编辑 | 云昭
出品 | 51CTO技术栈(微信号:blog51cto)
如果让大模型去外包平台去接单,它真的可以赚到钱吗?
现在终于有专业的评测机构站出来公布答案了。不用硬夸AI,事实是让它接单,它会饿死。
今天一早,大洋彼岸的“AI评测”王牌企业Scale AI刚刚发布了一项非同寻常的新指标:RLI(远程劳动力指数)。
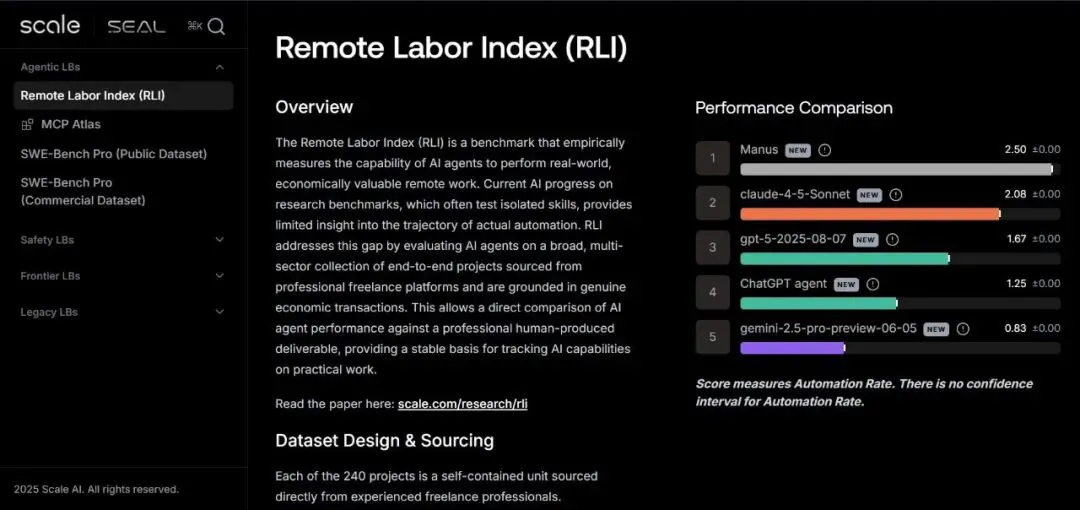
顾名思义,就是专门用于实证评测大模型或者Agent产品能够独立执行真实且具经济价值的远程工作的能力。
它回答的是一个盘桓在AI圈上空的许久没有解决的问题——AI真的可以自动化替代人类有价值的工作吗?
这一基准也第一时间得到了前CEO Alexandr Wang的转发。
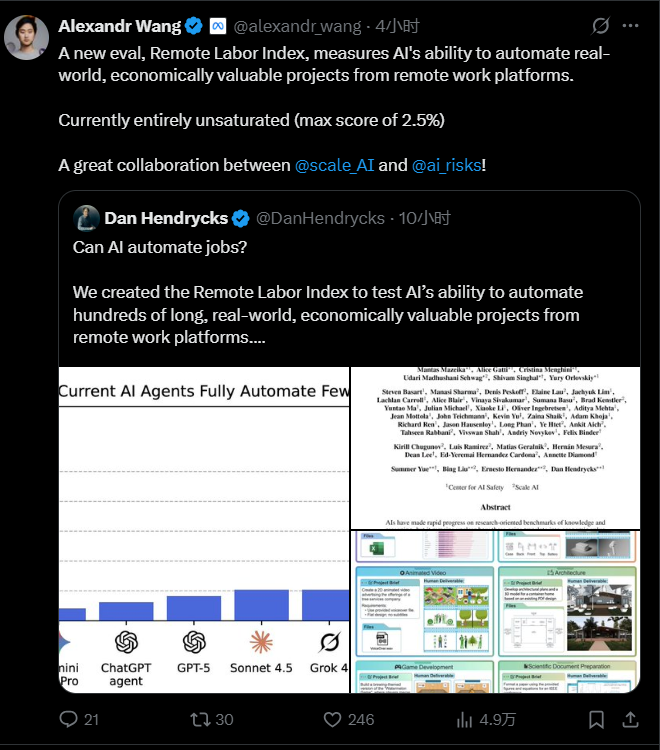
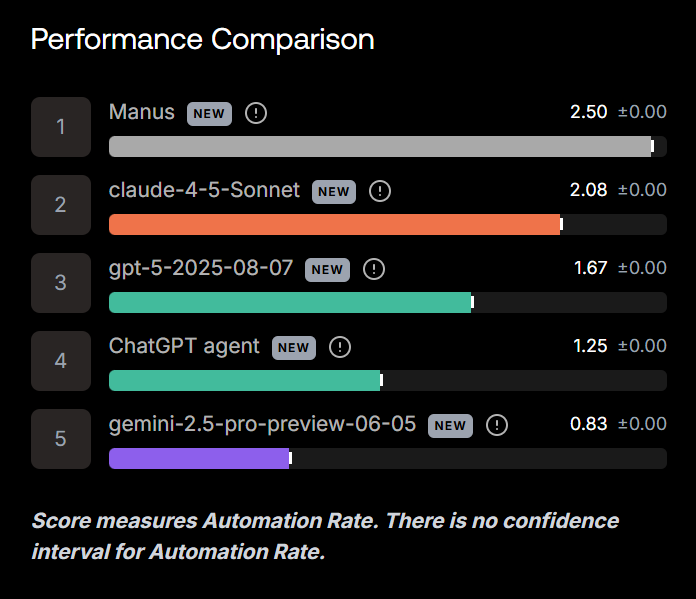
结果显示,不管是GPT-5,还是Claude Sonnet、Gemini,亦或是主打通用Agent的Manus,都统统被人类接单首踩在泥土里,真实水平垫底。
1.让大模型去赚外快,打工秒变打脸
如果让GPT去知名接单平台赚任务,是否真的可以赚到钱?
这个问题,最近被 Scale AI 认真地做了一遍实验——他们推出了一个名为 “Remote Labor Index(远程劳动指数,RLI)” 的新基准。
让AI去干真实的自由职业工作,然后看看能不能交差。
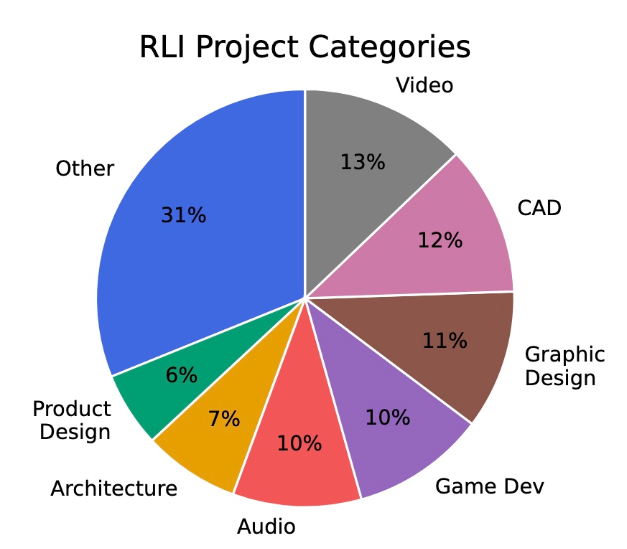
Scale把AI模型当作真正的“打工人”,从Upwork平台上挑了240个真实项目,涵盖写报告、修图、建3D模型、做音效、写代码……然后给AI发任务,看它能否完成、能赚多少钱、能替代多少人工成本。
这些项目都是ScaleAI精挑细选出来,真能交易的项目,平均每单高达630美刀以上。
总经济价值: 143,991 美元
项目难度和价值: RLI 项目反映了真实自由职业工作的复杂性,远远超过了以往的基准。
人类平均完成时间: 28.9 小时(中位数:11.5 小时)
项目平均价值: 632.60 美元(中位数:200 美元)
 图片
图片
结果出来之后,全场沉默了。在RLI榜单中,所有AI模型的表现几乎都跌到了谷底。
2.98% AI提交的项目被“老板退货”
结果是,这240个项目,AI提交的作品,即便成绩最好的选手,也仅被老板认可了6个,234个项目都被退货了。
而更没想到的是,这位最优生,不是GPT-5,也不是Sonnet,而是今年爆火的黑马 Manus,自动化率为 2.5%。
 图片
图片
其他模型表现更惨:
Claude Sonnet 4.5、GPT-5、Gemini 2.5 Pro、ChatGPT Agent……全部“翻车”,没一个能稳定交付客户满意的作品。
而且,据ScaleAI放出的官方博文介绍,AI虽然很高产,但交付的质量实在是没眼看,可以说全军覆没。平均每个项目的人类用时是28.9小时,AI花同样的“算力时间”,多数交付品却被判为“不合格”。
人工评审总结了失败原因:
- 45.6%:作品质量太差,像小学生练手。
- 35.7%:交付不完整,视频截断、文件丢失。
- 17.6%:格式错误、文件损坏。
- 14.8%:视觉或逻辑不一致,比如3D建筑的不同视角完全对不上。
唯一的亮点,是在部分音频处理和图片生成任务中,AI能完成得像模像样。比如做广告图、分离人声这类“创意但封闭”的任务。
在同步发布的官方视频中,美人工智能安全中心执行主任 Dan Hendrycks 和 Scale AI 研究主管Bing Liu指出:
AI完成得较好的少数任务多来自创意领域,如音频与图像生成,比如为游戏制作音效、剪辑配音、生成Logo等。这些领域的AI已经能与人类专业人士旗鼓相当。
但凡涉及跨文件逻辑、复杂工具链、长期一致性……AI都露馅了。
但更复杂的任务——那些需要多步骤执行、严格遵守说明、持续数小时甚至更久的项目——仍会让最强的模型出错。
所以,Scale团队得出了很残酷的结论:
“AI绝对自动化几乎为零。”AI还远远不能替代专业远程劳动。
3.这项基准报告,意义有何不同
小编看来,这项新发布的基准,意义非同寻常。
因为,要知道现在AI圈为什么非常卷?其中很大一部分原因,就在于大家一直在已有的基准评测上卷来卷去。从一开始的文科能力再到理科题目,再到今年的各种Coding、Agentic能力。
但问题是,卷来卷去,我们在实测中发现,结果想要勉强满意,大概率都是要多次抽卡的。
所以,既然已有的测评数据集已经不能用来评估人类真正所需的模型能力,我们就必须设计一种新的评估或测评基准,一种真正可以评估如何评价智能体是否真的在做事的方法。
这也是为什么Scale AI要构建一个衡量完整自动化产出的基准,而不是只测单项技能的原因。
如果只测写作或数学等单项技能,就无法评估AI是否能在长时间跨度内持续完成任务。模型可能在某个环节出错,导致整体无效。这些问题在孤立技能测试中很难被捕捉。
我们希望关注那些人类需要花数小时或数天完成的任务,这样的评估更具生态真实性,更能反映现实中的工作状态。
毕竟,真实工作并非一连串孤立任务,它涉及上下文整合、信息综合和跨任务协作。只有把这些因素都处理好,才能真正胜任工作。
因此,我们关注的不是AI是否能解封闭题,而是能否完成一个完整的工作流。
4.许多知名测评基准已过时
那么,究竟这样一份“让AI去自由职业接单平台的测评”,跟其他知名基准,比如GDP-eval、SWE-bench 有何不同?
在采访中,Hendrycks 给出了答案:原来那些基准要么过于封闭,要么测得不准,要么已经过时。
以“humanity's last exam”为例,那类基准是封闭题、非行动型的;而RLI是开放的、具备行为导向的。
GDP-val虽然试图覆盖经济任务,但它声称AI已接近人类水平,这显然不现实。如果真那样,世界早已截然不同。
SWE-bench主要测AI在软件工程领域(如Django类问题)的能力,但业内普遍认为,它对实际开发影响的预测力越来越低,比如对Cursor等工具的应用参考价值有限。
这些基准要么过于封闭,要么测得不准,要么已“封顶”失去预测效度。而RLI旨在更开放、更贴近经济实况,覆盖更广泛的真实任务与项目。
这里,他们还提到了用合成任务来做测试集的不合理之处。“合成任务往往缺乏真实性!”
Liu Bing:为什么要在真实付费任务上测试,而不是合成任务?
Hendrycks :因为真实工作中充满各种边缘情况,而没有什么比现实更复杂。若想了解AI在现实世界的影响,就必须使用包含这些复杂情境的数据集,而不是人造的“假问题”。合成任务往往缺乏真实性。比如,让人编个“刁钻的机器学习题目”,那只是测试数学能力,而非真实工程工作。因此,RLI要立足现实任务,涵盖足够多的复杂案例,才能检验模型在真实挑战中的适应力。
5.智能不等于生产力
那么,这份“AI劳动绩效表”,究竟该如何看待呢?
首先,需要为所有打工人庆祝一番:AI距离替代人类干活,还很远。
Hendrycks 在采访中指出,目前模型在RLI上准确率不足10%,这意味着,在我们测试的所有自由职业任务中,即便是最好的AI模型,也只有不到十分之一的任务能达到客户可接受的专业水准。
这提醒我们,工作不仅仅是回答问题或生成内容,还包括理解上下文、运用工具,并完整地完成任务——而这是当前AI明显欠缺的。
其次,这可以说是全球首次用来评估AI“干活能力”的基准。
它和以前那些论文题型的AI测试(比如MMLU、GSM8K)不同,后者主要是测智商,而RLI关注的是真实世界的交付:
能不能打开文件?能不能保存格式?
能不能从A到Z独立完成一份交差作品?
这才是AI走出实验室,进入社会的真正门槛。
只不过,如今的结果说明还可以说只是万里长征第一步,人类还需要为AI收拾烂摊子。AI能生成,但它还不会交差;它可以写文案、画图、写代码,但在整合和收尾环节一塌糊涂。
正如Hendrycks在采访中最后所说的 ,最关键的一点是,AI的进步必须以真实经济价值为衡量标准。
RLI告诉我们,“智能”并不等于“劳动”。真正的自动化,需要AI全面掌握语境、具备可靠性与判断力。
6.暴风前的平静:别大意,AI自动打工就在眼前
但别急着对AI失望。Scale AI 团队发现,虽然AI“干不好活”,但进步是可测的。
他们用Elo评分体系追踪各模型的相对表现——新一代模型比旧版有稳步提升,哪怕整体分数还低。
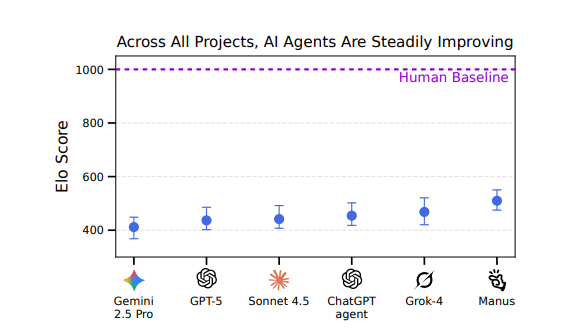 图片
图片
也就是说,AI距离“自动打工”虽然还远,但它的学习曲线是清晰的。
或许当我们下次再测,Automation Rate从2.5%升到10%、30%、50%——有了新榜单可以刷,早晚,“AI劳动力市场”就真的要诞生了。
别忘了,就在昨天,刚完成重组的OpenAI就马不停蹄的宣布了它们的3年目标:2026年9月之前,让一个自动化的AI研究实习生在数十万张GPU上运行,并在2028年3月之前实现真正的自动化AI研究员。
要实现这个任务,安全策略、价值观对齐、算力、资金的问题显然要交给OpenAI这个庞然大物去处理,但具体该如何评价“AI自动化”能力,恐怕就要从今天Scale AI提出的RLI开始了。
Ps:小编突然想到今年6月,强化学习之父Sutton在智源大会演讲中提到的AI发展的新阶段。
“高质量的人类数据资源已经几乎被用到极限……
如果我们希望 AI 拥有真正的创造力和适应能力,它必须进入一个全新的阶段,也就是‘经验时代’。在这个阶段,AI 不再依赖固定的数据集,而是通过自身与外部世界的交互,从中获取经验并不断进化。”
那看来,从这个测评基准开始,AI真得要进入“接管真实人类派单”的经验时代了!
论文地址也为大家扒下来了,enjoy!
论文链接:
https://scale.com/research/rli
https://static.scale.com/uploads/654197dc94d34f66c0f5184e/Remote_Labor_Index%20(4).pdf


