端到端多模态GUI智能体有了“自我反思”能力!南洋理工大学MMLab团队提出框架GUI-Reflection。

随着多模态大模型的发展,端到端GUI智能体在手机、电脑等设备上的自动化任务中展示出巨大潜力。它们能够看懂设备屏幕,模拟人类去点击按钮、输入文本,从而完成复杂的任务。
然而,当前端到端GUI多智能体的训练范式仍存在明显的瓶颈:当前模型往往使用几乎完美的离线演示轨迹进行训练,使得模型缺乏反思和改正自身错误的能力,并进一步限制了通过在线强化学习激发和提升能力的可能。
GUI-Reflection的核心思想是在智能体的各个训练阶段引入 “反思与纠错”机制,这一机制贯穿预训练、监督微调和在线训练全过程,模拟了人类“犯错→反思→重试”的认知过程。
- GUI预训练阶段:提出GUI-Reflection Task Suite任务套件, 将反思纠错能力进一步分解,让模型在预训练阶段框架让模型初步接触反思类任务,为后续打下基础。
- 离线监督微调阶段:构建自动化数据管道,从已有离线无错轨迹中构建带有反思和纠错的行为数据,让模型成功习得反思纠错行为。
- 在线训练阶段:搭建分布式移动端GUI学习环境,并设计迭代式反思反馈调优算法,让模型在与真实环境交互中进一步提升相关能力。

GUI-Reflection框架简介
GUI-Reflection 是一个贯穿训练全过程的框架,旨在系统性地赋予多模态GUI智能体以“自我反思与纠错”的能力。该框架由三大关键阶段组成,分别对应模型能力的认知启发、行为习得与交互强化:

1 GUI预训练阶段:启发反思相关能力
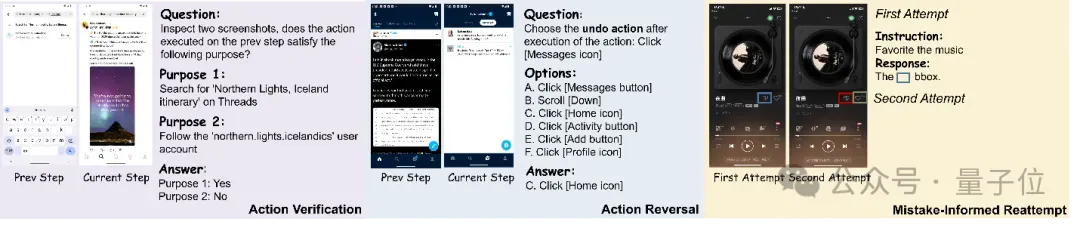
现有GUI预训练多聚焦于界面理解和操作感知,而忽视了反思相关的原生能力构建。GUI-Reflection 首次提出专为反思设计的GUI-Reflection Task Suite,包含三类关键任务:
- Action Verification(动作验证):判断某一步操作是否达成了预期目标,训练模型识别执行偏差。
- Action Reversal(动作回滚):学习如何撤销错误操作,回退到正确的任务路径。
- Mistake-Informed Reattempt(基于错误的再尝试):在明确过去错误的前提下,生成新的、改进的操作策略。
这些任务将复杂的反思行为分解为更细粒度的认知能力,使模型在预训练阶段即具备初步的“反思意识”。
2 离线监督微调阶段:自动化构建纠错轨迹
针对当前GUI数据集缺少犯错和纠错数据的问题,GUI-Reflection设计了一个自动化反思纠错数据生成管道。该方法从已有成功轨迹中自动构造出“带错轨迹”与“纠错行为”,实现数据维度上的“反思注入”。具体包括:
- 目标扰动生成错误行为:通过修改原始任务目标,使模型原本的动作在新目标下变成“错误”动作,并构建对应的反思错误行为数据。
- 行为插入模拟失误:向成功轨迹中插入无效操作,让模型对无效错误操作做出反思并尝试新的正确操作。
整个数据增强过程无需人工标注,使得GUI模型在离线微调阶段习得了有效的反思行为。
3. 在线训练阶段:搭建反馈式反思回路
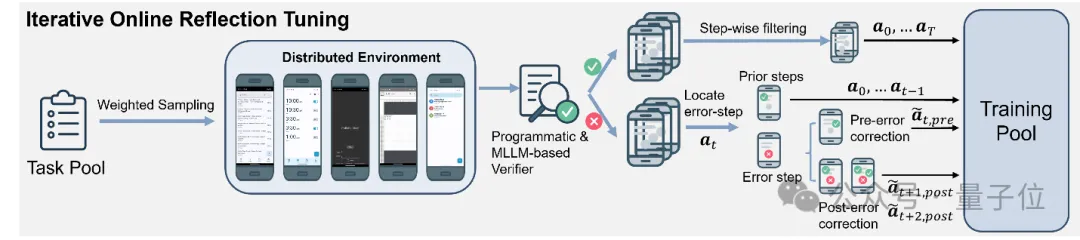
为了进一步提升模型在真实环境中的适应能力,GUI-Reflection构建了一个分布式安卓模拟环境,涵盖11个app和 215 个任务模板,支持高并发交互。基于此环境,GUI-Reflection设计了一种自动化迭代式在线反思调优算法:
- 成功轨迹将被细粒度验证,仅保留每一步的有效执行;
- 失败轨迹则被自动定位错误步骤,并为该步骤自动生成前向修正(Pre-Error Correction)与后向反思(Post-Error Reflection)操作。
通过多轮训练迭代与动态采样策略,模型逐步优化其容错率、恢复能力与复杂规划水平。
实验结果
GUI-Reflection Task Suite测评结果
通过在构建的GUI-Reflection Task Suite上进行评测发现:
- 通用大模型(如 GPT-4o、Gemini)在GUI任务中具备不错的原生反思能力,能够初步识别错误并进行合理推理;
- 而小规模开源模型在这方面能力明显不足,尤其在面对失败操作时难以自我修复;
- 更关键的是,现有的标准GUI预训练流程,反而会削弱模型原本具备的反思能力。
当在预训练阶段引入反思导向任务数据,即使是较小规模的模型,也能显著提升其在反思相关任务中的表现,甚至达到接近闭源大模型的水平。
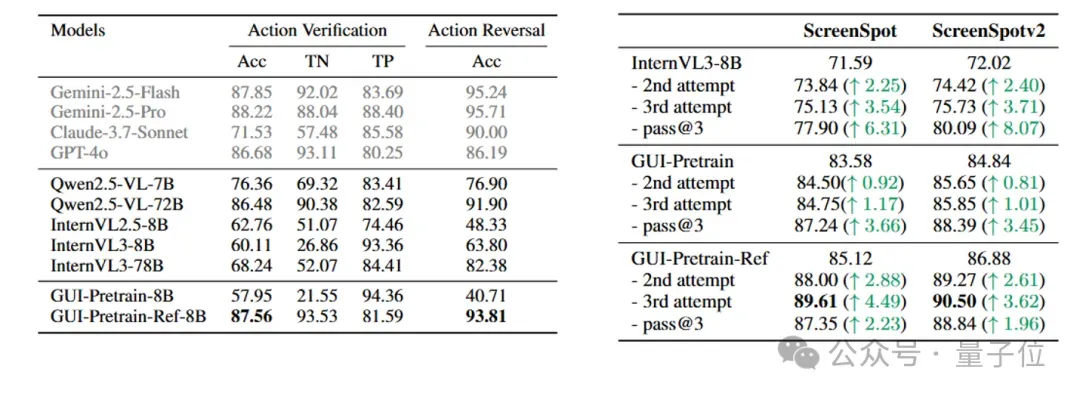
反思行为的有效性
在评测环境中进行实验后观察到:
- 在离线监督微调阶段引入反思类数据,可以显著提升模型的任务完成表现;
- 进一步结合在线反思调优算法进行训练,模型的成功率持续提升,表现出更强的泛化能力与稳定性。

GUI-Relection-8B模型在AndroidWorld基准中也实现了 34.5% 的成功率,证明了GUI-Reflection框架的有效性。这一系列结果充分表明:在多个训练阶段显式引入反思机制,是提升GUI智能体能力的关键路径,而不仅仅依赖大规模演示数据或强模型本身。

反思行为样例
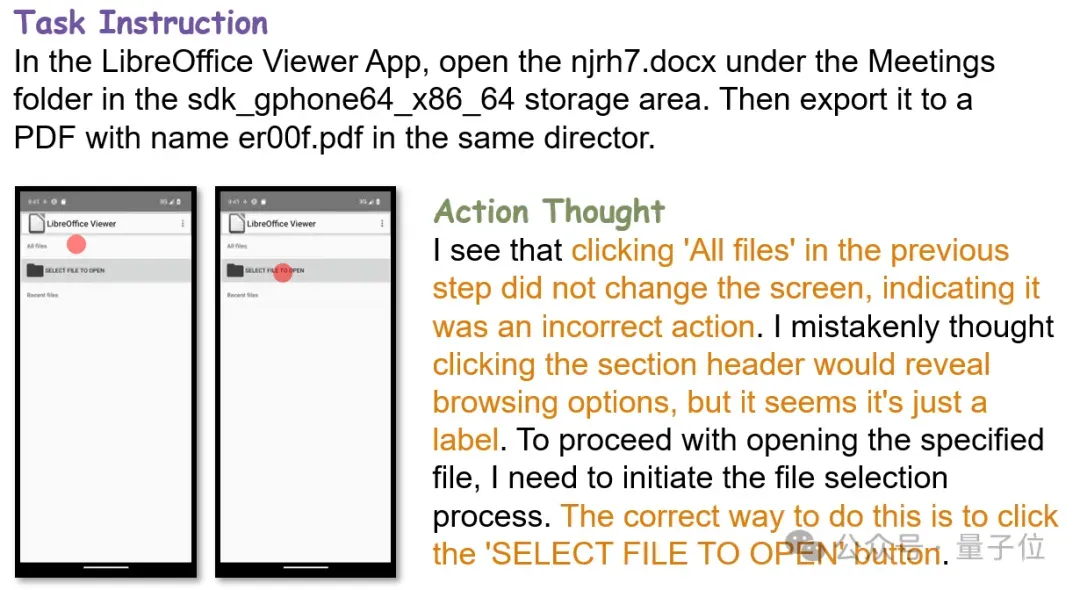
模型能够成功认识到之前操作的错误并采取对应操作进行回退。
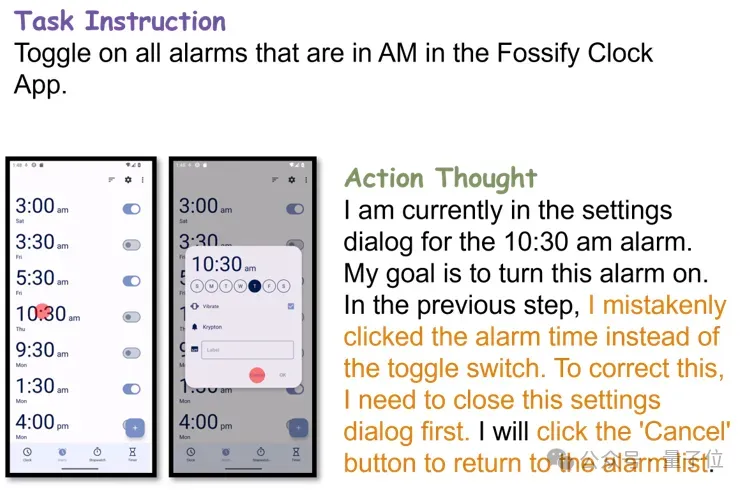
对于不熟悉或不确定的操作,模型可以根据之前的错误做出新的尝试。
结语
GUI-Reflection为端到端多模态 GUI 智能体注入了全新的“自我反思”能力。从预训练、离线微调到在线交互,它系统性地打通了“犯错—反思—修正”的认知闭环,使模型在面对真实环境中的不确定性时,能够更加鲁棒、灵活地应对各种突发状况。
论文链接:https://arxiv.org/abs/2506.08012项目主页:https://penghao-wu.github.io/GUI_Reflection数据和模型HF链接:https://huggingface.co/collections/craigwu/gui-reflection-683c7fb964b44c0cca842290
代码仓库链接:https://github.com/penghao-wu/GUI_Reflection


