资讯列表

阿里云刘伟光:2026 年初将看到 AI 应用的再一次爆发
AI在线 12 月 31 日消息,据《财新》今日报道,阿里云智能集团资深副总裁刘伟光在接受采访时指出,2026 年初会看到 AI 应用的再一次爆发,他认为,未来几年,各类企业的 AI 预算将是目前 IT 市场预算的 10 倍。 应用的爆发来自模型的快速迭代。 “AI 的影响在于,过去技术标准的迭代周期是五年到十年,现在变成了两年到三年,大模型更是以星期为时间单位在迭代。

微软 AI 部门 CEO 苏莱曼警告:缺乏监管的 AI 或在数年内脱离人类掌控
AI在线 12 月 31 日消息,当地时间 12 月 29 日,微软 AI 部门 CEO 穆斯塔法・苏莱曼警告称,如果缺乏有效监管,AI 在未来数年内可能发展到人类难以掌控的程度。 苏莱曼在 BBC 第四电台《今日》节目中直言,对 AI 前景感到担忧“既正常也必要”。 “如果此刻你一点都不害怕,那说明你并没有真正意识到正在发生什么。

小米大模型 MiMo 公测延长,用户可免费体验至 2026 年!
在人工智能领域持续发力的小米,近日宣布自研大模型 MiMo-V2-Flash 的公测限免期将延长20天。 这一决策于12月31日正式公布,原定于2025年12月底结束的免费试用期,现将延至2026年1月20日下午2点。 此次延长不仅为用户提供了更多的体验时间,也显示出小米在大模型领域的信心与决心。

印度数据中心迅猛发展,但实施进展缓慢
印度的数据中心行业正经历快速增长,但在实际落实方面却面临诸多挑战。 卡纳塔克邦作为首批推出数据中心政策的地区之一,实施进程却显得相当缓慢。 尽管像孟买和钦奈等成熟市场仍占据印度数据中心容量的65% 至70%,但新兴地点显示出在下一个增长阶段的潜力和瓶颈。

从「工具」到「搭档」,AI4S 走过深水区 | 2025年终回顾
在这一轮波澜壮阔的人工智能浪潮中,我们常被算力、模型规模和颠覆式叙事所簇拥。 然而,真正值得记录的变化,往往发生在那些远离喧嚣的实验室里、发生在一行行代码与科学假设的碰撞中:AI 是如何从一种“使能技术”,演变为改变人类推进科研的基本范式的? 2025年,AI4Science(AI4S)不再仅仅是论文中的愿景。

超DeepEP两倍!无问芯穹FUSCO以「空中变阵」突破MoE通信瓶颈,专为Agent爆发设计
随着 ChatGPT、Gemini、DeepSeek-V3、Kimi-K2 等主流大模型纷纷采用混合专家架构(Mixture-of-Experts, MoE)及专家并行策略(Expert Parallelism, EP),MoE 技术已在产业应用中逐渐成为主流。 与此同时,以代码智能体、Cursor 类对话式 IDE 为代表的新型应用,一方面显著推高了用户请求规模,另一方面大幅拉长了单次推理的上下文长度,两者均呈现出一个数量级以上的增长。 在 MoE 架构下,这种变化不仅线性放大了计算开销,还显著增加了跨专家的通信与调度成本,使得整体系统压力接近一个数量级提升,并在规模化服务场景中进一步被放大。

「视频世界模型」新突破:AI连续生成5分钟,画面也不崩
当 Sora 让世界看到了 AI 生成视频的惊艳效果,一个更深层的问题浮出水面:如何让生成的视频不只是「看起来像」,而是真正理解并遵循物理世界的规律? 这正是「视频世界模型」(Video World Model)要解决的核心挑战。 当生成时长从几秒扩展到几分钟,模型不仅要画面逼真,更要在长时间尺度上保持结构、行为与物理规律的一致性。

AI 人像以假乱真,阿里通义 Qwen-Image-2512 模型开源发布
AI在线 12 月 31 日消息,阿里通义大模型今日开源发布 Qwen-Image-2512,聚焦于三大核心能力的飞跃式提升:更真实的人物质感、更细腻的自然纹理、更复杂的文字渲染,让生成的图像无限接近真实世界。 更真实的人物质感:告别塑料脸、模糊五官。 2512 能精准刻画皮肤纹理、发丝走向、表情神态,还能理解“微微前倾”这类语义细节。

源 Yuan 3.0 Flash 多模态基础大模型开源发布:40B 参数规模,单次推理仅激活约 3.7B
AI在线 12 月 31 日消息,浪潮旗下 YuanLab.ai 团队 12 月 30 日开源发布源 Yuan 3.0 Flash 多模态基础大模型。 Yuan 3.0 Flash 是一款 40B 参数规模的多模态基础大模型,采用稀疏混合专家(MoE)架构,单次推理仅激活约 3.7B 参数。 Yuan 3.0 Flash 提出和采用了强化学习训练方法(RAPO),通过反思抑制奖励机制(RIRM),从训练层面引导模型减少无效反思,在提升推理准确性的同时,大幅压缩了推理过程的 token 消耗,降低算力成本。
月之暗面斩获5亿美元C轮融资:手握百亿现金不急IPO,剑指AGI世界巅峰
国内大模型领军企业月之暗面(Moonshot AI)近日再次震撼行业。 创始人兼CEO杨植麟在内部信中透露,公司已顺利完成5亿美元的 C 轮融资。 得益于持续的融资助力,目前月之暗面账面现金储备已突破100亿元人民币。

苏州乐享发布具身智能品牌“元点智能”,全尺寸机器人原型首度亮相
今日,苏州乐享智能科技有限公司(以下简称“乐享科技”)正式发布全新具身智能品牌**“元点智能(Zeroth)”。 伴随品牌TVC的发布,其首个全尺寸大人形机器人原型**也揭开了神秘面纱,标志着公司正式进入通用机器人研发的新阶段。 多元矩阵:从户外探索到家庭陪伴随着全尺寸机器人的加入,元点智能已初步构建起覆盖全场景的产品矩阵:户外领域(W1): 履带式机器人,适配复杂地形。

MiniMax重磅推出M2.1编程模型,AI开发新纪元即将开启!
近日,MiniMax 正式宣布开源其全新 M2.1编程模型,标志着其在人工智能领域的重要进展。 这一模型现已同步上线于 Hugging Face、ModelScope 以及 GitHub 等多个平台,方便开发者们快速接入与使用。 M2.1的发布不仅是对开发者的一个重大利好,它还获得了 vLLM 的 “Day-0” 支持,这意味着开发者能够在模型发布的第一时间就享受到高效的推理性能。

京东副总裁郑宇:未来管理智慧城市,会像玩游戏一样简单丨GAIR 2025
12月12日,第八届GAIR全球人工智能与机器人大会在深圳正式启幕。 作为观测AI技术演进与生态变迁的重要窗口,GAIR大会自2016年创办以来以来,始终与全球AI发展的脉搏同频共振,见证了技术浪潮从实验室涌向产业深海。 2025年,是大模型从“技术破壁”迈向“价值深耕”的关键节点,值此之际GAIR携手智者触摸AI最前沿脉动,共同洞见产业深层逻辑。

打造“真机数据引擎”,睿尔曼智能摘得“2025年度中国商业创新金鼎典范企业”
近日,由中国商报社联合中国商界杂志社、中国商人杂志社、中国收藏杂志社、中国烹饪杂志社、中国经贸杂志社共同举办的第十二届中国商业创新大会暨推动中国商业进程四十年活动在北京召开。 大会以“此刻即未来:创新领航商业新征途”为主题,汇集来自政府、行业协会、企业、学界等各领域的领导、专家及代表,深入剖析商业创新的前沿趋势与策略,共同探索商业创新的无限可能。 睿尔曼智能受邀参会,并凭借 “云领计划” 的突破性创新实践,成功摘得“2025年度中国商业创新金鼎典范企业”荣誉,再度夯实行业创新引领地位。

之江实验室薛贵荣:当AI开始做科研,我看到了大语言模型的天花板丨GAIR 2025
12月12日,第八届GAIR全球人工智能与机器人大会在深圳正式启幕。 作为观测AI技术演进与生态变迁的重要窗口,GAIR大会自2016年创办以来以来,始终与全球AI发展的脉搏同频共振,见证了技术浪潮从实验室涌向产业深海。 2025年,是大模型从“技术破壁”迈向“价值深耕”的关键节点,值此之际GAIR如期而至,携手智者触摸AI最前沿脉动,洞见产业深层逻辑。
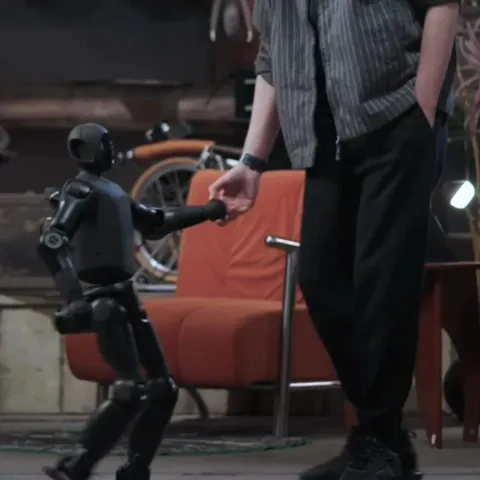
刚刚,稚晖君发布的人形机器人Q1,小到能塞进书包
这就是 2025 科技界最后一个重磅产品? 12 月 31 日下午,稚晖君(彭志辉)的机器人公司智元机器人正式发布了全球首款、全身力控的小尺寸人形机器人 Q1。 17 年前,乔布斯把笔记本电脑塞进了信封;17 年后,稚晖君把完整的人形机器人塞进了书包。

苏州:推广人工智能应用场景,对获国家支持的示范项目最高奖励 1000 万元
AI在线 12 月 31 日消息,12 月 30 日,苏州市人民政府发布《关于实施“成林计划”构建科技企业全生命周期扶持体系的若干措施》。 AI在线获悉,总体要求方面,到 2028 年新增 3 万个科创项目,拥有科技型企业超 10 万家;获评国家科技型中小企业 3 万家、国家高新技术企业 2.2 万家、国家专精特新“小巨人”企业 1200 家;入库“瞪羚”企业 4000 家、“独角兽培育”企业 800 家、科技领军培育企业 150 家;科创板上市企业 70 家。 《若干措施》提出,加快场景资源全域开放。
7B扩散语言模型单样例1000+ tokens/s!上交大联合华为推出LoPA
视频 1:单样例推理速度对比:SGLang 部署的 Qwen3-8B (NVIDIA) vs. LoPA-Dist 部署 (NVIDIA & Ascend)(注:NVIDIA 平台相同,配置对齐)在大语言模型(LLMs)领域,扩散大语言模型(dLLMs)因其并行预测特性,理论上具备超越传统自回归(AR)模型的推理速度潜力。 然而在实践中,受限于现有的解码策略,dLLMs 的单步生成往往局限于 1-3 个 Token,难以真正释放其并行潜力。