工程

语音助手的「智商滑铁卢」:当GPT开口说话,准确率从74.8%跌到6.1%
想象这样一个场景:同一个 AI 模型,用文字交流时对答如流,一旦开口说话就变得磕磕巴巴、答非所问。 这不是假设中的场景,而是当下语音交互系统的真实写照。 杜克大学和 Adobe 最近发布的 VERA 研究,首次系统性地测量了语音模态对推理能力的影响。

多轮Agent训练遇到级联失效?熵控制强化学习来破局
作者团队介绍:本文来自罗格斯大学和 Adobe 团队的合作,一作徐武将罗格斯二年级博士,研究兴趣在 LLM Agent Memory 以及 Agent RL 方向上。 师从 Dimitris N. 在训练多轮 LLM Agent 时(如需要 30 步交互才能完成单个任务的场景),研究者遇到了一个严重的训练不稳定问题:标准的强化学习方法(PPO/GRPO)在稀疏奖励环境下表现出剧烈的熵值震荡,导致训练曲线几乎不收敛。

NeurIPS2025 | 攻破闭源多模态大模型:一种基于特征最优对齐的新型对抗攻击方法
近年来,多模态大语言模型(MLLMs)取得了令人瞩目的突破,在视觉理解、跨模态推理、图像描述等任务上表现出强大的能力。 然而,随着这些模型的广泛部署,其潜在的安全风险也逐渐引起关注。 研究表明,MLLMs 同样继承了视觉编码器对抗脆弱性的特征,容易受到对抗样本的欺骗。

南洋理工揭露AI「运行安全」的全线崩溃,简单伪装即可骗过所有模型
本文的第一作者雷京迪是南洋理工大学博士生,其研究聚焦于大语言模型,尤其关注模型推理、后训练与对齐等方向。 通讯作者 Soujanya Poria 为南洋理工大学电气与电子工程学院副教授。 论文的其他合作者来自 Walled AI Labs、新加坡资讯通信媒体发展局 (IMDA) 以及 Lambda Labs。

RAG、Search Agent不香了?苹果DeepMMSearch-R1杀入多模态搜索新战场
苹果最近真是「高产」! 这几天,苹果在多模态 web 搜索中发现了赋能多模态大语言模型(MLLM)的新解法。 在现实世界的应用中,MLLM 需要访问外部知识源,并对动态变化的现实世界信息进行实时响应,从而解决信息检索和知识密集型的用户查询。

欧几里得的礼物:通过几何代理任务增强视觉-语言模型中的空间感知和推理能力
本文共同第一作者为华中科技大学博士生连仕杰与华东师范大学博士生邬长倜,二者同时也是北京中关村学院2024级学生。 共同通讯作者包括:郑州大学学术副校长,郑州大学/华中科技大学教授,加拿大工程院/欧洲科学院院士杨天若教授;北京中关村学院&中关村人工智能研究院具身方向负责人陈凯。 近年来,多模态大语言模型(MLLMs)在广泛的视觉-语言任务中取得了显著成功。

递归语言模型登场!MIT华人新作爆火,扩展模型上下文便宜又简单
目前,所有主流 LLM 都有一个固定的上下文窗口(如 200k, 1M tokens)。 一旦输入超过这个限制,模型就无法处理。 即使在窗口内,当上下文变得非常长时,模型的性能也会急剧下降,这种现象被称为「上下文腐烂」(Context Rot):模型会「忘记」开头的信息,或者整体推理能力下降。

当Search Agent遇上不靠谱搜索结果,清华团队祭出自动化红队框架SafeSearch
该文第一作者是清华大学博士生董建硕,研究方向是大语言模型运行安全;该文通讯作者是清华大学邱寒副教授;其他合作者来自南洋理工大学和零一万物。 在 AI 发展的新阶段,大模型不再局限于静态知识,而是可以通过「Search Agent」的形式实时连接互联网。 搜索工具让模型突破了训练时间的限制,但它们返回的并非总是高质量的资料:一个低质量网页、一条虚假消息,甚至是暗藏诱导的提示,都可能在用户毫无察觉的情况下被模型「采纳」,进而生成带有风险的回答。

ICCV 2025 | 浙大、港中文等提出EgoAgent:第一人称感知-行动-预测一体化智能体
如何让 AI 像人类一样从对世界的观察和互动中自然地学会理解世界? 在今年的国际计算机视觉大会(ICCV 2025)上,来自浙江大学、香港中文大学、上海交通大学和上海人工智能实验室的研究人员联合提出了第一人称联合预测智能体 EgoAgent。 受人类认知学习机制和 “共同编码理论(Common Coding Theory)” 启发,EgoAgent 首次成功地让模型在统一的潜空间中同时学习视觉表征(Visual representation)、人体行动(Human action)和世界预测 (World state prediction)三大核心任务,打破了传统 AI 中 “感知”、“控制” 和 “预测” 分离的壁垒。

从掩码生成到「再掩码」训练:RemeDi让扩散语言模型学会自我纠正与反思
近期,扩散语言模型备受瞩目,提供了一种不同于自回归模型的文本生成解决方案。 为使模型能够在生成过程中持续修正与优化中间结果,西湖大学 MAPLE 实验室齐国君教授团队成功训练了具有「再掩码」能力的扩散语言模型(Remasking-enabled Diffusion Language Model, RemeDi 9B)。 在扩散去噪的多步过程中,通过进行再掩码 SFT 和 RL 训练,为每个 token 输出一个去掩码置信度,RemeDi 能够从序列中已经生成的内容中识别无法确定的位置进行再掩码(remask),从而修正错误内容并提升文本质量,在各方面都超越了现有的扩散语言模型。

不再靠「猜坐标」!颜水成团队等联合发布PaDT多模态大模型:实现真正的多模态表征输出
近年来,多模态大语言模型(Multimodal Large Language Models, MLLMs)在图文理解、视觉问答等任务上取得了令人瞩目的进展。 然而,当面对需要精细空间感知的任务 —— 比如目标检测、实例分割或指代表达理解时,现有模型却常常「力不从心」。 其根本原因在于:当前主流 MLLMs 仍依赖将视觉目标「翻译」成文本坐标(如 [x1, y1, x2, y2] )的方式进行输出。
首个多轮LLM Router问世, Router-R1可让大模型学会「思考–路由–聚合」
Haozhen Zhang 现为南洋理工大学(NTU)博士一年级学生,本工作完成于其在伊利诺伊大学厄巴纳-香槟分校(UIUC)实习期间。 Tao Feng 为 UIUC 博士二年级学生,Jiaxuan You 为 UIUC 计算机系助理教授。 团队长期聚焦 LLM Router 方向,已产出 GraphRouter、FusionFactory 及本文 Router-R1 等多项代表性研究成果。

ICCV 2025 | FDAM:告别模糊视界,源自电路理论的即插即用方法让视觉Transformer重获高清细节
针对视觉 Transformer(ViT)因其固有 “低通滤波” 特性导致深度网络中细节信息丢失的问题,我们提出了一种即插即用、受电路理论启发的 频率动态注意力调制(FDAM)模块。 它通过巧妙地 “反转” 注意力以生成高频补偿,并对特征频谱进行动态缩放,最终在几乎不增加计算成本的情况下,大幅提升了模型在分割、检测等密集预测任务上的性能,并取得了 SOTA 效果。 该工作来自北京理工大学、RIKEN AIP和东京大学的研究团队。

清华&巨人网络首创MoE多方言TTS框架,数据代码方法全开源
无论是中文的粤语、闽南话、吴语,还是欧洲的荷兰比尔茨语方言、法国奥克语,亦或是非洲和南美的地方语言,方言都承载着独特的音系与文化记忆,是人类语言多样性的重要组成部分。 然而,许多方言正在快速消失,语音技术如果不能覆盖这些语言,势必加剧数字鸿沟与文化失声。 在当今大模型引领的语音合成时代,通用 TTS 系统已展现出令人惊叹的能力,但方言 TTS 依然是相关从业者难以触及的「灰色地带」。
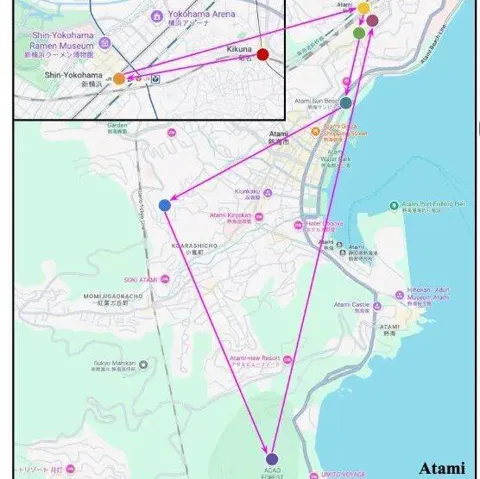
AI能否「圣地巡礼」?多模态大模型全新评估基准VIR-Bench来了
大家或许都有过这样的体验:看完一部喜欢的动漫,总会心血来潮地想去 “圣地巡礼”;刷到别人剪辑精美的旅行 vlog,也会忍不住收藏起来,想着哪天亲自走一遍同样的路线。 旅行与影像的结合,总是能勾起人们的探索欲望。 那么,如果 AI 能自动看懂这些旅行视频,帮你解析出 “去了哪些地方”“顺序是怎样的”,甚至还能一键生成属于你的旅行计划,会不会很有趣?

北大彭一杰教授课题组提出RiskPO,用风险度量优化重塑大模型后训练
该项目由北京大学彭一杰教授课题组完成,第一作者为任韬,其他作者包括江金阳、杨晖等。 研究背景与挑战:大模型后训练陷入「均值陷阱」,推理能力难破界当强化学习(RL)成为大模型后训练的核心工具,「带可验证奖励的强化学习(RLVR)」凭借客观的二元反馈(如解题对错),迅速成为提升推理能力的主流范式。 从数学解题到代码生成,RLVR 本应推动模型突破「已知答案采样」的局限,真正掌握深度推理逻辑 —— 但现实是,以 GRPO 为代表的主流方法正陷入「均值优化陷阱」。

NeurIPS 2025 Spotlight | 条件表征学习:一步对齐表征与准则
本文第一作者为四川大学博士研究生刘泓麟,邮箱为[email protected],通讯作者为四川大学李云帆博士后与四川大学彭玺教授。 一张图片包含的信息是多维的。 例如下面的图 1,我们至少可以得到三个层面的信息:主体是大象,数量有两头,环境是热带稀树草原(savanna)。

老牌Transformer杀手在ICLR悄然更新:Mamba-3三大改进趋近设计完全体
至今为止 Transformer 架构依然是 AI 模型的主流架构,自从其确立了统治地位后,号称 Transformer 杀手的各类改进工作就没有停止过。 在一众挑战者中最具影响力的自然是 2023 年社区爆火的基于结构化的状态空间序列模型(SSM)架构的 Mamba。 Mamba 的爆火可能和名字有关,但硬实力确实强大。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉