理论

破解MoE模型“规模越大,效率越低”困境!中科院自动化所提出新框架
大模型参数量飙升至千亿、万亿级,却陷入“规模越大,效率越低” 困境? 中科院自动化所新研究给出破局方案——首次让MoE专家告别“静态孤立”,开启动态“组队学习”。 具体而言,MoE本是大语言模型(LLM)实现参数量扩张且计算成本仅呈线性增长的核心路径,却长期受困于负载失衡、参数冗余、通信开销的“三难困境”,成为大模型落地部署的主要瓶颈。

西湖大学打造了一个AI科学家,突破人类SOTA,还能自己发论文
西湖大学用AI科学家,两周完成了人类三年的科研量。 这个科学家,是一个名叫DeepScientist的AI系统,自己捣鼓出了5000多个科学想法,动手验证了其中1100个,最后在三个前沿AI任务上,把人类科学家辛辛苦苦创造的SOTA纪录给刷新了。 西湖大学文本智能实验室(WestlakeNLP)发了篇论文,把这个能搞自主探索的AI科学家介绍给了全世界。

Anthropic发布的AI Agent设计哲学与经典设计模式
最近在学习AI Agent的设计模式时,发现了Anthropic发布的一篇好文《Building Effective agents》,仔细学习了下,值得跟大家分享。 在AI代理开发领域,Anthropic最新发布的研究报告为行业指明了方向。 经过与数十个跨行业团队的深度合作,Anthropic发现了一个令人意外的真相:最成功的LLM代理实现都采用简单、可组合的模式,而非复杂的框架。

Nature点赞!哈佛、MIT全新开源框架ToolUniverse实现「可编程的科学协作」
作者 | 论文团队编辑 | ScienceAI科学史的每一次飞跃,往往伴随着工具的革新。 随着近期大模型和智能体的飞速发展,这条路径正在通向一种全新的阶段:“AI 科学家”。 在 AI 赋能科研的前沿,我们正见证一个重要的里程碑:从证明 AI 智能体 “能否” 解决特定科学问题,转向思考如何让它 “高效、可靠、规模化” 地参与整个研究过程。

化学反应的「全景地图」来了,机器人帮科学家导航高维实验空间
编辑丨&不知道诸位读者在做实验的时候是否经历过一些玄学——明明步骤都是一样的,但就是因为某些奇异的问题,导致实验无法顺利进行下去。 人类化学家只能探索这些流形的一个有限子集,对反应超空间的理解仍然是零碎的 。 产率分布是平滑还是波状?

VaseVQA:古希腊陶器多模态智能体与基准测试平台
我们构建了VaseVQA,一个专注于古希腊陶器的大规模视觉问答数据集。 在该数据集上对多模态大语言模型(MLLMs)进行fine-tuning,我们采用SFT-then-RL的训练范式,并提出“诊断式”奖励机制,将SFT评估结果转为监督信号,以弥补MLLMs在薄弱任务类型上的推理能力缺陷。 ,文化遗产领域仍然缺乏专门的数据集。

听说,大家都在梭后训练?最佳指南来了
LLM 后训练最佳入门介绍。 在大模型时代,Scaling Law 一度是 AI 领域公认的准则:只要堆更多数据、参数、算力,模型能力就会持续增长。 GPT-3、PaLM 等的成功,几乎都是这种策略的胜利。

谷歌大神出手,免费发布《智能体设计模式》,AI Agent开发的终极秘籍
当前,AI 领域最火热的浪潮无疑是 AI Agent(智能体)。 从科技巨头到创业公司,无数开发者正投身于构建能够自主理解、规划和执行复杂任务的智能系统。 然而,在这股「淘金热」的背后,开发者们也面临着巨大的挑战:如何系统性地设计智能体的行为?

直击科学计算与设计痛点,跨学科推理统一基座模型SciReasoner来了
作者 | 论文团队编辑 | ScienceAI面对多模态、跨尺度、强约束的科研问题,通用 LLM 正从「工具」升级为「合作者」。 来自上海人工智能实验室等机构的研究团队提出了一款为科学数据「读 — 思 — 设」而生的统一科学基座模型:以更完整的科学数据基座、更系统的训练日程与更可验证的推理机制,直击科学计算与设计痛点。 论文:::::覆盖更广:统一 I/O 与「任务分组奖励」让单一骨干跨化学 / 生命 / 材料等多领域;可验证性更强:从数据标注到思维链再到 RL 奖励全面「科学化」,强调度量统一与工具可复核;工程更到位:明确的数据配比、训练日程与算力规模,保证性能与可复现性。

清华、NVIDIA、斯坦福提出DiffusionNFT:基于前向过程的扩散强化学习新范式,训练效率提升25倍
清华大学朱军教授团队, NVIDIA Deep Imagination 研究组与斯坦福 Stefano Ermon 团队联合提出了一种全新的扩散模型强化学习(RL)范式 ——Diffusion Negative-aware FineTuning (DiffusionNFT)。 该方法首次突破现有 RL 对扩散模型的基本假设,直接在前向加噪过程(forward process)上进行优化,在彻底摆脱似然估计与特定采样器依赖的同时,显著提升了训练效率与生成质量。 文章共同一作郑凯文和陈华玉为清华大学计算机系博士生。

多个编码智能体同时使用会不会混乱?海外开发者热议
AI 编程工具的进步速度正在迅速加快。 如果各位读者从事涉及代码相关的工作,应该很能察觉到近两年 AI 编程能力的进化幅度,GPT-5 和 Gemini 2.5 等最新前沿大模型已经让开发者在实际任务中一定程度实现了自动化,近期发布的 Sonnet 4.5 又再次推动了这一进展。 再结合现在已经非常成熟 CLI、IDE 工具等的辅助,采用编码智能体进行开发工作已经成为了一种常态,甚至成为了一种新的生活方式。

Nature | 大幅加速多元电催化剂的科学发现,MIT等推出多模态人工智能-机器人平台CRESt
作者 | 论文团队编辑 | ScienceAI近日,美国麻省理工学院李巨团队在国际顶尖学术期刊《Nature》上发表了题为《A multimodal robotic platform for multi-element electrocatalyst discovery》的研究论文。 该工作展示了一种多模态机器人平台 CRESt(Copilot for Real-world Experimental Scientists),通过将多模态模型(融合文本知识、化学成分以及微观结构信息)驱动的材料设计与高通量自动化实验相结合,大幅提升催化剂的研发速度和质量。 论文地址:。

吴恩达执教的深度学习课程CS230秋季上新,新增GPT-5专题
「人工智能是新的电力。 」——吴恩达吴恩达 (Andrew Ng) 执教的斯坦福 CS230 深度学习旗舰课程已更新至 2025 秋季版,首讲视频现已公开! 课程采用翻转课堂模式,学生需提前观看 Coursera 上的 deeplearning.ai 专项课程视频(包括神经网络基础、超参数调优、结构化机器学习项目等模块),然后参加线下课程。

大规模分子电子密度数据集EDBench发布,AI驱动分子建模迈入「电子级」时代
作者 | 论文团队编辑 | ScienceAI在药物设计、新材料开发等领域,精确模拟分子行为至关重要。 传统的机器学习力场将分子视为由原子核和化学键构成的“骨架”,却忽略了真正决定分子性质的“灵魂”——电子。 电子密度,这一量子化学中的核心物理量,描述了电子在空间中的分布概率,从根本上决定了分子的能量、反应活性等所有性质。

首个多模态 AI 可用的临床试验预测数据集平台,香港科技大学(广州)陈晋泰、南京大学符天凡等团队发布TrialBench
作者 | 论文团队编辑 | ScienceAI「临床试验是新药从实验室走向患者的关键桥梁,但其失败率高、周期长、成本巨大。 我们希望借助人工智能重塑这条桥梁。 」在制药与医学研究的世界里,临床试验是一项极其核心但也极其困难的工作:跨越多个阶段,耗时往往超过十年,平均成本可能高达数十亿美元,且成功率通常不足 15%。
CUDA内核之神、全球最强GPU程序员?OpenAI的这位幕后大神是谁
在 AI 圈里,聚光灯总是追逐着那些履历光鲜的明星人物。 但一个伟大的团队,不仅有台前的明星,更有无数在幕后贡献关键力量的英雄。 之前我们介绍了 OpenAI 的两位波兰工程师,最近 OpenAI 又一位身处幕后的工程师成为了焦点。
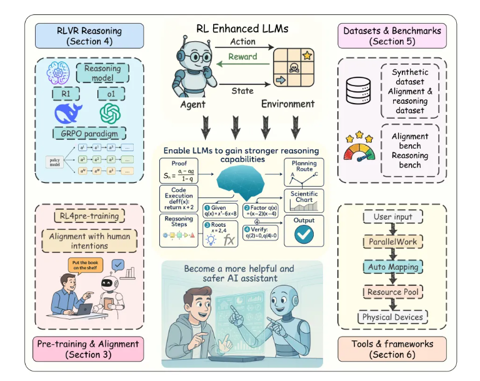
复旦、同济和港中文等重磅发布:强化学习在大语言模型全周期的全面综述
近年来,以强化学习为核心的训练方法显著提升了大语言模型(Large Language Models, LLMs)的推理能力与对齐性能,尤其在理解人类意图、遵循用户指令以及增强推理能力方面效果突出。 尽管现有综述对强化学习增强型 LLMs 进行了概述,但其涵盖范围较为有限,未能全面总结强化学习在 LLMs 全生命周期中的作用机制。 对此,来自复旦大学、同济大学、兰卡斯特大学以及香港中文大学 MM Lab 等顶尖科研机构的研究者们全面总结了大语言模型全生命周期的最新强化学习研究,完成题为 “Reinforcement Learning Meets Large Language Models: A Survey of Advancements and Applications Across the LLM Lifecycle” 的长文综述,系统性回顾了领域最新进展,深入探讨研究挑战并展望未来发展方向。

GPT-5解决量子版NP难题?半小时内给出有效方案
编辑丨%量子计算听起来就很烧脑了,但在理论世界里还有一群人,他们专门研究「量子证明」能做到什么程度。 这个领域叫量子复杂性理论,其中很出名的一个类是 QMA ——它是「量子版的NP问题」,可以理解成:有一个「量子证明」,由验证者用量子计算机来检查真假。 过去二十年,研究者不断尝试把验证错误率压得越来越低,就像玩游戏要刷「满暴击率」。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉