工程

MIT最新发现:这十年,算法进步被高估了
在过去十年中,AI 的进步主要由两股紧密相关的力量推动:迅速增长的计算预算,以及算法创新。 相比之下,计算量的增长较容易衡量,但我们仍然缺乏对算法进步的清晰量化,究竟哪些变化带来了效率提升,这些提升的幅度有多大,以及它们在不同计算规模下是否依然成立。 2024 年,有研究通过分析数百个语言模型,他们估计在过去十年里,算法进步在所谓的有效计算量(effective compute)方面贡献了超过 4 个数量级的提升;而根据对历史 AI 文献的分析,计算规模本身增长了 7 个数量级。

成本仅0.3美元,耗时26分钟!CudaForge:颠覆性低成本CUDA优化框架
本文作者包括明尼苏达大学的张子健(共同第一作者),王嵘(共同第一作者),李世阳,罗越波,洪明毅,丁才文。 CUDA 代码的性能对于当今的模型训练与推理至关重要,然而手动编写优化 CUDA Kernel 需要很高的知识门槛和时间成本。 与此同时,近年来 LLM 在 Code 领域获得了诸多成功。

首个完整开源的生成式推荐框架MiniOneRec,轻量复现工业级OneRec!
中科大 LDS 实验室何向南、王翔团队与 Alpha Lab 张岸团队联合开源 MiniOneRec,推出生成式推荐首个完整的端到端开源框架,不仅在开源场景验证了生成式推荐 Scaling Law,还可轻量复现「OneRec」,为社区提供一站式的生成式推荐训练与研究平台。 近年来,在推荐系统领域,传统 “召回 排序” 级联式架构的收益正逐渐触顶,而 ChatGPT 等大语言模型则展现了强大的涌现能力和符合 Scaling Law 的巨大潜力 —— 这股变革性的力量使 “生成式推荐” 成为当下最热门的话题之一。 不同于判别式模型孤立地计算用户喜欢某件物品的概率,“生成式推荐” 能够利用层次化语义 ID 表示用户历史行为序列,并基于生成式模型结构直接生成用户下一批可能交互的物品列表。

解决特斯拉「监督稀疏」难题,DriveVLA-W0用世界模型放大自动驾驶Data Scaling Law
在自动驾驶领域,VLA 大模型正从学术前沿走向产业落地的 “深水区”。 近日,特斯拉(Tesla)在 ICCV 的分享中,就将其面临的核心挑战之一公之于众 ——“监督稀疏”。 这一问题直指当前 VLA 模型的 “七寸”:其输入是高维、稠密的视觉信息流,但其监督信号却往往是低维、稀疏的驾驶动作(如路径点)。

VinciCoder:多模态统一代码生成框架和视觉反馈强化学习,数据代码模型权重已开源
长期以来,多模态代码生成(Multimodal Code Generation)的训练严重依赖于特定任务的监督微调(SFT)。 尽管这种范式在 Chart-to-code 等单一任务上取得了显著成功 ,但其 “狭隘的训练范围” 从根本上限制了模型的泛化能力,阻碍了通用视觉代码智能(Generalized VIsioN Code Intelligence)的发展 。 同时,「SFT-only」的范式在确保代码可执行性和高视觉保真度方面存在显著瓶颈 。
WithAnyone重磅开源:这可能是你见过最自然的AI合照模型
和任何人,去任何地方! 复旦大学携手阶跃星辰打破 “复制粘贴” 魔咒,重磅推出全新 AI 合照生成模型 WithAnyone —— 只需上传照片,就能一键生成自然、真实、毫无违和感的 AI 合照! WithAnyone 是什么?
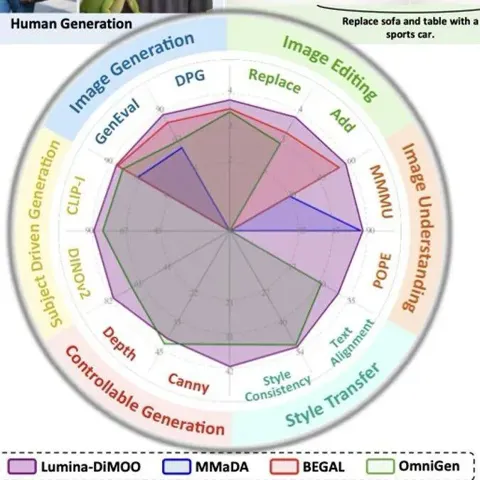
Lumina-DiMOO:多模态扩散语言模型重塑图像生成与理解
上海人工智能实验室推出了一款革新的多模态生成理解一体化的扩散语言模型 ——Lumina-DiMOO。 基于离散扩散建模(Discrete Diffusion Modeling),Lumina-DiMOO 打破了多模态任务之间的壁垒,在同一离散扩散框架下,完成从 文本→图像、图像→图像、图像→文本的全栈能力闭环。 论文标题:Lumina-DiMOO: An Omni Diffusion Large Language Model for Multi-Modal Generation and Understanding论文链接:arxiv.org/pdf/2510.06308GitHub 地址:Alpha-VLLM/Lumina-DiMOO 关键词:多模态生成与理解统一、扩散语言模型过去:自回归生成的瓶颈从 Chameleon 到 Lumina-mGPT,再到 Janus-Pro—— 主流 “多模态统一模型”,几乎都基于 自回归(AR)架构。

3D视觉被过度设计?字节Depth Anything 3来了,谢赛宁点赞
现在,只需要一个简单的、用深度光线表示训练的 Transformer 就行了。 这项研究证明了,如今大多数 3D 视觉研究都存在过度设计的问题。 本周五,AI 社区最热门的话题是一篇新论文,有关 3D 建模的。

NeurIPS 2025 Spotlight | NYU提出QSVD,仅数学压缩让模型更轻、更快、更稳
本工作由纽约大学 NYU SAI Lab 的硕士生王宇彤与博士生王海宇合作完成。 本文的通讯作者为张赛骞,他是纽约大学(New York University)计算机科学系助理教授、SAI Lab 负责人,其研究方向涵盖多模态大模型(Vision-Language Models)压缩与加速、低比特量化、高效推理以及可信智能系统。 在多模态智能浪潮中,视觉语言模型(Vision-Language Models, VLM)已成为连接视觉理解与语言生成的核心引擎。

NeurIPS 2025|当AI学会"炒股":用千个虚拟投资者重现金融市场涌现现象
市场不是机器,而是人群;不是公式,而是故事。 TwinMarket让AI学会讲述这些故事。 1994年,美国圣塔菲研究所(Santa Fe Institute)推出了一个野心勃勃的项目:人工股票市场(Artificial Stock Market)。

EMNLP2025 | 通研院揭秘MoE可解释性,提升Context忠实性!
论文发表于EMNLP2025主会,核心作者为北京通用人工智能研究院(通研院)研究工程师白骏、刘洋,以及通计划武汉大学联培一年级博士生童铭颢,通讯作者为通研院语言交互实验室研究员贾子夏,实验室主任郑子隆。 MoE 遇上机制可解释性:鲜为人知的探索之旅在大模型研究领域,做混合专家模型(MoE)的团队很多,但专注机制可解释性(Mechanistic Interpretability)的却寥寥无几 —— 而将二者深度结合,从底层机制理解复杂推理过程的工作,更是凤毛麟角。 这条路为何少有人走?

⽆需任何监督信号!自博弈机制让深度搜索Agent实现自我进化
近期,搜索型 Agent 的热度持续攀升⸺从 OpenAI 的 Deep Research 到各类学术探索,「多轮检索 ⼯具调⽤ 深度推理」的新范式正在深刻改变 AI 获取和整合信息的⽅式。 但如何让这些 Agent 能⼒持续提升,达到接近⼈类的表现⽔平,仍然是⼀个核⼼挑战。 ⽬前主流的训练⽅法是可验证奖励强化学习(RLVR):给定任务题⽬和标准答案,⽤最终预测结果的正确性作为奖励信号来训练 Agent。

AAAI 2026|教会视频扩散模型「理解科学现象」:从初始帧生成整个物理演化
近年来,Stable Diffusion、CogVideoX 等视频生成模型在自然场景中表现惊艳,但面对科学现象 —— 如流体模拟或气象过程 —— 却常常 “乱画”:如下视频所示,生成的流体很容易产生违背物理直觉的现象,比如气旋逆向旋转或整体平移等等。 上述问题的根源在于,这些模型缺乏对科学规律的内在理解。 它们学习到的只是像素分布,而非支配这些分布的动力学方程。

SIGGRAPH Asia 2025 | 让3D场景生成像「写代码」一样灵活可控
随着生成式 AI 的快速发展,从文本生成图像、视频,到构建完整的三维世界,AI “创造空间” 的能力正以前所未有的速度突破边界。 然而,现有 3D 场景生成方法仍存在明显局限:模型往往直接输出每个物体的几何参数(位置、大小、方向等),结果容易出现漂浮、重叠、穿模等问题;场景结构缺乏逻辑一致性,难以编辑或复用,更无法像程序那样精确控制空间关系与生成逻辑。 想象这样一个画面:你输入一句话 ——“在黄昏的码头上,一位渔夫坐在木椅上,旁边是一盏摇曳的灯。

NeurIPS Spotlight|GHAP:把3DGS“剪枝”变成“重建更小的高斯世界”
本文第一作者王涛来自中国人民大学,共同第一作者李梦雨 () 来自清华大学。 通讯作者为中国人民大学张琼助理教授 () 与孟澄助理教授 ()。 其他作者还包括来自中国人民大学的曾舸舵。

LeCun在Meta的最后论文?还是共同一作,LeJEPA:JEPAs理论拼图补完
这可能是 LeCun 在 Meta 发表的最后几篇论文之一。 这次,LeCun 为 JEPA 架构补上了关键的理论拼图。 学习世界及其动态的可操控表征是人工智能的核心。

FDA对偶锚点:模型知识迁移的新视角——从参数空间到输入空间
该项工作的作者分别是来自香港中文大学的博士生施柯煊,来自西湖大学的助理教授温研东,来自香港中文大学的计算机系助理教授刘威杨。 当前,基于通用基础模型进行任务特定微调已成为主流范式。 这种范式虽然能够在各个特定任务上获得高性能的专家模型,但也带来新的挑战:如何将这些特定微调得到的专家模型的能力有效整合到单一模型中并且无需访问原始训练数据,实现多任务协通,同时最小化性能损失?

RAE+VAE? 预训练表征助力扩散模型Tokenizer,加速像素压缩到语义提取
近期,RAE(Diffusion Transformers with Representation Autoencoders)提出以「 冻结的预训练视觉表征」直接作为潜空间,以显著提升扩散模型的生成性能。 无独有偶,同期西安交通大学与微软亚洲研究院提出了「VFM-VAE」。 二者均基于冻结的预训练视觉模型构建语义潜空间,而 VFM-VAE 在结构上可视为 RAE 与 VAE 的结合:结合 VAE 的概率建模机制,将高维预训练模型特征压缩为低维潜空间表示,系统性地研究了在压缩条件下预训练视觉表征对 LDM 系统表征结构与生成性能的影响。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉