只需要动动嘴就可以驱动GUI代理?
由美团和浙江大学联合推出的GUIRoboTron-Speech——让用户解放双手,直接对计算机“发号施令”。

这是首个能够直接利用语音指令和设备屏幕截图进行端到端(End-to-End)决策的自主GUI智能体,旨在为用户提供更直接、高效且无障碍的交互体验。
从文本到语音,智能代理的下一次进化
当前,以大型语言模型(LLMs)为核心的自主GUI智能体,已能通过文本指令自动执行跨应用、多步骤的复杂任务,极大地提升了用户的工作效率。但这种对文本的依赖,限制了其在更广泛场景下的应用。
试想一个常见的家庭场景:在对家中的公用电脑发出指令“打开我的浏览器”时,一个仅能理解文本的智能体将不知所措——它无法分辨指令发出者是家庭中的哪一位成员,自然不知道什么是“我的”浏览器。
然而,一个能够直接处理语音的智能体,则可以通过分析独特的声纹特征,准确识别指令发出者的身份,并打开该成员的个性化Google浏览器界面。
这正是语音模态所蕴含的独特价值——它不仅传递了指令内容,更包含了身份、情绪等丰富的非言语线索,而这些对于实现真正个性化和智能化的交互至关重要。
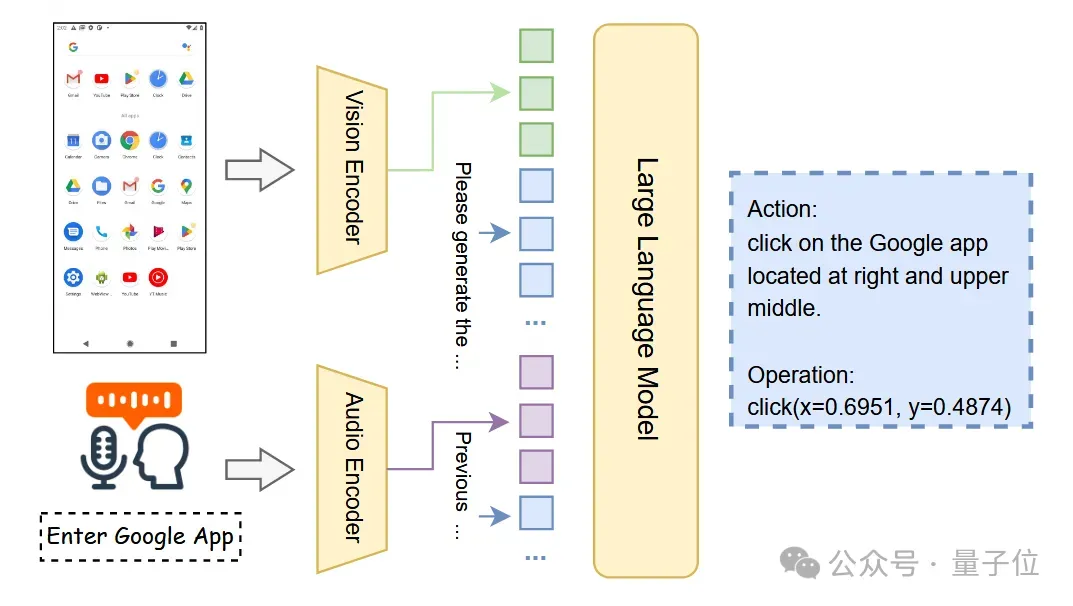
传统的解决方案,如采用“语音识别(ASR)模型转录+文本GUI代理”的级联方式,不仅会增加系统的计算负担和延迟,更会在转录过程中丢失宝贵的声学信息。
而GUIRoboTron-Speech通过构建端到端的语音GUI代理,可直接利用语音指令和设备屏幕截图进行决策。
构建端到端的语音GUI代理
GUIRoboTron-Speech团队设计了一套严谨而创新的研发路径,其核心方法可概括为以下几个关键步骤:
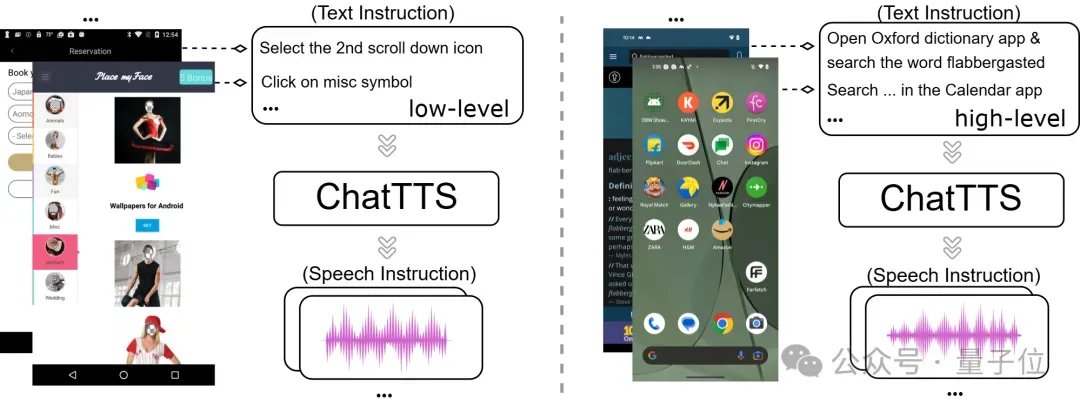
第一步,高质量语音数据集的生成
面对业界缺乏用于训练GUI智能体的语音指令数据集的挑战,研究团队提出并验证了一种高效的解决方案。他们利用一个先进的随机音色文本转语音(TTS)模型,将现有的大规模文本指令数据集,转换为包含多种说话人风格和音色的高质量语音指令数据集。这一策略不仅成功解决了数据稀缺的难题,也为后续模型的训练奠定了坚实的基础。
第二步,渐进式训练框架:分阶段赋能
为了让模型逐步掌握复杂的能力,GUIRoboTron-Speech的训练过程被划分为两个核心阶段:
基础Gounding阶段(Grounding TrainingStage):在此阶段,模型的核心任务是学习建立语音指令与GUI界面视觉元素之间的精确对应关系。即当听到“点击‘确定’按钮”时,模型需要准确理解指令的意图,并在截图中定位到“确定”按钮的视觉特征与坐标。
规划Planning阶段(Planning Training Stage):在掌握了基础的“听说看”能力后,模型进入规划与推理训练。在这一阶段,它将学习如何理解并执行多步骤的复杂任务,例如“先登录账号,然后找到最新的邮件并打开附件”,展现出作为智能代理的逻辑推理与任务规划能力。
第三步,启发式混合指令训练策略
由于预训练的基座模型(Foundation Models)大多在以文本为核心的数据上进行训练,存在着严重的模态不平衡(Modality Imbalance)问题,即模型可能在训练中倾向于依赖其更为熟悉的文本信息,而忽略新引入的语音模态。
为解决此问题,研究团队独创了一种启发式混合指令训练策略(Heuristic Mixed-instruction Training Strategy)。该策略在训练过程中,巧妙地混合使用语音指令和文本指令。
通过这种方式,强制模型同等地关注并处理来自两种不同模态的输入,有效缓解了模态偏见,确保模型能够稳健地从语音信号中直接提取和理解指令意图。
性能评估

使用不同模态的指令进行grounding能力训练,通过性能对比可以看到,直接使用speec-based指令相比text-based指令会低1.6%的平均定位精度,而使用混合指令训练策略可以缓解预训练多模态基座的模态不平衡现象,相比text指令甚至取得了更好的性能。
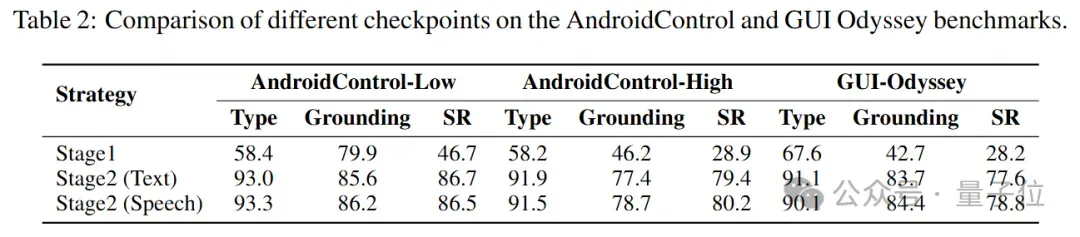
在planning能力训练上,基于grounding阶段混合指令训练得到的checkpoint,speech-based指令相比text-based指令也取得了更好的性能。
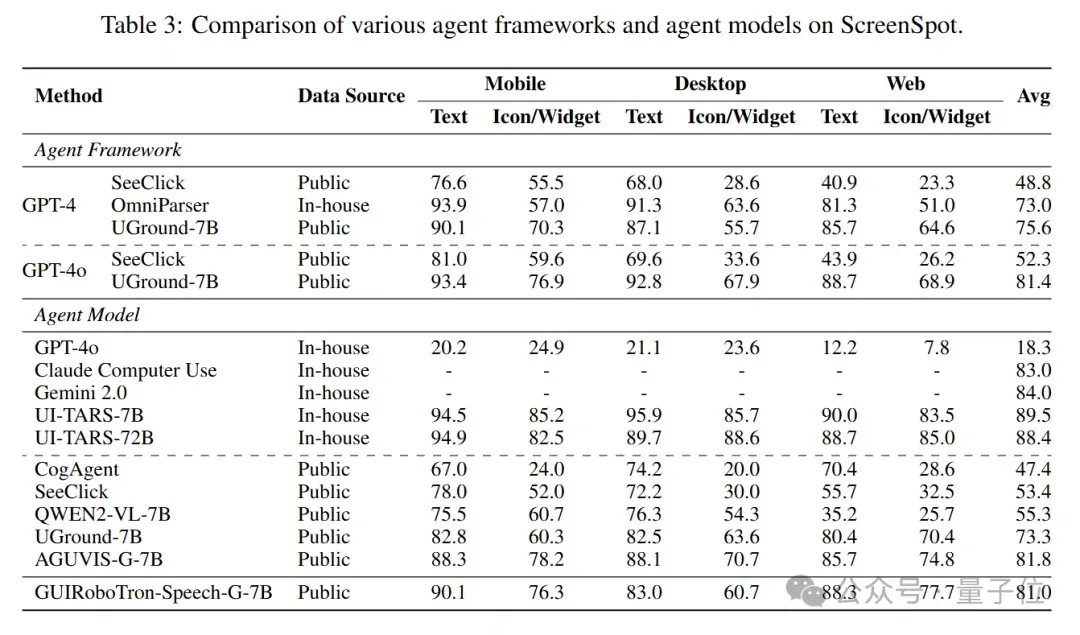

此外,GUIRoboTro-Speech在与同参数量级和训练数据源的基线对比下,同样取得了领先的地位。
在AndroidControlLow上使用公共数据时,GUIRoboTron-Speech在所有方法中实现了最高的平均成功率(+1.3%),在AndroidControl-High上,它在所有SOTAs中实现了最高的平均成功率(+7.8%)。在GUI-Odyssey上,它的排名仅次于使用内部数据的UI-TARS。
这些结果表明,GUIRoboTron-Speech作为接受用户语音指令的GUI代理,具有很高的可行性,能够通过多轮推理和动作预测实现用户目标。这表明speech-based指令在GUI Agent这类用户意图清晰的场景下的可能性。
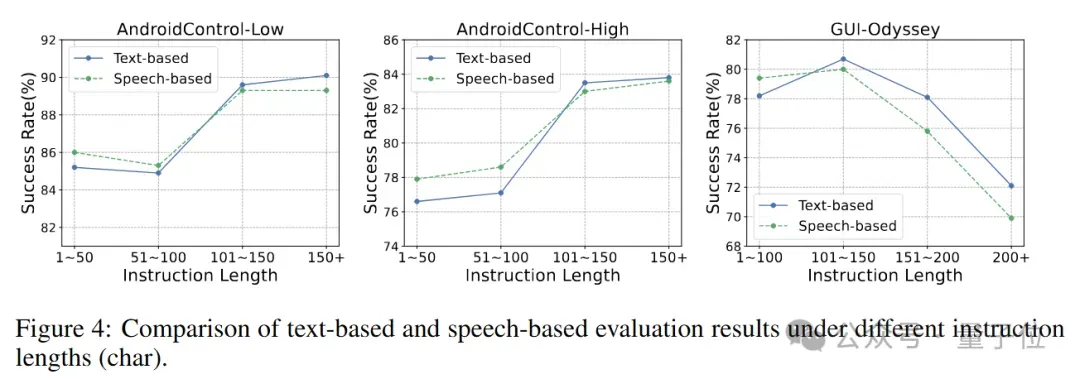
最后,GUIRoboTro-Speech团队还针对指令长度对GUI Agent任务执行成功率的影响做了分析,发现在指令长度较短(用户意图清晰)的场景,speech-based指令相比text-based指令能取得更好的表现,然而随着指令长度上升,text-based指令展现出其承载复杂用户意图的特质。
如何更好的承载复杂的用户指令以取得稳定的任务成功率,将是speech-based GUI Agent未来的方向之一。
论文链接:https://arxiv.org/abs/2506.11127
Github仓库链接:https://github.com/GUIRoboTron/GUIRoboTron-Speech


