工程

SIGGRAPH Asia 2025|电影级运镜一键克隆!港中文&快手可灵团队发布CamCloneMaster
本文第一作者罗亚文,香港中文大学 MMLab 博士一年级在读,研究方向为视频生成,导师为薛天帆教授。 个人主页:,你是否曾梦想复刻《盗梦空间》里颠覆物理的旋转镜头,或是重现《泰坦尼克号》船头经典的追踪运镜? 在 AI 视频生成中,这些依赖精确相机运动的创意,实现起来却往往异常困难。

智源开源EditScore:为图像编辑解锁在线强化学习的无限可能
随着多模态大模型的不断演进,指令引导的图像编辑(Instruction-guided Image Editing)技术取得了显著进展。 然而,现有模型在遵循复杂、精细的文本指令方面仍面临巨大挑战,往往需要用户进行多次尝试和手动筛选,难以实现稳定、高质量的「一步到位」式编辑。 强化学习(RL)为模型实现自我演进、提升指令遵循能力提供了一条极具潜力的路径。

豆包是如何炼成的?字节放出自研万卡训练系统ByteRobust论文
大型语言模型(LLM)训练的核心基础设施是 GPU。 现如今,其训练规模已达到数万块 GPU,并且仍在持续扩大。 同时,训练大模型的时间也越来越长。

清华、快手提出AttnRL:让大模型用「注意力」探索
从 AlphaGo 战胜人类棋手,到 GPT 系列展现出惊人的推理与语言能力,强化学习(Reinforcement Learning, RL)一直是让机器「学会思考」的关键驱动力。 然而,在让大模型真正掌握「推理能力」的道路上,探索效率仍是一道难以逾越的鸿沟。 当下最前沿的强化学习范式之一——过程监督强化学习(Process-Supervised RL, PSRL),让模型不再只看「结果对不对」,而是学会在「推理过程」中不断修正自己。

RewardMap: 通过多阶段强化学习解决细粒度视觉推理的Sparse Reward
本研究由西湖大学 ENCODE Lab 牵头,联合同济大学、浙江大学和新加坡国立大学共同完成。 团队在大模型强化学习与多模态推理方向具有深厚研究基础。 近年来,大语言模型(LLMs)以及多模态大模型(MLLMs)在多种场景理解和复杂推理任务中取得突破性进展。

大模型微调范式认知再被颠覆?UIUC、Amazon团队最新研究指出SFT灾难性遗忘问题或被误解
在大模型微调实践中,SFT(监督微调)几乎成为主流流程的一部分,被广泛应用于各类下游任务和专用场景。 比如,在医疗领域,研究人员往往会用领域专属数据对大模型进行微调,从而显著提升模型在该领域特定任务上的表现。 然而,问题随之而来:SFT 是否会让模型 “遗忘” 原本的通用能力?

NeurIPS 2025 | CMU、清华、UTAustin开源ReinFlow,用在线RL微调机器人流匹配策略
作者简介:本文第一作者为卡耐基梅隆大学机器人所研究生 Tonghe Zhang,主要研究方向为机器人操作大模型和全身控制算法。 合作者为德克萨斯大学奥斯汀分校博士生 Sichang Su, 研究方向为强化学习和通用机器人策略。 指导教师是清华大学和北京中关村学院的 Chao Yu 教授以及清华大学 Yu Wang 教授。

ICCV 2025 | 扩散模型生成手写体文本行的首次实战,效果惊艳还开源
本文中,来自华南理工大学、MiroMind AI、新加坡国立大学以及琶洲实验室的研究者们提出一种新的生成模型 Diffusion Brush,首次将扩散模型用于文本行级的手写体生成,在英文、中文等多语言场景下实现了风格逼真、内容准确、排版自然的文本行生成。 研究背景AI 会写字吗? 在写字机器人衍生换代的今天,你或许并不觉得 AI 写字有多么困难。

微软BitDistill将LLM压缩到1.58比特:10倍内存节省、2.65倍CPU推理加速
大语言模型(LLM)不仅在推动通用自然语言处理方面发挥了关键作用,更重要的是,它们已成为支撑多种下游应用如推荐、分类和检索的核心引擎。 尽管 LLM 具有广泛的适用性,但在下游任务中高效部署仍面临重大挑战。 随着模型规模的急剧扩大,这些挑战被进一步放大,尤其是在资源受限的设备上(如智能手机),内存占用和计算开销都变得极其昂贵。

AGILE:视觉学习新范式!自监督+交互式强化学习助力VLMs感知与推理全面提升
现有视觉语言大模型(VLMs)在多模态感知和推理任务上仍存在明显短板:1. 对图像中的细粒度视觉信息理解有限,视觉感知和推理能力未被充分激发;2. 强化学习虽能带来改进,但缺乏高质量、易扩展的 RL 数据。

突破FHE瓶颈,Lancelot架构实现加密状态下的鲁棒聚合计算,兼顾「隐私保护」与「鲁棒性」
在金融、医疗等高度敏感的应用场景中,拜占庭鲁棒联邦学习(BRFL)能够有效避免因数据集中存储而导致的隐私泄露风险,同时防止恶意客户端对模型训练的攻击。 然而,即使是在模型更新的过程中,信息泄露的威胁仍然无法完全规避。 为了解决这一问题,全同态加密(FHE)技术通过在密文状态下进行安全计算,展现出保护隐私信息的巨大潜力。

Codeforces难题不够刷?谢赛宁等造了个AI出题机,能生成原创编程题
Rich Sutton 曾说过:「AI 只能在可以自我验证的范围内创造和维持知识。 」爱因斯坦与英费尔德在合著的《物理学的进化》中也写道:「提出一个问题往往比解决问题更重要,后者或许仅仅是数学或实验技巧的问题。 而提出新的问题、新的可能性,从新的角度审视旧的问题,则需要创造性的想象力,并标志着科学的真正进步。

SIGGRAPH Asia 2025 | OmniPart框架,让3D内容创作像拼搭积木一样简单
本文的主要作者来自香港大学、VAST、哈尔滨工业大学及浙江大学。 本文的第一作者为香港大学博士生杨运涵。 本文的通讯作者为香港大学刘希慧教授与VAST 公司首席科学家曹炎培博士。

轻量高效,即插即用:Video-RAG为长视频理解带来新范式
尽管视觉语言模型(LVLMs)在图像与短视频理解中已取得显著进展,但在处理长时序、复杂语义的视频内容时仍面临巨大挑战 —— 上下文长度限制、跨模态对齐困难、计算成本高昂等问题制约着其实际应用。 针对这一难题,厦门大学、罗切斯特大学与南京大学联合提出了一种轻量高效、无需微调的创新框架 ——Video-RAG。 该研究已被机器学习顶级会议 NeurIPS 2025 接收,为长视频理解任务提供了全新的解决思路。

一个运行了80年的算法,我们现在才真正理解它?
从你网购的包裹如何以最快速度送达,到航空公司如何规划数千架飞机的航线以节省燃料,背后都有一个近 80 岁「高龄」的数学方法在默默工作。 它被誉为优化领域的基石,高效又令人信赖。 然而,一个奇怪的事实是:几十年来,没有人能从理论上完美解释它为何如此高效。
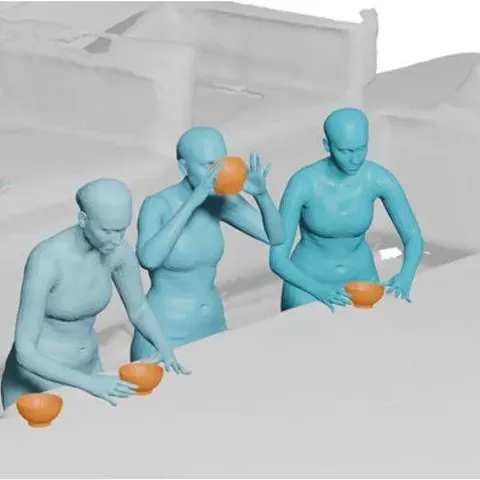
ACMMM 2025 | 北大团队提出 InteractMove:3D场景中人与可移动物体交互动作生成新框架
该论文的第一作者和通讯作者均来自北京大学王选计算机研究所,第一作者为博士生蔡鑫豪,通讯作者为博士生导师刘洋。 团队近年来在 TPAMI、IJCV、CVPR、ICML 等顶会上有多项代表性成果发表,多次荣获国内外多模态理解与生成竞赛冠军,和国内外知名高校、科研机构广泛开展合作。 本文主要介绍来自该团队的最新论文 InteractMove:Text-Controlled Human-Object Interaction Generation in 3D Scenes with Movable Objects。

Self-Forcing++:让自回归视频生成模型突破 4 分钟时长极限
本工作由加州大学洛杉矶分校与字节 Seed 等团队联合完成。 在扩散模型持续引领视觉生成浪潮的今天,图像生成早已臻于极致,但视频生成仍被一个关键瓶颈困住——时长限制。 目前多数模型还停留在数秒短视频的生成,Self-Forcing 让视频生成首次跨入 4 分钟高质量长视频时代,且无需任何长视频数据再训练。

稳定训练、数据高效,清华大学提出「流策略」强化学习新方法SAC Flow
本文介绍了一种用高数据效率强化学习算法 SAC 训练流策略的新方案,可以端到端优化真实的流策略,而无需采用替代目标或者策略蒸馏。 SAC FLow 的核心思想是把流策略视作一个 residual RNN,再用 GRU 门控和 Transformer Decoder 两套速度参数化。 SAC FLow 在 MuJoCo、OGBench、Robomimic 上达到了极高的数据效率和显著 SOTA 的性能。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉