我们构建了VaseVQA,一个专注于古希腊陶器的大规模视觉问答数据集。在该数据集上对多模态大语言模型(MLLMs)进行fine-tuning,我们采用SFT-then-RL的训练范式,并提出“诊断式”奖励机制,将SFT评估结果转为监督信号,以弥补MLLMs在薄弱任务类型上的推理能力缺陷。

https://arxiv.org/abs/2509.17191
构建VaseVQA数据集
在多模态大语言模型广泛应用的背景下,文化遗产领域仍然缺乏专门的数据集。为弥补这一空缺,我们联合多所考古研究机构、博物馆和古希腊文化专家,共同构建了VaseVQA数据集。该数据集围绕古希腊陶器这一重要的文化载体,收集了31 773张多视图和单视图图像,并配套了93 544条视觉问答对。为了方便科研使用,我们按照训练集和测试集划分,并在每张图像上设计八种属性问题(材质、技法、形状、产地、年代、归属、装饰和整体描述),以全面覆盖从简单事实到复杂推理的需求。数据收集过程中,我们不仅采集完整陶器,还包含器物碎片及其埋藏环境的照片,确保视觉样本体现器物材料、工艺及区域差异;文本部分则来源于学术论文、考古报告和专家注释,涵盖了陶器的材质、纹饰、考古场景等,并经过翻译整理以适配视觉问答任务。
在标注方面,我们邀请考古学者和文化遗产专家对每张图像进行细致标注,包括陶器材料(如赤陶或釉陶)、纹样类型(人物、动物或抽象图案)、生产技术(手工成形还是轮制、烧成温度等)、放置环境(葬俗或仪式用途)以及修复痕迹等。借助这些专业注释,VaseVQA不仅能考查模型对视觉信息的理解,也能考查其对历史知识的掌握。例如,用户可以询问“陶器的技法是什么”或“该陶器的年代区间”,模型需要从图像细节和专家知识中获得答案,如下图所示。

此外,我们提供了类型特定的评测脚本,包括基于平均规范化编辑距离的准确率(用于材质、技法等事实性问题)、专门的年代评测指标和适用于描述性问题的BLEU@1指标,以保证评价既关注词汇精确度又关注语义一致性。
VaseVL训练范式与“诊断式”奖励设计
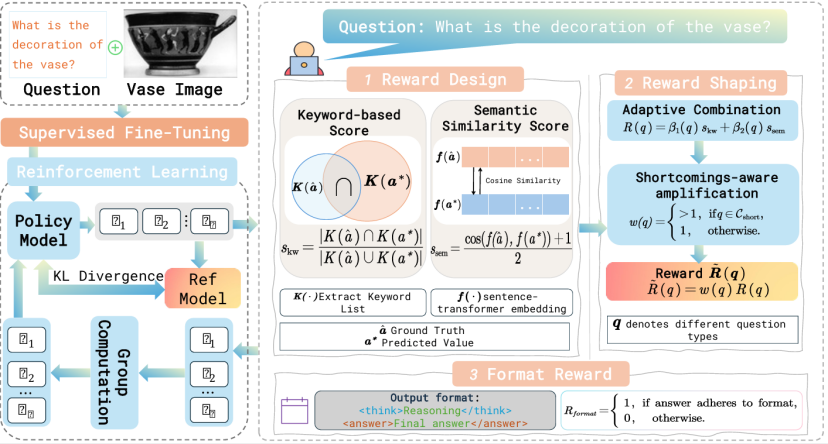
仅凭监督微调(SFT)难以让模型具备专家级推理能力。为此,我们提出VaseVL训练框架,通过“先监督再强化”的两阶段范式让模型既学习事实知识又提升推理能力。第一阶段,我们从一般的视觉语言模型(如Qwen‑2.5‑VL)出发,对其进行全参数的监督微调,使模型适应VaseVQA的数据分布和任务需求。然而,即便SFT显著提升了材质和技法等基础问题的准确率,模型在归属、装饰等复杂推理任务上的表现仍然欠佳。因此我们引入强化学习阶段,通过诊断模型的弱点来指引奖励设计,进一步提升推理能力。
具体而言,我们首先构建七个问题类型的分类体系:Fabric(材质)、Technique(技法)、Shape(形状)、Provenance(产地)、Attribution(归属)、Date(年代)和Decoration(装饰)。在监督微调后,我们评估每一类型的表现,从中找出模型的薄弱环节,形成短板集合C_short。随后,我们采用一种群相对策略优化(GRPO)的强化学习算法,优化政策πθ以最大化短板类型上的综合奖励,并利用KL散度约束控制生成的答案不偏离参考策略π_ref。为了确保更新稳定,我们在每个问题上采样多条回答,计算平均奖励作为基线,然后用A(k)=r(k)-\bar{r}定义相对优势,这样可以平衡不同类型奖励尺度的差异。
奖励函数的设计既考虑词汇重叠,也考虑语义相似。我们定义关键词重叠得分s_kw为模型答案与参考答案关键词集合的交并比,以衡量事实正确性;同时使用Sentence‑Transformer模型计算语义相似度s_sem,通过嵌入空间的余弦相似度评估回答的语义一致性。针对不同问题类型,我们设置不同的权重β_1(q)、β_2(q)来混合这两个得分:事实性问题更看重s_kw,描述性问题更看重s_sem。此外,对于属于C_short的薄弱类型,我们额外乘以放大因子w(q)>1,使模型在强化学习阶段更多关注这些难题。这种将评估转化为监督的策略,帮助模型在不偏离SFT知识的前提下,加强对复杂任务的推理能力。我们所提出的训练范式用于VaseVQA任务进行训练,如图所示。
实验
在实验中,我们以多种通用MLLM作为零样本基线,并与SFT和SFT‑then‑RL方法进行比较。由于文化遗产领域知识的专业性,零样本模型在我们数据集上表现较差,许多模型在归属和装饰任务上的得分接近0。我们对Qwen‑2.5‑VL进行监督微调后,模型在材质、技法等基础问题上达到接近满分的准确率(Fabric 99.96%,Technique 94.99%),但在归属(56.96%)和装饰(BLEU@1=2.57)等任务上依旧存在明显不足。
引入诊断式奖励的强化学习阶段后,VaseVL在薄弱任务上取得显著提升。与SFT相比,归属任务的准确率提高到60.83%,装饰描述的BLEU@1得分从2.57跃升至9.82。更重要的是,这些提升并未以牺牲事实问题的表现为代价——模型在材质和技法上的准确率仍维持在99%以上,说明我们的奖励机制有效地“激活”了模型的推理能力而不破坏其 factual recall。综合看,VaseVL在所有任务上的平均得分超过了75%,明显领先于零样本模型和仅采用SFT的模型。
为了公平评估不同问题类型,我们采用多指标评测。在材质、技法、形状、产地和归属等事实性问题上,使用基于平均规范化编辑距离的柔性准确率,该指标能够容忍OCR错误等字符差异;在年代问题上,通过解析文本中的年代并计算交集并用(IoU)、相对差距等综合得分,兼顾格式和数值准确性;在装饰描述问题上,采用BLEU@1评估关键字的覆盖情况,从而衡量模型是否捕捉到了核心纹饰元素。这套评测方案使我们能精准观察模型在不同任务上的优势和短板,为奖励设计提供依据。
贡献与展望
我们的研究主要贡献包括三个方面:一是发布了一个覆盖古希腊陶器的VQA数据集,包含31 773幅图像(其中11 693幅为单视图)和93 544个问答对,并提供了针对七类问题的评测脚本;二是提出了SFT‑then‑RL的训练范式,在强化学习阶段利用诊断式奖励结合GRPO算法,通过对模型的薄弱任务加权,实现评估结果向监督信号的转化;三是实验表明,我们的方法在样式分类和历史归属等任务上取得了新的状态‑of‑the‑art成绩,同时在组合推理方面显著优于仅使用SFT的基线。这些成果为文化遗产领域的多模态模型研究提供了可复用的资源和方法。
展望未来,我们计划扩展VaseVQA到更广泛的器物类别,如罗马陶器、青铜器等,以检验VaseVL方法在不同文化场景中的泛化能力。此外,我们正在探索加入外部知识库、利用多轮对话提升模型对背景知识的利用,以及开发结合多模态工具链的智能代理,使模型能够主动查询文献和数据库,为古代艺术研究提供更深入的洞见。我们期待VaseVQA和VaseVL能成为文化遗产领域多模态研究的基石,并促使更多学者投入这一跨学科的探索。


