
张昊,伊利诺伊大学香槟分校(UIUC)博士生,研究方向涵盖 3D/4D 重建、生成建模与物理驱动动画。目前在 Snap Inc. 担任研究实习生,曾于 Stability AI 和 上海人工智能实验室实习。本项目 Stable Part Diffusion 4D (SP4D) 由 Stability AI 与 UIUC 联合完成,能够从单目视频生成时空一致的多视角 RGB 与运动学部件序列,并进一步提升为可绑定的三维资产。个人主页:https://haoz19.github.io/

论文标题:Stable Part Diffusion 4D: Multi-View RGB and Kinematic Parts Video Generation
论文链接:https://arxiv.org/pdf/2509.10687
项目主页:https://stablepartdiffusion4d.github.io/
研究背景与动机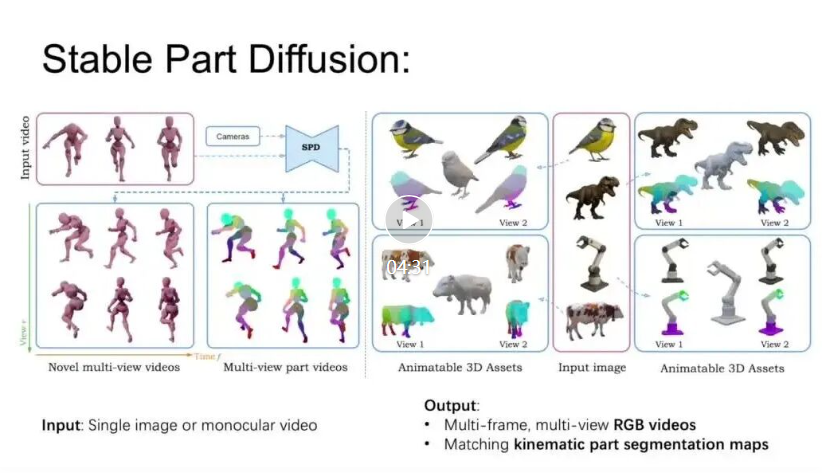
在角色动画和 3D 内容制作中,rigging(骨骼绑定)与部件分解是实现可动画化资产的核心。然而,现有方法存在明显局限:
自动 rigging:依赖规模有限的 3D 数据集及骨骼/蒙皮标注,难以覆盖多样化的物体形态与复杂姿态,导致模型泛化性不足。
部件分解:现有方法多依赖语义或外观特征(如「头部」、「尾部」、「腿」等)进行分割,缺乏对真实运动学结构的建模,结果在跨视角或跨时间序列上往往不稳定,难以直接应用于动画驱动。

为此,我们提出核心动机:利用大规模 2D 数据和预训练扩散模型的强大先验知识,来解决运动学部件分解的问题,并进一步延伸到自动 rigging。 这一思路能够突破 3D 数据稀缺的瓶颈,让 AI 真正学会生成符合物理运动规律的 3D 可动画资产。
研究方法与创新
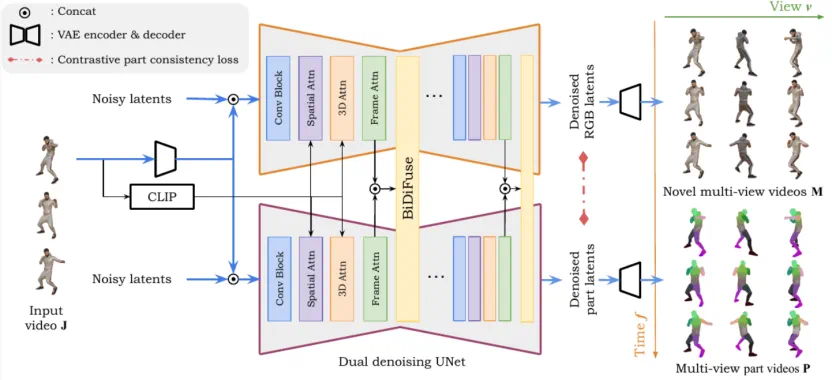
基于这一动机,我们提出了 Stable Part Diffusion 4D (SP4D) —— 首个面向运动学部件分解的多视角视频扩散框架。主要创新包括:
双分支扩散架构:同时生成外观与运动学结构,实现 RGB 与部件的联合建模。
BiDiFuse 双向融合模块:实现 RGB 与部件信息的跨模态交互,提高结构一致性。
对比一致性损失:确保同一部件在不同视角、不同时间下保持稳定一致。
KinematicParts20K 数据集:团队基于 Objaverse-XL 构建超过 20,000 个带骨骼注释的对象,提供高质量训练与评估数据。
这一框架不仅能生成时空一致的部件分解,还能将结果提升为 可绑定的 3D 网格,推导骨骼结构与蒙皮权重,直接应用于动画制作。
实验结果
在 KinematicParts20K 验证集上,SP4D 相较现有方法取得了显著提升:
分割精度:mIoU 提升至 0.68,相比 SAM2(0.15)与 DeepViT(0.17)大幅领先。
结构一致性:ARI 达到 0.60,远高于 SAM2 的 0.05。
用户研究:在「部件清晰度、跨视角一致性、动画适配性」三项指标上,SP4D 平均得分 4.26/5,显著优于 SAM2(1.96)和 DeepViT(1.85)2509.10687v1。

在 自动 rigging 任务中,SP4D 也展现出更强的潜力:
在 KinematicParts20K-test 上,SP4D 的 Rigging Precision 达到 72.7,相比 Magic Articulate(63.7)和 UniRig(64.3)有明显优势。
在用户评估的动画自然度上,SP4D 平均得分 4.1/5,远高于 Magic Articulate(2.7)与 UniRig(2.3),展现出对未见类别与复杂形态的更好泛化。
这些结果充分证明了 2D 先验驱动的思路 不仅能解决 kinematic part segmentation 的长期难题,还能有效延伸到自动 rigging,推动动画与 3D 资产生成的全自动化。

结语
Stable Part Diffusion 4D (SP4D) 不仅是技术上的突破,也是一次跨学科合作的成果,并且被 Neurips 2025 接受为 Spotlight。它展示了如何利用大规模 2D 先验打开 3D 运动学建模与自动 rigging 的新局面,为动画、游戏、AR/VR、机器人模拟等领域的自动化与智能化奠定了基础。


