基准测试是检验大模型能力的一种方式,一般而言,一个有用的基准既要足够难,又要贴近现实:问题既能挑战前沿模型,又要反映真实世界的使用场景。
然而,现有测试面临着「难度–真实性」的矛盾:侧重于考试的基准往往被人为设置得很难,但实际价值有限;而基于真实用户交互的基准又往往偏向于简单的高频问题。
在此背景下,来自斯坦福大学、华盛顿大学等机构的研究者探索了一种截然不同的方式:在未解决的问题上评估模型的能力。
与一次性打分的静态基准不同,该研究不断收集未解决的问题,然后通过验证器辅助筛选与社区验证机制,实现对模型的持续异步评估。
具体而言,本文提出了 UQ(Unsolved Questions),这是一个由 500 道题组成的测试集,涵盖计算机理论、数学、科幻、历史等主题,用于考察模型在推理、事实准确性以及浏览等方面的能力。UQ 在设计上兼具难度大与贴近真实两大特点:这些问题大多是人类遇到但尚未解决的难题,因此攻克它们可直接产生现实价值。

论文标题:UQ: Assessing Language Models on Unsolved Questions
论文地址:https://arxiv.org/pdf/2508.17580v1
项目地址:https://uq.stanford.edu/
总结而言,本文贡献如下:
提出了 UQ 数据集及其收集流程:结合规则过滤器、大语言模型评审以及人工审核,以确保最终问题的质量;
UQ-Validators:复合验证策略,利用生成器–验证器之间的能力差距来构建无真值验证系统(一般而言模型验证能力优于生成能力),并对候选答案进行预筛选,以便后续人工审核;
UQ-Platform:一个开放平台,让专家能够共同验证问题与答案,从而实现持续的、异步的、社区驱动的评估。
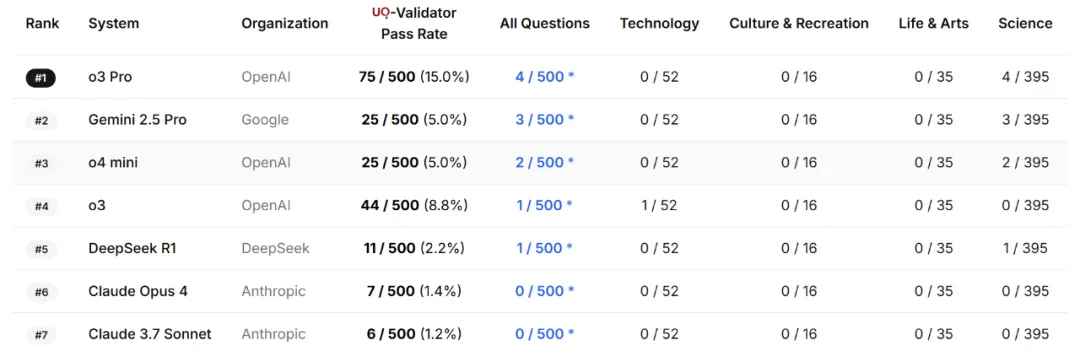
实验中,表现最好的模型仅在 15% 的问题上通过了 UQ 验证,而初步人工核查已经在这些通过验证的答案中识别出一些正确解答。
数据集介绍
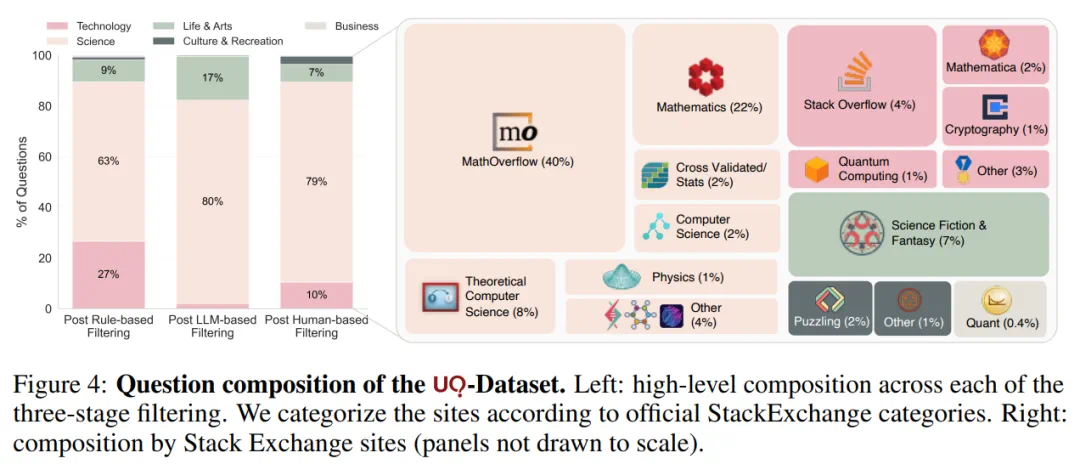
UQ 数据集由 500 道具有挑战性的未解决问题组成,问题来源问答社区 Stack Exchange,并且是经过三轮筛选得到的。
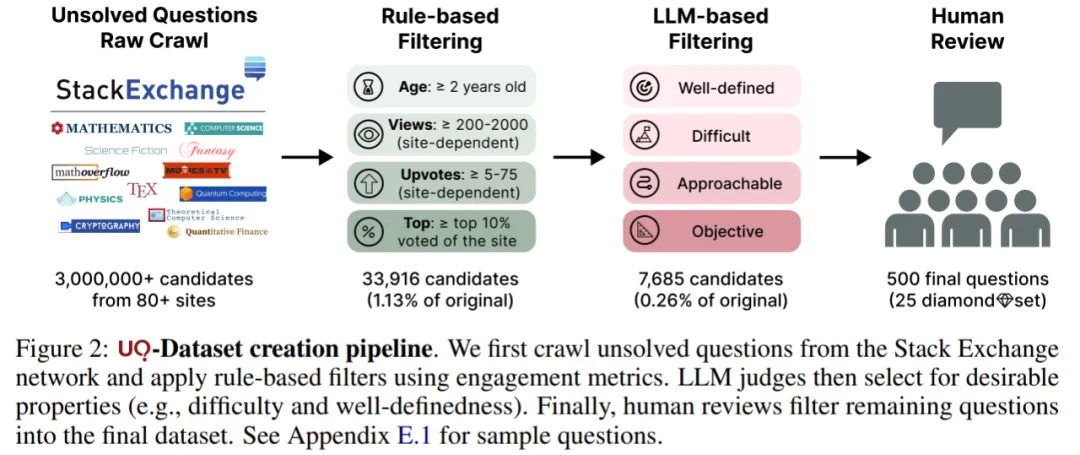
在筛选流程上,本文首先人工选择了 80 个 Stack Exchange 社区(例如 Math Overflow、Physics),并抓取其中未解答的问题,得到大约 300 万个原始候选问题。
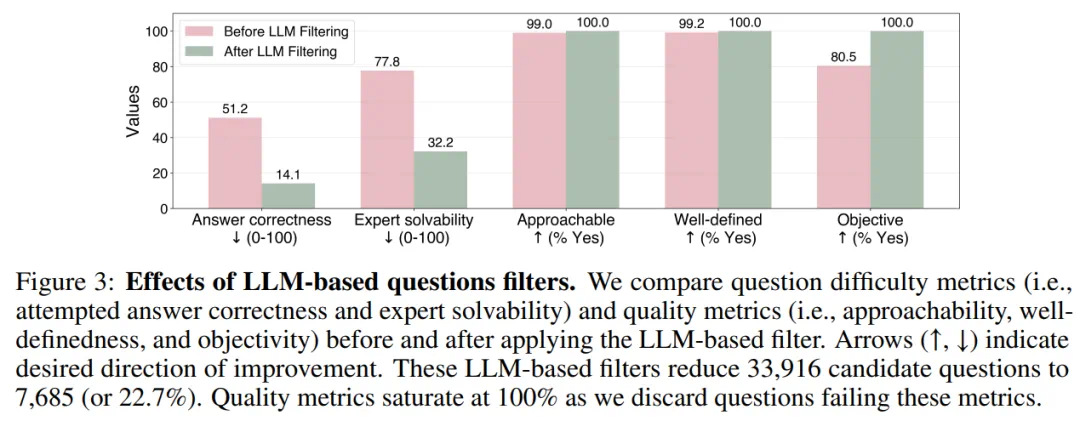
随后,进入多阶段筛选流程。筛选的每一阶段都会逐步缩小问题池:基于规则的筛选将问题缩减至 33,916 个(占原始问题池的 1.13%);基于大语言模型的筛选进一步缩减至 7,685 个(占原始的 0.26%);最终通过人工审核(如剔除残留的重复、过于简单、偏题或违反规则的问题),得到一个精心整理的 500 道题集(占原始的 0.02%)。
随着问题在筛选流程中逐步推进,它们的难度和质量也在逐渐提升。尤其是基于大语言模型的筛选,显著提高了问题的难度。
数据集组成如下所示,主要包含科学类问题,其次是技术类与生活艺术类。本文还发现不同领域的问题能探测模型的不同能力:例如数学问题通常需要开放式证明,而科幻奇幻类问题则偏重浏览检索能力(如根据片段情节识别书籍名称)。
一旦某个问题被判定为已解决,研究者就会在后续版本中将该问题移除,并用新的未解决问题替换。
UQ 验证器
虽然 UQ 数据集非常具有价值,但要将其用作模型性能的基准,仍需配套的评分指标。然而,由于缺乏标准答案,无法像考试基准那样进行自动验证。
因此,本文转向无监督验证器,即无需标准答案。由于未解问题往往极具挑战性,这些验证器的主要目标并非证明某个候选答案正确,而是排除错误的候选答案;因此,本文刻意使用 validator(验证器)一词,而非 judge 或 verifier。
需要特别指出的是,由于缺少标准答案,这类验证器本身可能经常出错,但它们仍能在后续人工审核中发挥辅助作用。
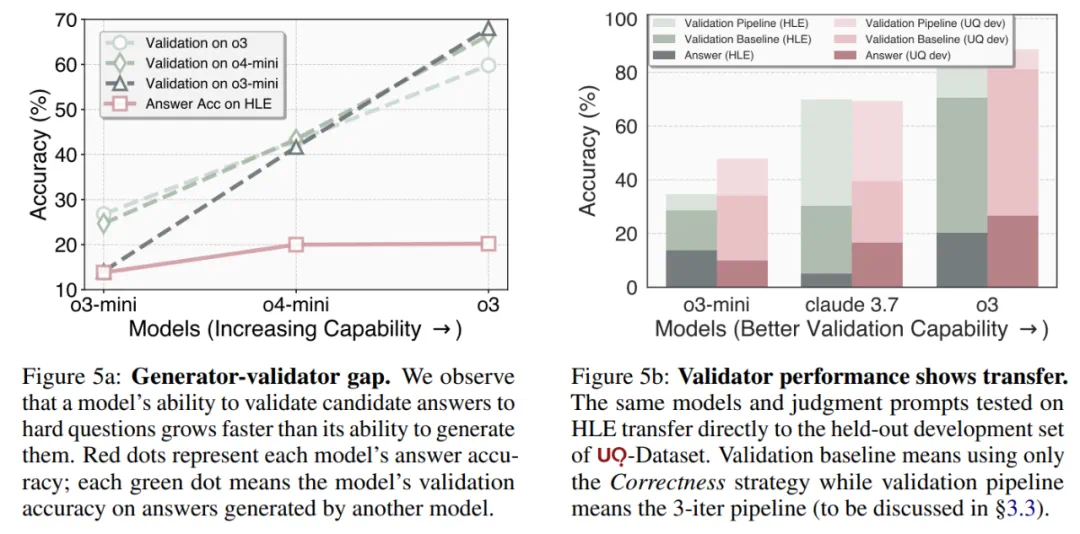
据了解,本文之所以开发无需标准答案的验证器,核心动机在于这样一个假设:对难题候选答案进行验证可能比生成这些答案更容易。实验中采用了这样的流程,让一系列能力递增的模型(例如 o3-mini → o4-mini → o3)回答这 500 道题,记录它们的答题准确率;接着,让每个模型在不接触标准答案的情况下,验证其他所有模型给出的答案;最后,用真实答案对这些验证结论进行打分,计算验证准确率。
图 5 左显示:随着模型能力的提升,它们在验证准确率上的进步速度明显快于答题准确率。
实验中使用的验证器 pipeline:

实验及结果
实验评估了 5 个模型,包括 o3、o4-mini、o3-mini、Gemini 2.5 Pro 和 Claude 3.7 Sonnet。
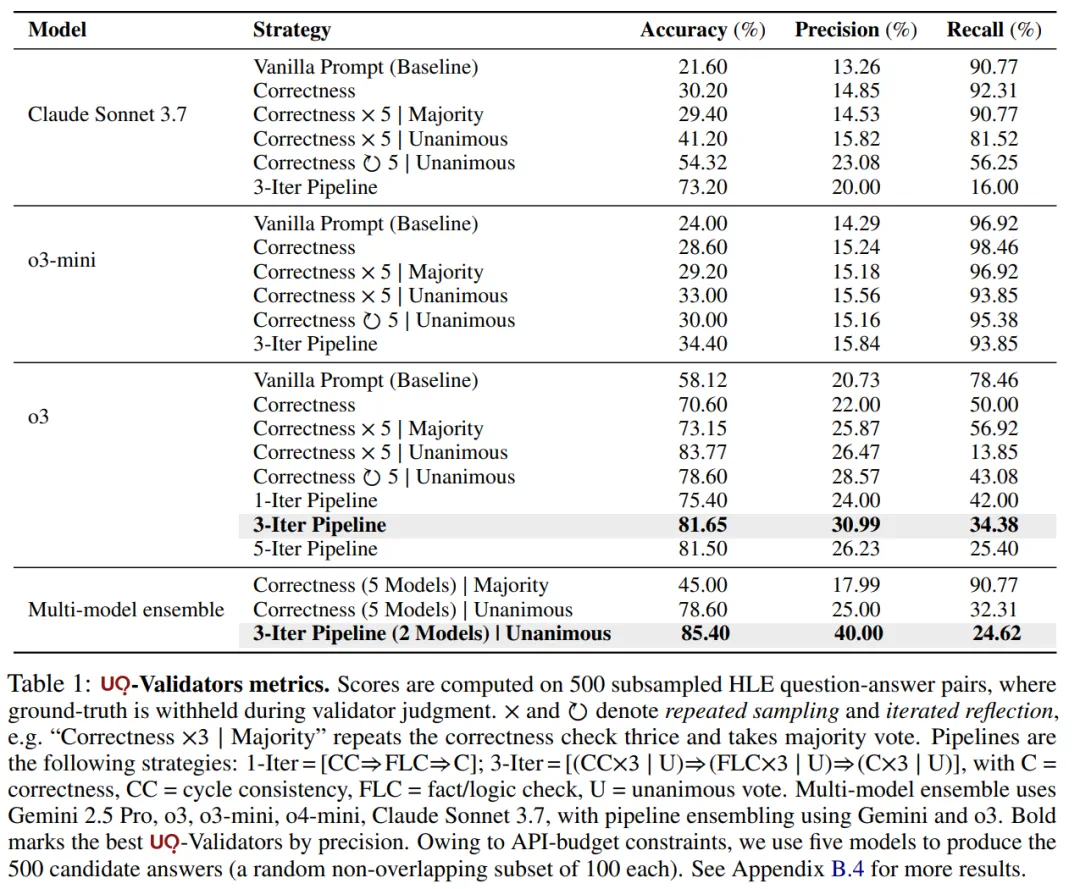
表 1 结果显示,与原始基线相比,验证策略能够实质性地提高验证的准确率和精度。例如,对 Claude 3.7 Sonnet 而言,准确率从 21.6% 提升到 73.2%,精度从 13.26% 提升到 20%,但往往是以召回率下降为代价。
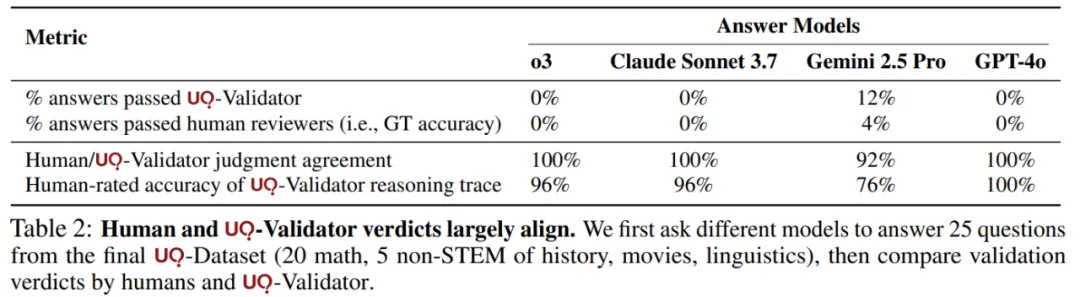
为了确认最终得到的最佳 UQ 验证器对人类评审者有帮助,该研究邀请若干评审员对 25 个验证问题进行评分,判断其给出的判断理由链是否在逻辑上成立。表 2 显示,人类评审与验证器的一致率及理由链的准确性都很高,表明该验证器能为人类评审者提供有效支持。
将大语言模型用于答案验证时,另一个挑战是它们常常表现出明显的评估偏见。当研究者把前沿模型直接应用于本场景时,发现所有模型在评估自身或同系模型(即同一开发者的模型)时,都出现了过度乐观现象:预测出的模型性能远高于实际性能,如图 7 所示。
Gemini 明显偏向自身,相对于其他模型给出显著更高的评分;
Claude 对所有答案模型(不仅仅是自身)都表现出过度乐观;
OpenAI 的 o 系列模型则对其他 o 系列同门模型给出过高评价。
随着模型能力递增(o3-mini → o3),这种偏见虽有所降低,但并未彻底消除。
本文进一步发现,采用复合验证器能够显著削弱答案验证中的自我偏见与过度乐观。

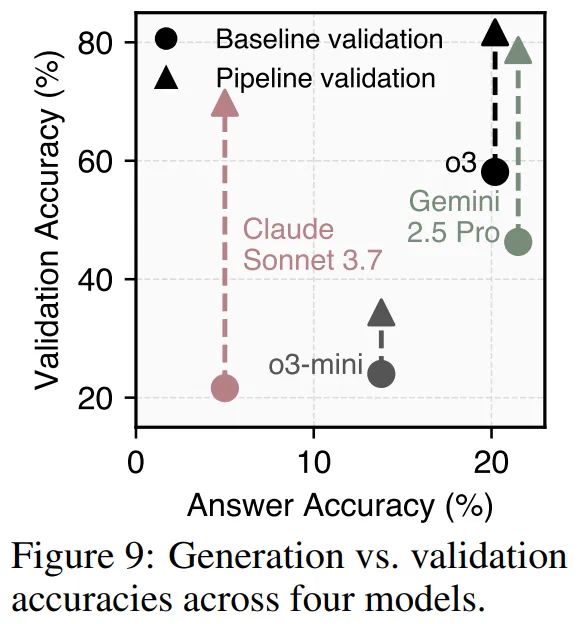
最后,本文还发现,一个更强的答案生成模型并不一定就是更强的答案验证模型。
本文通过基线提示法和 3 轮迭代验证流程绘制了模型在 500 个 HLE 问题上的验证准确率与答案准确率关系图。虽然更好的答案性能通常预示着更好的验证性能(整体呈上升趋势),但并非绝对。
例如:在没有流程验证时,o3 作为答案模型弱于 Gemini 2.5 Pro,但作为验证模型却更强;采用流程验证后,o3-mini 与 Claude 3.7 Sonnet 之间观察到同样的逆转趋势。此外,尽管 Claude 3.7 Sonnet 在答案准确率上显著落后于 Gemini 2.5 Pro,但其基于流程验证的表现却超越了 Gemini 2.5 Pro 的基线验证性能。
了解更多内容,请参考原论文。