作者:fangzlong
随着模型的范式和工程方式发展,网络上涌现出了一大批模仿人类研究者对问题进行深入研究的智能体应用。本文将从 OpenAI 关于 DeepResearch 的指南开始,通过几个开源框架的架构解构与功能映射,揭示不同框架在研究自动化领域的差异。为各位使用者、开发者选择合适工具和框架提供系统化参考。

一、开源深度研究智能体框架
1. 开源整体对比
市面上还有很多其他通用智能体框架也可以实现深度研究功能(如 Auto-GPT, BabyAGI, AgentGPT, Microsoft/AutoGen,Camel-AI/OWL)。本文主要关注下面六个专门针对深度研究功能进行了架构优化及创新的框架,下面是简单对比:
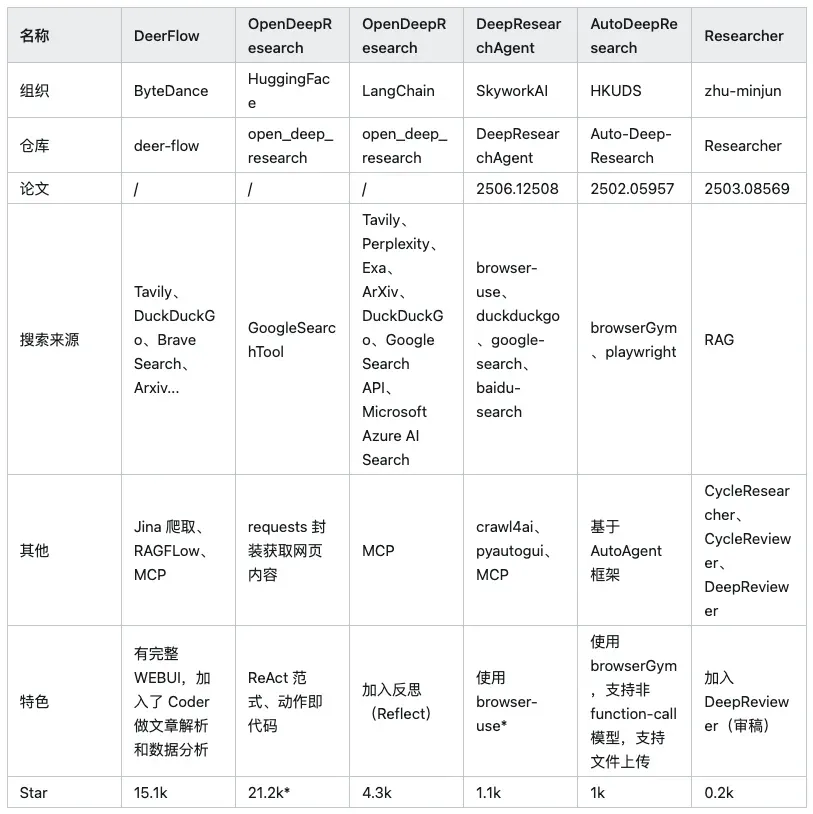
备注:HuggingFace/OpenDeepReasearch 非独立项目,所以这里写的 21.2k 是 SmolAgents 项目的总星数browser-use 是一个 AI 驱动浏览器的著名自动化框架(目前在 Github 上 Star 为 65.4k)。对比传统 curl/requests 获取网页内容,可以加载识别动态网页及上面的元素(比如一些使用 AJAX 加载的实时数据网站等)。本文主要关注框架方面,对包括 browser-use 等其他辅助工具不作过多研究,有兴趣的读者可以继续深入学习。
2. OpenAI 指南
OpenAI 文档提供了一个指导文档 Deep Research 来说明如何使用 API 构造自己的深度研究智能体,里面的架构基本是所有框架的雏形,所以我们先从这里开始。
核心架构:三步范式(Plan -> Execute -> Synthesize)

该指南的核心思想是,不要试图用一个巨大的提示词(Prompt)让模型一次性完成所有研究。相反,应该将复杂的研报任务分解成一个清晰、模块化的三步流程:
- 规划 (Plan): 让一个高级模型(如 GPT-4.1)将用户的主问题分解成一系列具体的、可独立研究的子问题。
- 执行 (Execute): 并行地对每个子问题进行研究,调用搜索 API 获取信息,并让模型对单个信息源进行总结。
- 合成 (Synthesize): 将所有子问题的答案汇总起来,交给一个高级模型,让它撰写成一篇连贯、完整的最终报告。
3. 优秀实践
基于这个核心架构,以下是具体的最佳实践和注意事项:
(1) 为正确的任务选择正确的模型(核心成本与性能优化策略)
这是文章中最重要的建议之一。不同任务对模型能力的要求不同,混用模型可以极大地优化成本和速度。
优秀实践:
- 问题澄清和改写: 使用小一些、更快的模型。这两步只是启动研究过程,如果输入的 prompt 足够详细,这两步甚至可以跳过。
- 规划 (Plan) 和 合成 (Synthesize) 阶段: 使用能力最强的模型,如 gpt-4.1 或 gpt-4o。因为这两个步骤需要强大的推理、逻辑组织和长文本生成能力,它们的质量直接决定了最终报告的上限。
- 执行 (Execute) 阶段: 对搜索到的单个网页或文档进行初步总结时,可以使用更便宜、更快的模型,如 gpt-3.5-turbo。因为这个任务相对简单(总结一篇具体文章),不需要顶级的推理能力。
注意事项:
- 成本监控:一个深度研究请求可能会触发数十次 API 调用,必须密切关注成本。采用上述分级模型策略是控制成本的关键。
(2) 并行处理以最大化效率
研究过程中的多个子问题通常是相互独立的,等待一个完成后再开始下一个会非常耗时。
优秀实践:
- 在“执行”阶段,一旦“规划”步骤生成了所有子问题列表,就应该使用异步编程(如 Python 的 asyncio)来并行发起对每个子问题的研究请求。这样可以将原本需要数分钟的串行过程缩短到一分钟以内。
注意事项:
- API 速率限制 (Rate Limits): 并行调用会瞬间产生大量请求,请确保您的 OpenAI API 账户有足够的速率限制额度(TPM - Tokens Per Minute),否则请求可能会失败。
(3) 使用函数调用(Function Calling)或 JSON 模式获取结构化输出
直接让模型输出文本并用代码去解析,既不稳定也容易出错。为了保证工作流的稳定可靠,应始终让模型返回结构化的数据。
优秀实践:
- 规划阶段: 指示模型使用“函数调用”或“JSON 模式”,输出一个包含所有子问题字符串的 JSON 列表。这样您的代码就可以直接、准确地解析出需要执行的任务清单。
- 执行阶段: 同样,在总结单个页面时,也可以要求模型以固定的 JSON 格式返回结果,例如 {"summary": "...", "key_points": [...]}。
注意事项:
- 确保您的提示词中清晰地描述了所需的 JSON 结构或函数签名。
(4) 外部工具的必要性(LLM 不是万能的)
大型语言模型本身没有实时联网能力,其知识也非最新。因此,必须集成外部工具。
优秀实践:
- 集成一个或多个高质量的搜索 API(如 Google Search API, Brave Search API, Serper 等)来获取实时、广泛的信息。
- 在提示词中明确告知模型它可以使用这些工具,并通过函数调用等方式将工具的输出结果返回给模型。
(5) 精心设计提示词(Prompt Engineering)
每个阶段的提示词都至关重要。
优秀实践:
- 规划提示词: 应明确告知模型其角色是一个“世界级的首席研究员”,任务是“将一个复杂问题分解为一组可以独立研究的、详尽的子问题”。
- 执行提示词: 应指示模型扮演“专家分析师”,任务是“根据提供的原始文本,回答一个具体的问题,并进行简洁总结”。
- 合成提示词: 这是最终决定报告质量的关键。应包含所有子问题的答案,并给出非常明确的指令,例如:“你是一位顶级行业分析师,请整合以下所有研究资料,撰写一份全面、客观、结构清晰的深度研究报告。报告应包含引言、正文和结论,并保持专业的语调。”
输入样例:
①问题
复制(注:上方为指南 prompt 原文,下方为对应翻译参考)
② 问题澄清
复制③ User Prompt 改写
复制(6) 加入人工审核环节 (Human-in-the-Loop)
对于非常严肃或重要的研究任务,完全自动化的流程可能存在风险。
优秀实践:
- 可以在规划阶段之后加入一个人工审核步骤。让用户(或您自己)审查和修改模型生成的子问题列表,确保研究方向正确无误后,再启动昂贵的“执行”阶段。这可以有效避免后续步骤的“垃圾进,垃圾出”。
二、开源架构分析
下面依次介绍每个框架的架构和特点,并给出最佳实践和注意事项。
1. ByteDance/DeerFlow
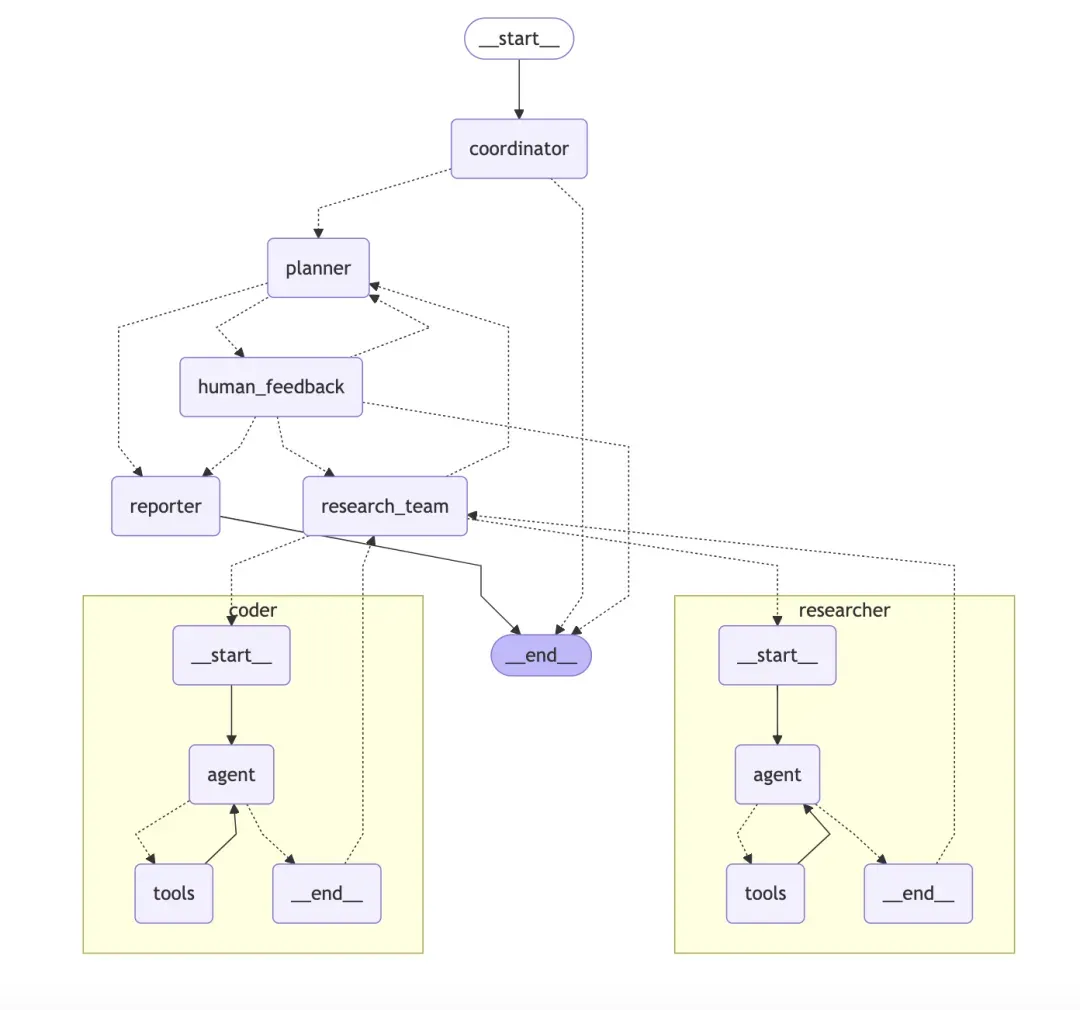
DeerFlow 项目的架构是一个模块化的多智能体(multi-agent)系统,其核心是围绕一个分层的、协作的智能体团队来自动化完成复杂的研究任务。其主要架构组件和特点如下:
(1) 核心架构:分层多智能体系统
DeerFlow 采用了多个拥有不同角色的智能体(Agent)协同工作的模式,这些智能体各司其职,共同完成一个研究项目。该系统主要包含以下几个核心角色:
- 协调器 (Coordinator): 这是整个工作流的入口和管理者。它接收用户的初始请求,启动研究流程,并在需要时将任务委派给规划器。协调器也作为用户和系统之间的主要交互界面。
- 规划器 (Planner): 扮演策略师的角色。它负责将用户提出的复杂研究问题分解成一系列结构化的、可执行的步骤。规划器会评估当前是否需要收集更多信息,还是可以开始生成报告,从而管理整个研究的流程。
- 研究团队 (Research Team): 这是一组专门执行具体任务的智能体,如同一个“研究小组”。主要包括: 研究员 (Researcher): 负责执行网络搜索、调用API、抓取网页内容等,以收集所需的信息和数据。 程序员 (Coder): 负责执行 Python 代码,用于数据分析、代码片段测试等技术性任务。
- 报告员 (Reporter): 这是研究流程的最后一环。它负责将研究团队收集到的所有信息和发现进行汇总、整合和结构化,最终生成多种格式的综合研究报告,例如 Notion 风格的文档、播客甚至是 PowerPoint 演示文稿。
(2) 技术基础和特点
- 构建于开源项目之上: DeerFlow 的底层利用了 LangChain 和 LangGraph 等流行的开源项目。特别是 LangGraph,它被用来构建和管理不同智能体之间的状态和通信,使得整个工作流程像一个有向图一样清晰和可追溯。
- 模块化和可扩展性: 该架构是高度模块化的,支持“即插即用”的工具集。例如,它集成了 Tavily、Brave Search、DuckDuckGo 等多种搜索引擎,以及用于网页抓取的 Jina 等工具,并且可以轻松扩展以支持自定义的 API 或模型。
- 人机协作 (Human-in-the-Loop): DeerFlow 并非一个完全自主的“黑箱”系统,而是强调人与 AI 的协作。用户可以审查和修改AI生成的研究计划,在执行过程中调整参数,并在最后对报告进行精炼。这种混合模式在用户测试中被证明可以显著减少研究时间,同时保持内容的高准确性。
- 微服务架构: 有资料提到,DeerFlow 采用了微服务(microservices-based)架构,包含了研究引擎、Web UI、数据库和存储等多个组件,使其更具可扩展性。
2. HuggingFace/OpenDeepResearch
HuggingFace 的 OpenDeepResarch 是唯一一个提到了在标准评测集(GAIA)下与原版 ChatGPT DeepResearch 分数比对的:This agent achieves 55% pass@1 on the GAIA validation set, compared to 67% for the original Deep Research.
下面是架构图:
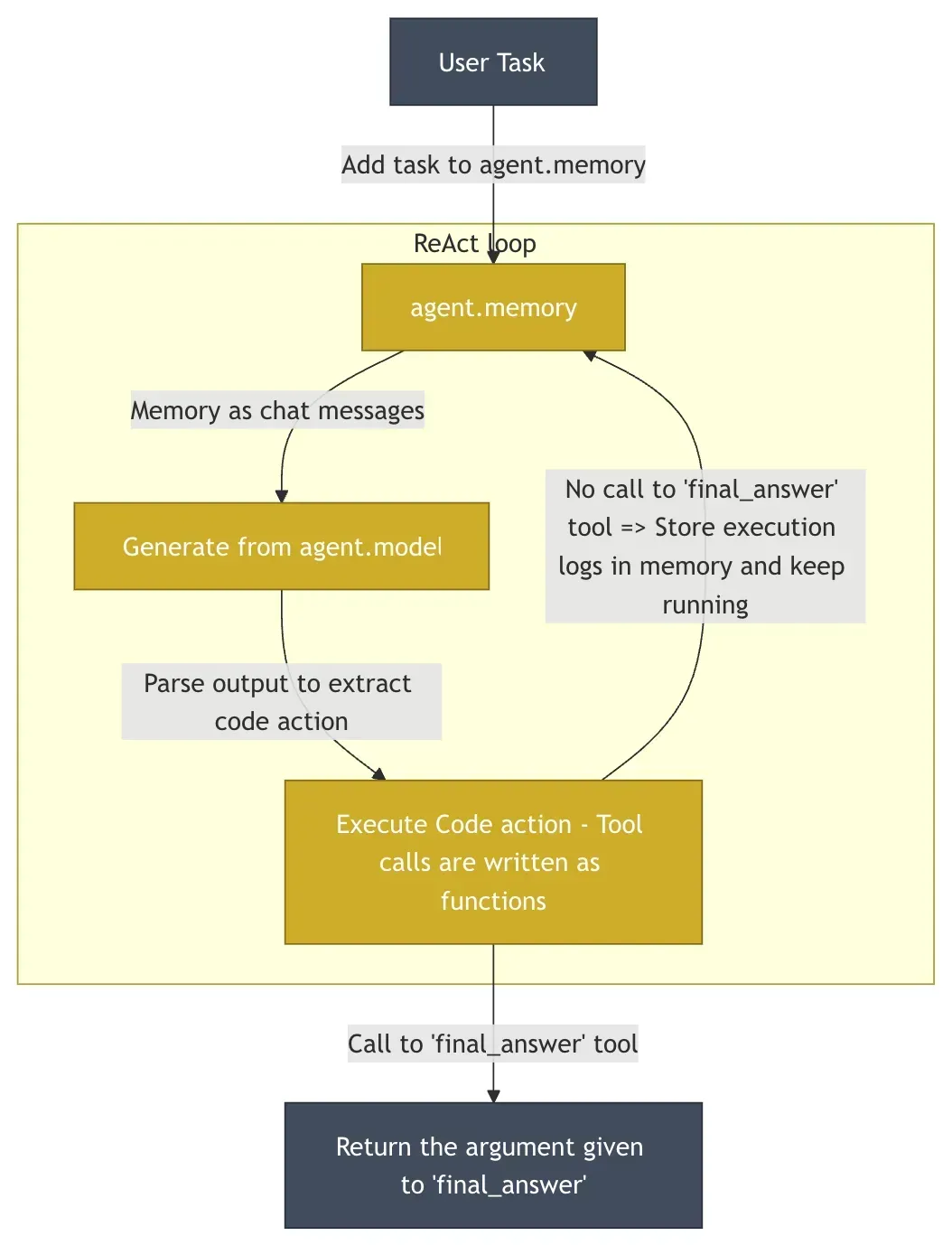
与 DeerFlow 的分层多智能体架构不同,huggingface/smolagents 项目采用了更轻量级、更注重代码和简洁性的架构。它的核心理念是提供一个极简的框架,让开发者可以轻松构建、调试和控制由大型语言模型(LLM)驱动的智能体(Agent)。
以下是 smolagents 项目架构的关键特点:
(1) 核心思想:简洁与最少抽象
- 轻量级代码库: 整个 smolagents 库的核心逻辑被有意地控制在很少的代码行数内(约1000行),这使得它非常容易理解和上手。
- 避免过度抽象: 许多AI智能体框架被批评有太多的抽象层,导致系统僵化且难以调试。smolagents 刻意避免了这一点,给予开发者更大的控制权和透明度。
(2) 核心架构:以代码为中心的智能体 (Code Agents)
smolagents 的主要方法是代码智能体 (CodeAgent)。这与其他框架主要依赖JSON格式来定义行为的方式形成了鲜明对比。
- 动作即代码: 在 smolagents 中,智能体的动作(actions)直接表现为 Python 代码片段。LLM 会生成一小段 Python 代码来执行下一步操作,而不是生成需要解析的JSON对象。
- 优势: 表现力强: 编程语言(如Python)天生就适合用来表达复杂的动作和逻辑。 组合性好: 代码可以轻松地进行嵌套、抽象和重用(例如定义函数),这是JSON难以做到的。 安全性: 为了安全地执行这些由AI生成的代码,smolagents 支持在沙盒环境(如 E2B)中运行。
(3) 主要智能体类型
该库提供了几种核心的智能体类型:
- CodeAgent: 这是最主要的智能体类型。它通过生成和执行 Python 代码来完成任务,并且可以调用预先定义好的工具。
- ToolCallingAgent: 虽然 CodeAgent 是核心,但 smolagents 仍然支持传统的、通过生成 JSON/文本 来调用工具的智能体,以兼容更广泛的用例和模型。
- MultiStepAgent: 这种智能体能够将一个复杂的任务分解成多个步骤,并周期性地生成或更新计划,以结构化、目标导向的方式逐步解决问题。
3. LangChainAI/OpenDeepResearch
langchain-ai/open_deep_research 项目(包括 LangChain 和 Together AI 的版本)的架构核心是一个多阶段、迭代和自反思(self-reflection)的智能体工作流,旨在模拟人类进行深度研究的过程。这个架构比简单的“提问-回答”模式要复杂得多,其设计目标是处理需要多步推理和信息整合的复杂主题。
(1) 以下是该项目架构的关键组成部分和特点
- 核心理念:Plan-Search-Reflect-Write (规划-搜索-反思-撰写) 整个架构围绕着一个清晰的研究流程展开,模仿了人类专家的研究方法:
- 规划 (Plan): 这是工作流的起点。一个“规划器”智能体会接收用户提出的研究主题,并将其分解成多个子问题或子主题。这个规划结果不仅指导后续的研究步骤,也构成了最终报告的大纲。
- 搜索 (Search): 根据规划阶段生成的子问题,系统会生成具体的搜索查询,并调用各种搜索工具(如 Tavily, Perplexity, ArXiv 等)来收集相关信息。这个过程可以是并行的,多个研究循环可以同时针对不同的子主题进行。
- 反思 (Self-Reflect): 这是该架构的关键所在。在收集到初步信息后,一个智能体会评估当前的信息是否足够,是否存在知识空白。如果发现信息不足或有新的问题出现,系统会生成新的、更精确的搜索查询,进入下一轮迭代。这种“自我反思”的循环会持续进行,直到信息足够全面。
- 撰写 (Write): 当所有的研究循环完成后,一个“撰写者”智能体会将所有收集到的、经过验证和提炼的信息进行整合,并根据最初的规划大纲,生成一份结构完整、引用充分的综合性研究报告。
(2) 该项目提供了两种主要的实现方式,各有侧重
图状工作流 (Graph-based Workflow)
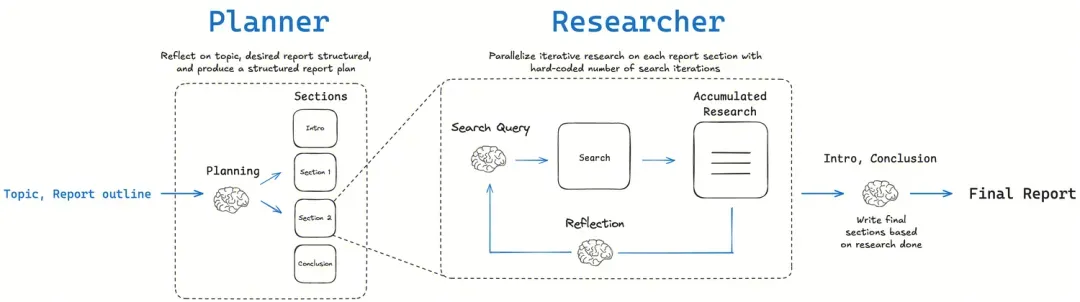
实现: 主要使用 LangGraph 这样的库来构建。
特点: 这种方式将研究的每一步(规划、搜索、反思等)都建模为图中的一个节点(Node),使得整个流程非常清晰、可追溯。它特别强调人机协作(Human-in-the-Loop),允许用户在关键节点(如规划完成后)进行审查和提供反馈,然后再继续执行。这种实现方式控制力强,适合对报告质量和准确性要求极高的场景。
4. Multi-agent 迭代循环 (Iterative Loop)
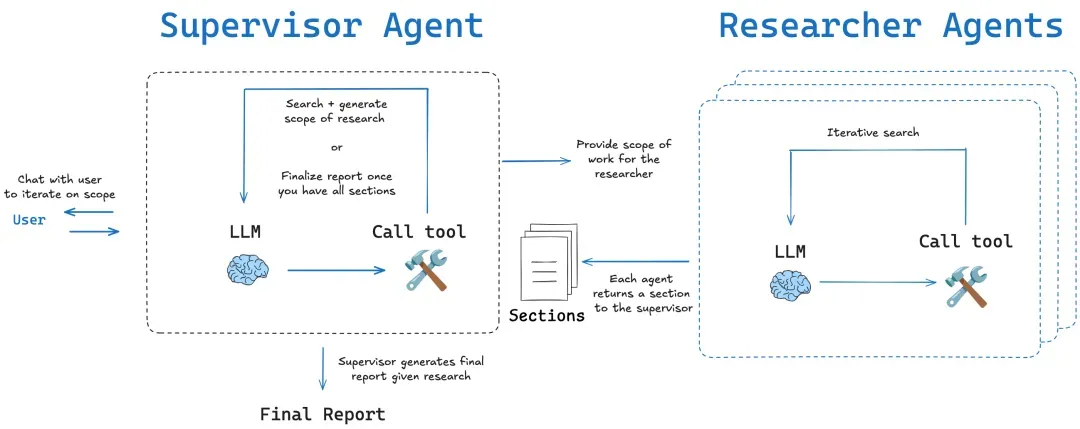
分为两种模式:
- 简单模式 (Simple): 跳过初始的规划步骤,直接进入一个单一的、迭代的研究循环。这种模式速度更快,适用于较窄或较具体的研究问题。
- 深度模式 (Deep): 包含初始的规划步骤,并为每个子主题部署并行的、独立的迭代研究器。这种模式更深入、更全面,适合复杂和宽泛的研究主题。
特点:这种方式的核心是递归的研究循环,在每一次循环中,智能体都会评估已有信息,生成新的问题,并进一步搜索,直到达到预设的深度(depth)和广度(breadth)。
5. SkyworkAI/DeepResearchAgent
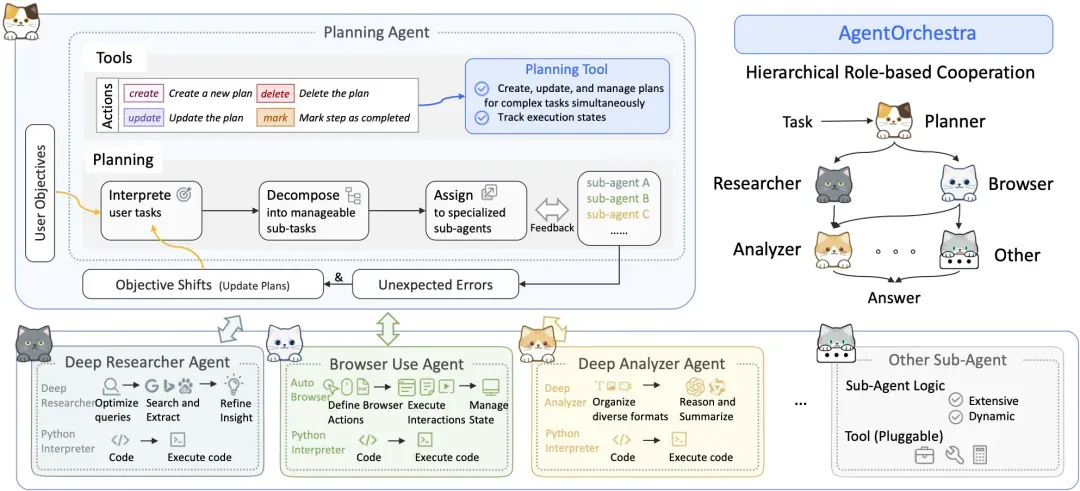
SkyworkAI/DeepResearchAgent 项目采用了明确的两层(Two-Layer)架构,这是一个分工清晰的层级式多智能体系统。其核心思想是通过一个高层规划者来协调多个底层的专业执行者,从而实现对复杂任务的分解和高效执行。
以下是对这个两层架构的详细说明:
(1) 第一层:顶层规划智能体 (Top-Level Planning Agent)
这一层是整个系统的“大脑”和“指挥官”。它不执行具体的研究任务,而是负责宏观的战略规划和协调。
核心职责:
- 理解与分解 (Understand & Decompose): 当接收到用户输入的复杂任务时,顶层规划智能体首先会深入理解任务的整体目标。然后,它会将这个宏大的目标分解成一系列更小、更具体、可管理的子任务。
- 规划与分配 (Plan & Assign): 在分解任务后,它会制定一个详细的工作流程计划,并决定每个子任务应该由哪个(或哪些)下层专业智能体来执行。
- 动态协调 (Dynamic Coordination): 在任务执行过程中,它会持续监控整个流程的进展,动态地协调下层智能体之间的协作,确保任务能够顺利、连贯地完成。
简单来说,顶层规划智能体就像一个项目经理,它制定蓝图、分配资源,并确保团队成员(即下层智能体)步调一致地工作。
(2) 第二层:底层专业智能体 (Specialized Lower-Level Agents)
这一层是系统的“手”和“脚”,由多个具备不同专业技能的智能体组成,负责执行顶层规划师分配下来的具体任务。
DeepResearchAgent 主要包含以下几个专业智能体:
- 深度分析器 (Deep Analyzer): 职责: 负责对输入的信息进行深入分析,提取关键的见解、实体和潜在需求。它支持分析多种数据类型,包括纯文本和结构化数据。 作用: 在研究初期,它可以帮助系统更好地理解问题背景和现有资料。
- 深度研究员 (Deep Researcher): 职责: 这是执行核心研究任务的智能体。它根据指定的议题或问题,进行彻底的研究,检索、整合并提炼高质量信息。它能够自动生成研究报告或知识摘要。 作用: 负责信息搜集和初步的内容生成。
- 浏览器使用者 (Browser Use): 职责: 专门负责自动化浏览器操作,执行网页搜索、信息提取和数据采集等任务。 作用: 作为“深度研究员”的得力助手,为其从互联网上获取最新、最相关的信息。
(3) 架构总结与启发
DeepResearchAgent 的这个两层架构的优势在于其清晰的层次化分工。
- 顶层专注于“做什么”和“如何做”(What & How),负责策略和规划。
- 底层专注于“执行”(Execution),负责具体操作。
这种设计使得系统在处理复杂问题时条理清晰,不易混乱。同时,它具有很强的可扩展性,未来可以方便地在第二层加入更多具有新能力的专业智能体(比如数据可视化智能体、代码执行智能体等),而无需改动顶层的核心规划逻辑。
值得一提的是,该项目的 README 文件中明确提到,其架构主要受到了 smolagents 的启发,并在其基础上进行了模块化和异步化等改进,使其结构更清晰,更适合多智能体协作。
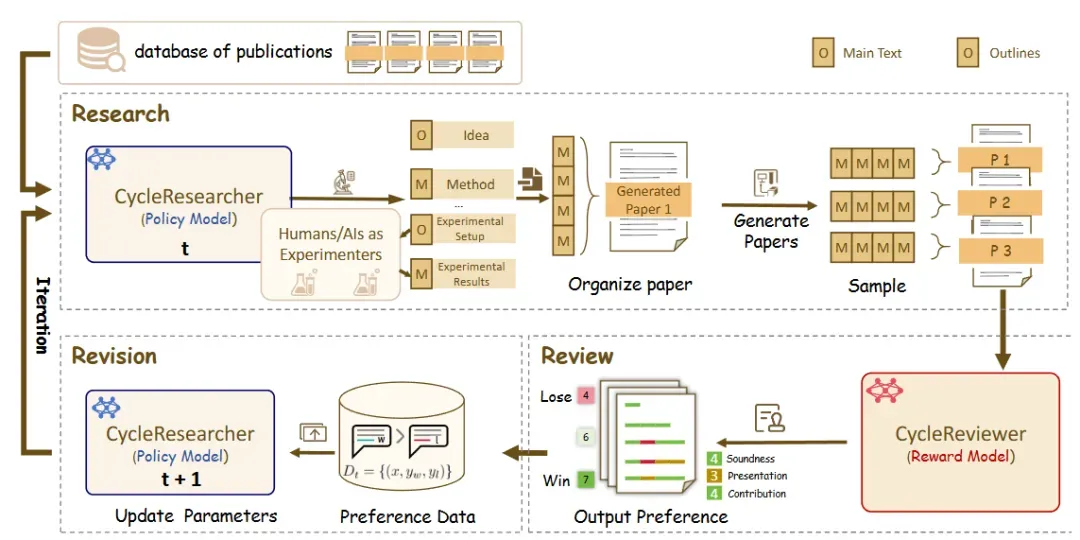
6. zhu-minjun/Researcher
总结来说,zhu-minjun/Researcher 的架构有以下几个鲜明特点:
- 分阶段的多智能体协作:通过规划、执行、整合、批判等不同角色的智能体各司其职,流水线式地完成复杂任务。
- 高效的并行处理:为每个子主题创建独立的执行智能体,并让它们同时工作,显著缩短了研究时间。
- 独特的自我批判机制:引入了“批判智能体”对产出结果进行审核和反馈,形成了一个迭代优化的闭环。这使得它不仅仅是一个信息的聚合器,更是一个力求产出高质量、无偏见内容的“研究员”。
与其他项目相比,它将“反思”(Reflection)这一概念,具象化为了一个独立的“批判智能体”和一个明确的“修正”动作,使其自我完善的路径更加清晰和结构化。
DeepReviewer的 Best 模式提供最全面的审核体验,包括背景知识搜索、多审核者模拟和自我验证:
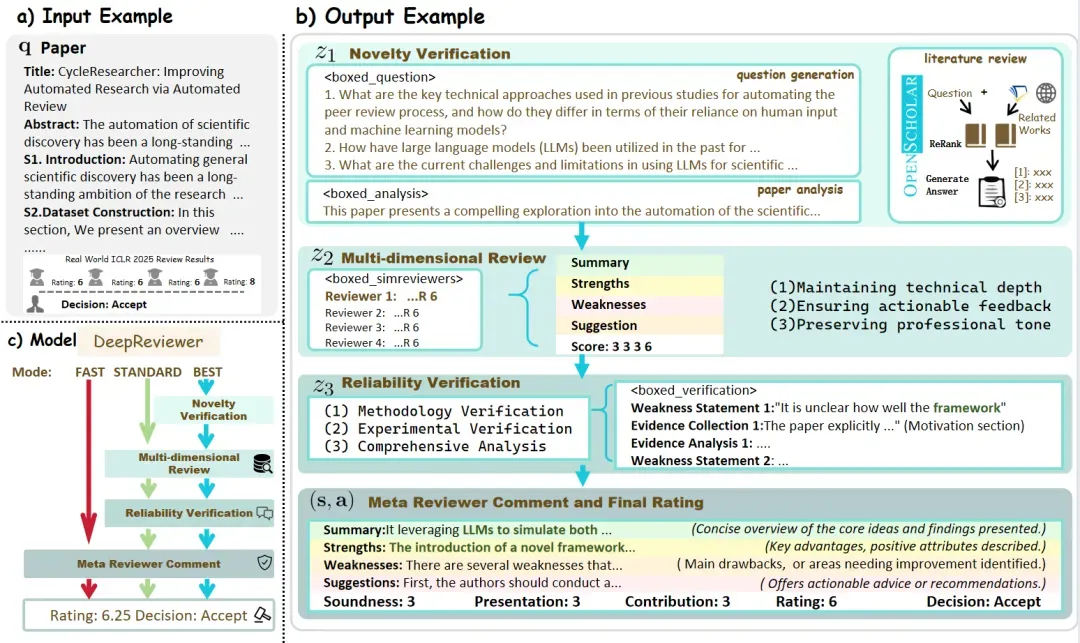
Researcher 的架构是一个包含“自我批判”环节的、多智能体协作的自动化研究工作流。它与其他研究智能体项目(如 DeepResearchAgent 或 open_deep_research)在流程上有一些相似之处,但其独特的“批判-修正”循环是其架构的核心亮点。
该项目的整体架构和工作流程可以分解为以下几个关键步骤:
(1) 第一步:规划智能体 (Planning Agent)
职责:接收用户输入的初始研究主题。
工作内容:
- 首先,它会生成一系列相关的、更具探索性的问题,以拓宽研究的广度和深度。
- 然后,它会基于这些问题创建一个结构化的研究计划或报告大纲。这个大纲不仅指导了后续的研究方向,也直接构成了最终报告的骨架。
(2) 第二步:并行执行智能体 (Parallel Execution Agents)
职责:根据“规划智能体”制定的提纲,分头执行具体的研究任务。
工作内容:
- 系统会为大纲中的每一个子主题,都启动一个独立的“执行智能体”。
- 这些智能体并行工作,各自负责自己的子主题。它们会使用搜索引擎(如 DuckDuckGo)进行信息检索,利用工具(如 newspaper4k)抓取和解析网页内容,并对收集到的信息进行总结。
- 这种并行处理的架构设计,极大地提高了研究的效率,可以同时对多个方面进行深入探索。
(3) 第三步:整合与初稿生成 (Integration and Draft Generation)
职责:汇总所有并行研究的结果,形成一份初步的研究报告。
工作内容:
- 系统会收集所有“执行智能体”完成的子主题研究摘要。
- 然后,它将这些摘要按照“规划智能体”最初设计的报告大纲进行排序和组合,最终生成一份内容完整、结构清晰的初稿。
(4) 第四步:批判与修正智能体 (Critique & Revision Agent)
这是该项目架构中最具特色的一环,构成了一个质量控制循环。
职责:像一个严谨的审稿人一样,对生成的初稿进行评估和批判,并指导修正。
工作内容:
- 批判 (Critique): 一个专门的“批判智能体”会阅读整份初稿,并根据预设的规则(例如,检查事实的准确性、观点的客观性、信息的全面性、是否存在偏见等)提出具体的、有建设性的修改意见。
- 修正 (Revision): 系统根据“批判智能体”的反馈,返回到达成共识前的步骤,对研究报告进行重新整理和修正,以提升报告的整体质量。
三、商业化深度研究智能体
分析完开源框架后,笔者体验一下市面上相关的商业化智能体应用:使用闭源应用研究同一个问题,并分析他们的逻辑、输出和交互。
闭源应用整体对比:
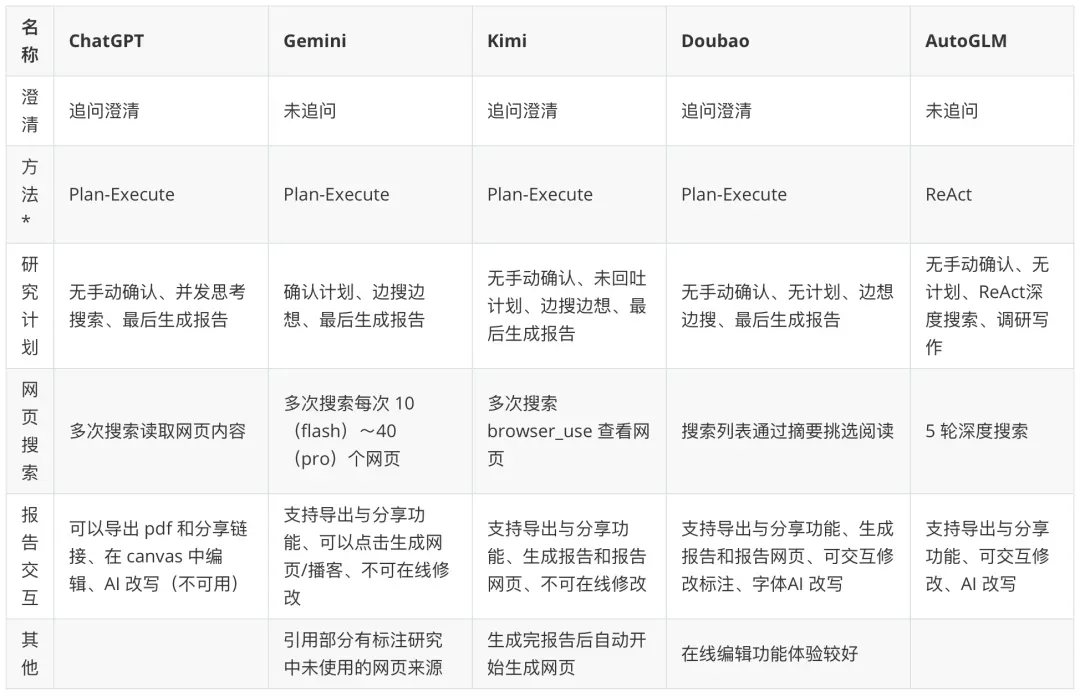
备注 * 为笔者猜测使用的智能体范式。
四、总结
本篇文档系统梳理了当前主流的开源与商业化深度研究智能体框架。开源方案如 DeerFlow、OpenDeepResearch(HuggingFace)、LangChainAI/OpenDeepResearch、SkyworkAI/DeepResearchAgent、HKUDS/AutoDeepResearch 及 zhu-minjun/Researcher 各有侧重:有的强调分层多智能体与模块化(如 DeerFlow),有的追求极简代码和代码即动作(如 HuggingFace/smolagents),也有的主打多阶段自反思与人机协作(如 LangChainAI/OpenDeepResearch)。在工具集成、任务分解、执行方式(JSON/函数调用 vs. 代码生成)、质量控制等方面,各框架实现细节和理念均有所不同。
商业化产品如 ChatGPT、Gemini、Kimi、豆包、AutoGLM 则在交互体验、报告输出、搜索能力和质量控制等方面各具特色,部分产品支持计划确认、交互式报告编辑、多轮深度搜索及生成对应网页(方便转换成 PPT)。
总体来看,深度研究智能体的发展正朝着更高的自动化、结构化和可控性方向演进。不同框架适合不同场景和需求,选择时可结合自身实际情况权衡。


