和开发者提供了极具性价比的解决方案。AIbase认为,MiniMax-M1的开源将加速AI技术在复杂任务中的应用,推动全球AI生态迈向新高度。


