“预测下一个token”——这个支撑LLM的核心训练机制,正在被强化学习颠覆。
微软亚洲研究院(MSRA)联合清华大学、北京大学提出全新预训练范式RPT(强化预训练),首次将强化学习深度融入预训练阶段,让模型在预测每个token前都能先“动脑推理”,并根据推理正确性获得奖励。
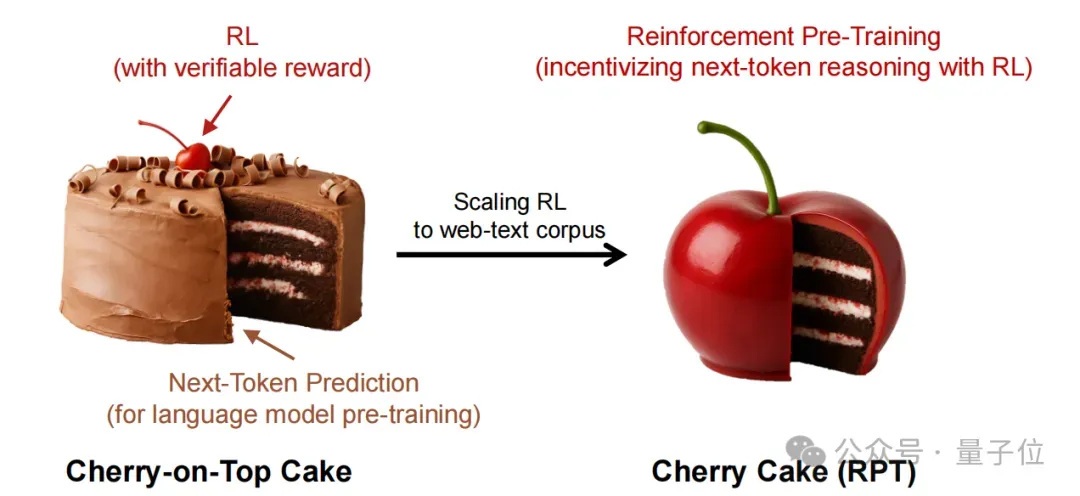
传统预训练依赖海量文本进行自监督学习,模型通过简单预测下一个token建立语言能力,作者将之比喻为一块蛋糕胚,而RL只是作为上面点缀的一颗樱桃。
现在RPT要做的就是用樱桃直接做蛋糕,即将这一过程重构为推理任务,促进模型更深层次理解和提升下一个token的预测准确度。

那这块樱桃蛋糕到底怎么做?详细烘焙流程我们接着往下看。
将强化学习引入预训练
传统的预训练方法采用自监督的下一个token预测任务,而RL通常承担微调LLM的功能,使其与人类偏好对齐或者增强复杂推理。
然而基于人类反馈的强化学习(RLHF)过度依赖昂贵数据,且模型容易受到奖励破解;可验证奖励的强化学习(RLVR)也会受到数据稀缺的限制,只能应用于特定领域的微调。
为了让强化学习更好地作用于LLM,团队提出的全新范式强化预训练RPT,激励使用RL进行有效的Next-Token推理任务,将预训练语料库重构为推理问题集,推动预训练从学习表面的token相关性转为理解深层含义。
模型首先需要对多个token生成一个思维链推理序列,涉及多种推理模式(如头脑风暴、自我批评和自我纠正),然后再为下一个token生成预测。
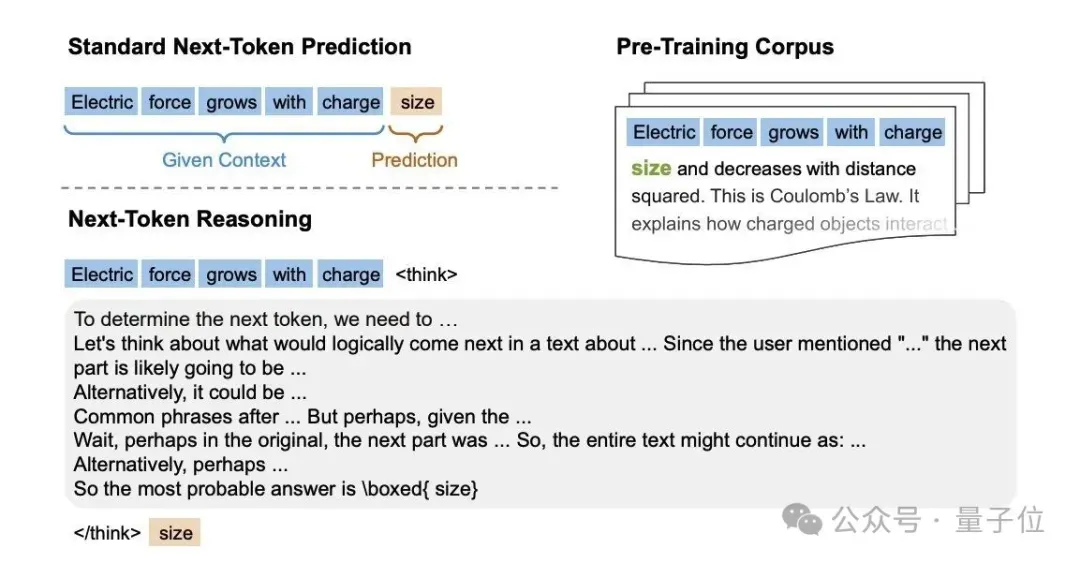
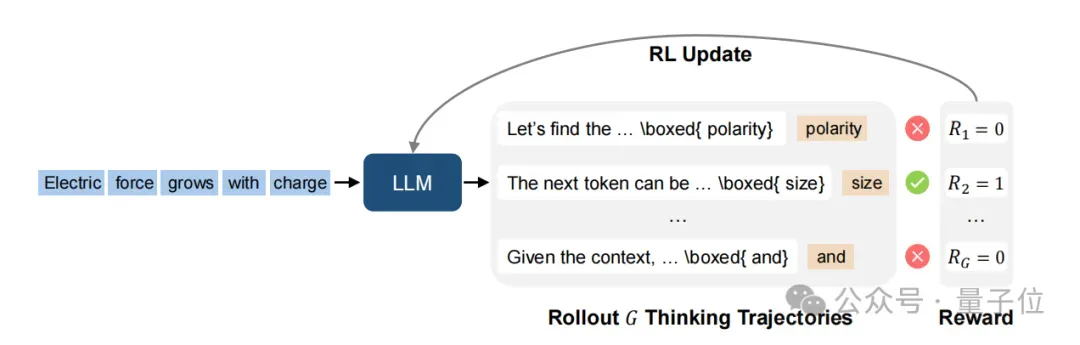
具体来说,RPT就是通过让LLM同策略(on-policy)执行,以生成多条不同的思维轨迹,每条轨迹包含中间推理步骤和对下一个token的最终预测。
引入前缀匹配奖励,验证预测的正确性。如果预测与真实token匹配,则分配正奖励1,反之为0。该奖励信号将用于更新LLM,以鼓励生成能准确延续上下文的轨迹。
团队使用包含4428个竞赛数学问题及答案的OmniMATH数据集,并通过计算下一token的熵和设定阈值,进行数据过滤,只保留更难预测的token参与训练。
另外采用Deepseek-R1-Distill-Qwen-14B作为基础模型,使用GRPO算法和8K的训练长度,批大小为256个问题,每个问题采样8个响应。
更深层次的推理
实验表明,与R1-Distill-Queen-14B相比,RPT-14B在三种难度(简单、中等、困难)上均实现了更高的下一个token预测准确率,优于标准下一token预测基线和使用推理的预测基线。
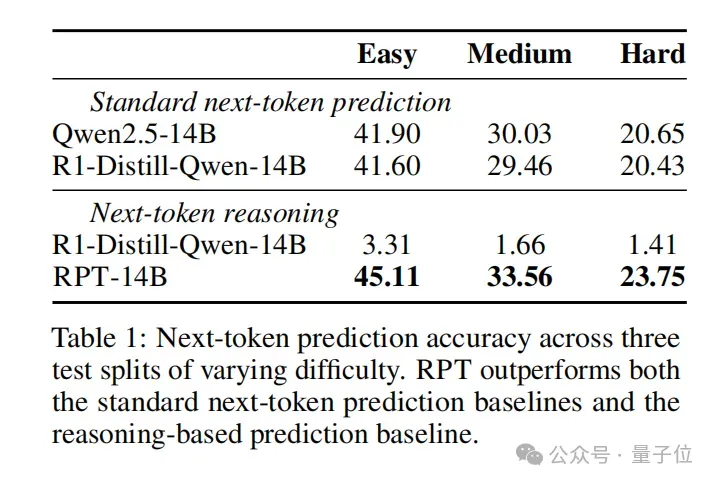
在性能上,也可与更大的模型R1-Distill-Queen-32B相媲美,说明RPT能有效捕捉token生成背后的复杂推理信号,并在提升LLM的语言建模能力方面拥有巨大潜力。
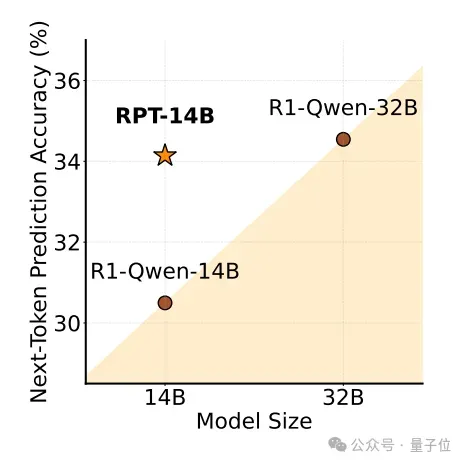
RPT在跨难度的训练计算方面,也表现出清晰的幂律缩放 (Power-law Scaling),预测准确性随着计算的增加而不断提高,并且与理论曲线紧密拟合。
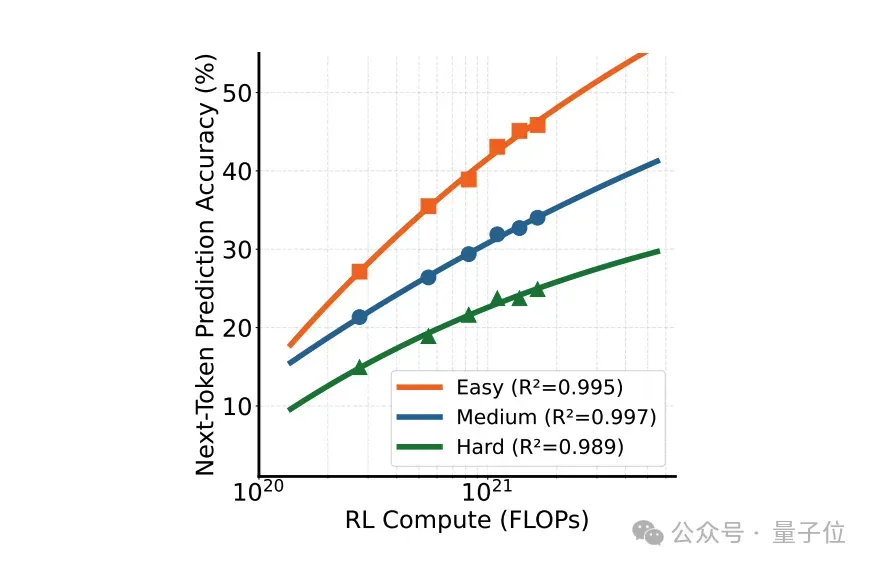
与传统的使用下一个token预测相比,在具有可验证答案的问题(即Skywork-OR1)上,使用RL微调RPT模型显示出更强的推理能力。
在数据有限的情况下,可以快速将从下一token推理中学习到的强化推理模式迁移至最终任务。
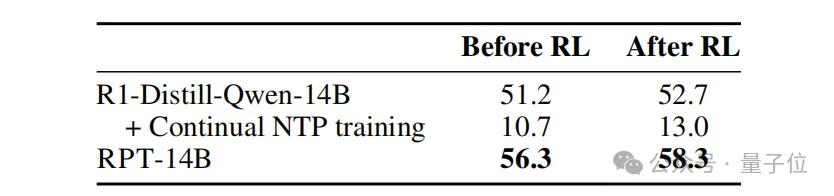
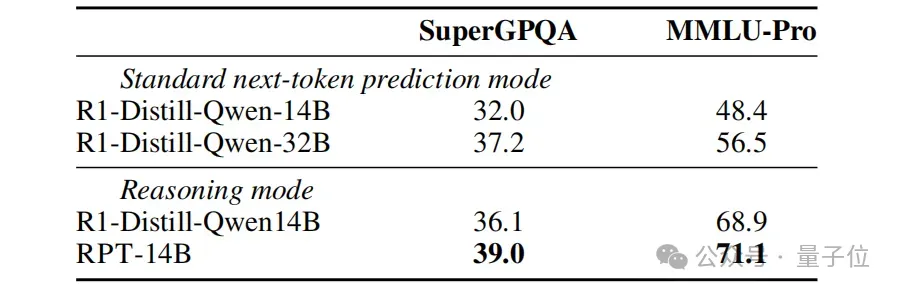
另外模型在SuperGPQA和MMLU-Pro基准测试上的零样本评估表明,RPT-14B不仅优于R1-Distill-Queen-14B,还在推理模式中显著超过了R1-Distill-Qwen-32B。
最后团队还对推理轨迹进行分析,发现与显式问题解决模型相比,RPT-14B采用了更多的假设生成、替代方案的考虑以及对结构线索甚至颗粒度token级细节的反思。
既包含高级语义理解,又包含低级文本特征,说明RPT在训练过程中会培养更深层次的推理习惯。

One More Thing
这块著名的“蛋糕论”最早出自图灵奖得主Yann LeCun在2016年的演讲。
如果智能是一块蛋糕,那么大部分蛋糕都是无监督学习,蛋糕上的裱花是监督学习,而蛋糕顶部的樱桃则是强化学习。

而现在试图用强化学习碾碎这块蛋糕的,还有OpenAI。

在上个月红杉组织的AI Ascent活动中,OpenAI科学家Dan Roberts就提及了他们在将RL置于模型预训练过程中的转变。
在GPT-4o中全是传统预训练计算,在o1中引入了一些强化学习运算并且取得了不错的效果,在o3中则引入更多,他们预计在未来的某一代模型中,将会完全由RL计算主导。

有理由相信,未来RL或许将在LLM预训练过程中掀起更大的风暴,且让我们拭目以待。
论文链接:https://arxiv.org/abs/2506.08007