工程

让扩散模型「可解释」不再降质,开启图片编辑新思路
过去三年,扩散模型席卷图像生成领域。 以 DiT (Diffusion Transformer) 为代表的新一代架构不断刷新图像质量的极限,让模型愈发接近真实世界的视觉规律。 然而,与 LLM 可解释性研究的蓬勃发展相对,扩散模型内部的语义结构、时间规律以及因果路径仍然像被深深封住的「黑箱」。

AAAI 2026|视频大语言模型到底可不可信?23款主流模型全面测评来了
近年来,视频大语言模型在理解动态视觉信息方面展现出强大能力,成为处理真实世界多模态数据的重要基础模型。 然而,它们在真实性、安全性、公平性、鲁棒性和隐私保护等方面仍面临严峻挑战。 为此,合肥工业大学研究团队携手清华大学研究团队推出了首个面向视频大语言模型的综合可信度评测基准 Trust-videoLLMs。

Veo何止生成视频:DeepMind正在用它模拟整个机器人世界
随着通用型(Generalist)机器人策略的发展,机器人能够通过自然语言指令在多种环境中完成各类任务,但这也带来了显著的挑战。 一方面,真实世界评估成本极高,需要系统性地覆盖常规场景、极端情况、分布外(OOD)环境以及各类安全风险,通常需要进行成百上千次真实硬件实验,不仅耗时、昂贵,还可能存在操作风险。 另一方面,安全性评估尤为棘手,许多潜在的不安全行为(例如误夹人手、损坏设备或引发环境危险)本身就不适合在真实环境中反复测试,使得传统的硬件评估方法在安全场景下往往难以实施。

NeurIPS 2025|指哪打哪,可控对抗样本生成器来了!
近日,在全球人工智能领域最具影响力的顶级学术会议 NeurIPS(神经信息处理系统大会)上, 清华大学和蚂蚁数科联合提出了一种名为 Dual-Flow 的新型对抗攻击生成框架。 简单来说,Dual-Flow 是一个能够从海量图像数据中学习 “通用扰动规律” 的系统,它不依赖目标模型结构、不需要梯度,却能对多种模型、多种类别发起黑盒攻击。 其核心思想是通过 “前向扰动建模 — 条件反向优化” 的双流结构,实现对抗样本的高可迁移性与高成功率,同时保持极低的视觉差异。

AAAI 2026 | 革新电影配音工业流程:AI首次学会「导演-演员」配音协作模式
你是否也觉得,AI 配音的语调总是差了那么点 “人情味”? 它能把台词念得字正腔圆,口型分秒不差,但角色的喜怒哀乐却总是难以触及灵魂深处。 问题出在哪里?

RL是「点金石」还是「挖掘机」?CMU 用可控实验给出答案
近期,强化学习(RL)技术在提升语言模型的推理能力方面取得了显著成效。 然而,后训练究竟是真正扩展了模型的推理能力,还是仅仅挖掘了预训练中已有的潜力? 目前尚不明确。

1100多个模型殊途同归,指向一个「通用子空间」,柏拉图又赢一回?
模型架构的重要性可能远超我们之前的认知。 最近,约翰斯・霍普金斯大学的一项研究发现:1100 多个不同的神经网络,即使在完全不同的数据集上训练、用不同的初始化和超参数,最终学到的权重都会收敛到一个共享的低维子空间。 这似乎是说明:存在一个「先验的」数学结构,所有神经网络都在逼近它。
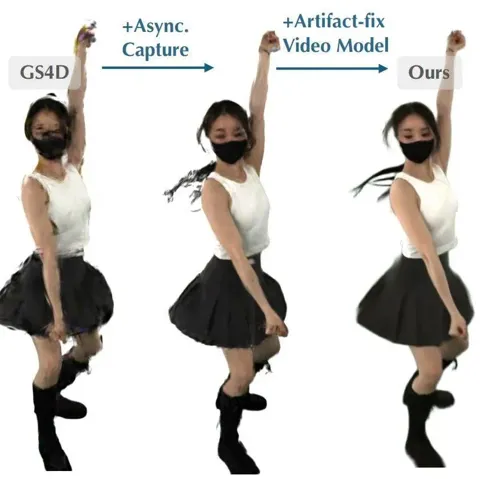
SIGGRAPH Asia 2025|30FPS普通相机恢复200FPS细节,4D重建方案来了
本文第一作者陈羽田,香港中文大学 MMLab 博士二年级在读,研究方向为三维重建与生成,导师为薛天帆教授。 个人主页: 0.01 秒的惊艳弧度,当 VR 玩家想伸手抓住对手 “空中定格” 的剑锋,当 TikTok 爆款视频里一滴牛奶皇冠般的溅落要被 360° 无死角重放 —— 如何用普通的摄像机,把瞬间即逝的高速世界 “冻结” 成可供反复拆解、传送与交互的数字化 4D 时空,成为 3D 视觉领域的一个难题。 然而,受限于硬件成本与数据传输带宽,目前绝大多数 4D 采集阵列的最高帧率仅约 30 FPS;相比之下,传统高速摄影通常需要 120 FPS 乃至更高。

8B模型任务击败GPT-5?阶跃星辰开源Deep Think新框架,小模型解锁百万Token测试时计算
8B 模型在数学竞赛任务上超越 GPT-5! 阶跃星辰正式推出并行协同推理(PaCoRe, Parallel Coordinated Reasoning),这是一个全新的训练和推理框架,让大模型的能力不再受限于线性思维链的上下文窗口大小(Context Window)和处理速度,而是基于大规模并行协同的方式,让模型进行前所未有的广度和深度思考。 强大性能的 Gemini Deep Think 模式仅隐约透露其采用“并行思考”扩展测试时计算的思路;而 PaCoRe 以卓越的表现验证了大规模扩展测试时计算的有效性,并完整开源模型,训练数据,推理管线从而加速该领域的研究与创新。

NeurIPS 2025 | 告别全量扫描!浙大提出COIDO:破解多模态数据选择「高耗」难题
本文第一作者是二年级博士生闫熠辰,主要研究方向是多模态大模型的数据质量管理;通讯作者是李环研究员,主要研究方向包括人工智能数据准备、大模型高效推理与部署、时空大数据与模型轻量化等。 01 省流版:一张图看懂 COIDO在深入技术细节之前,我们先用一张漫画来直观理解 COIDO (Coupled Importance-Diversity Optimization) 解决的核心问题与方案:正如钟离在漫画中所言,面对海量视觉指令数据的选择任务,传统方法需要遍历全部数据才能进行筛选造成大量「磨损」(高昂计算成本)。 同时在面对数据重要性和多样性问题时,传统方法往往顾此失彼。

谢赛宁REPA得到大幅改进,只需不到4行代码
邹忌曾经有一个问题:吾与徐公孰美? 而对于 REPA,也有一个类似的问题:全局信息与空间结构,哪个对表征对齐更重要? 表征对齐(REPA)可通过将强大的预训练视觉编码器的表征蒸馏为中间扩散特征,来指导生成式训练。

AAAI 2026 Oral | 拒绝「一刀切」!AdaMCoT:让大模型学会「看题下菜碟」,动态选择最佳思考语言
多语言大模型(MLLM)在面对多语言任务时,往往面临一个选择难题:是用原来的语言直接回答,还是翻译成高资源语言去推理? 实际上,不同的语言在模型内部承载着不同的「特长」。 比如英语可能逻辑性强,适合科学推理;而中文或印尼语在处理特定文化背景或押韵任务时,可能比英语更具优势。

苹果光速撤回RLAX论文:用了谷歌TPU和阿里Qwen,作者中还有庞若鸣
昨天,苹果一篇新论文在 arXiv 上公开然后又匆匆撤稿。 不过观看其提交历史,可以看到该论文在 12 月 6 日(UTC)就已被提交到 arXiv,到 11 号已经过去了 5 天,公开上线之后却又被光速撤稿,这不由得地让人好奇究竟发生了什么。 不过好在该论文有一个 v1 版本已经被互联网记录,所以我们也能打开这篇论文一探究竟。

告别「盲目自信」,CCD:扩散语言模型推理新SOTA
扩散语言模型(Diffusion Language Models)以其独特的 “全局规划” 与并行解码能力广为人知,成为 LLM 领域的全新范式之一。 然而在 Any-order 解码模式下,其通常面临推理速度较慢且生成逻辑不连贯等问题。 对此,华为小艺香港团队、香港城市大学及香港大学的研究人员们共同提出了一种全新的上下文一致性解码算法(Coherent Contextual Decoding, CCD),充分利用扩散过程中的上下文增广,从理论上纠正了传统 DLM 推理策略的 “短视性”,并进一步采用自适应解码方案在多种开源 DLMs 上同时实现了 3.48 倍的加速和 3.9% 的性能提升。

港大开源ViMax火了,实现AI自编自导自演
想象一下,只需要一句话描述,AI 就能为你拍出一部完整的短剧? 以后可能真的人人都能当导演了。 不用学复杂的拍摄技巧,不用买昂贵设备,甚至不用找演员。

NUS LV Lab新作|FeRA:基于「频域能量」动态路由,打破扩散模型微调的静态瓶颈
尹博:NUS 计算机工程硕士生、LV Lab 实习生,研究方向是生成式 AI,及参数高效率微调(PEFT)。 胡晓彬:NUS LV Lab Senior Research Fellow, 研究方向是生成式 AI,MLLM Agent 等。 在大模型时代,参数高效微调(PEFT) 已成为将 Stable Diffusion、Flux 等大规模扩散模型迁移至下游任务的标准范式。

谷歌发布智能体Scaling Law:180组实验打破传统炼金术
智能体(Agent),即基于语言模型且具备推理、规划和行动能力的系统,正在成为现实世界 AI 应用的主导范式。 尽管其已被广泛采用,但决定其性能的原则仍未被充分探索,导致从业者只能依赖启发式经验,而非有原理依托的设计选择。 现在,谷歌的一篇新论文填补了这一空白!

效率提升25%,灵巧操作数采困境被「臂-手共享自主框架」解决
实现通用机器人的类人灵巧操作能力,是机器人学领域长期以来的核心挑战之一。 近年来,视觉 - 语言 - 动作 (Vision-Language-Action,VLA) 模型在机器人技能学习方面展现出显著潜力,但其发展受制于一个根本性瓶颈:高质量操作数据的获取。 ByteDance Seed 团队最新的研究论文《End-to-End Dexterous Arm-Hand VLA Policies via Shared Autonomy》[1],针对这一关键问题提出了解决方案。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉