
开放词汇识别与分类对于全面理解现实世界的 3D 场景至关重要。目前,所有现有方法在训练或推理过程中都依赖于 2D 或文本模态。这凸显出缺乏能够单独处理 3D 数据以进行端到端语义学习的模型,以及训练此类模型所需的数据。与此同时,3DGS 已成为各种视觉任务中 3D 场景表达的重要标准之一。
然而,有效地将语义理解以可泛化的方式集成到 3DGS 中仍然是一个难题。为了突破这些瓶颈,我们引入了 SceneSplat,第一个在 3DGS 上原生运行的端到端大规模 3D 室内场景理解方法。此外,我们提出了一种自监督学习方案,可以从未标记场景中解锁丰富的 3D 特征学习。为了支持所提出的方法,我们采集了首个针对室内场景的大规模 3DGS 数据集 SceneSplat-7K,包含 7916 个场景,这些场景源自七个现有数据集,例如 ScanNet 和 Matterport3D。生成 SceneSplat-7K 所需的计算资源相当于在 L4 GPU 上运行 150 天。我们在 SceneSplat-7K 上进行了开放词汇和语义分割的测试,均达到了 state-of-the-art 的效果。

文章链接:https://arxiv.org/abs/2503.18052
项目主页:https://unique1i.github.io/SceneSplat_webpage/
数据集:https://huggingface.co/datasets/GaussianWorld/scene_splat_7k
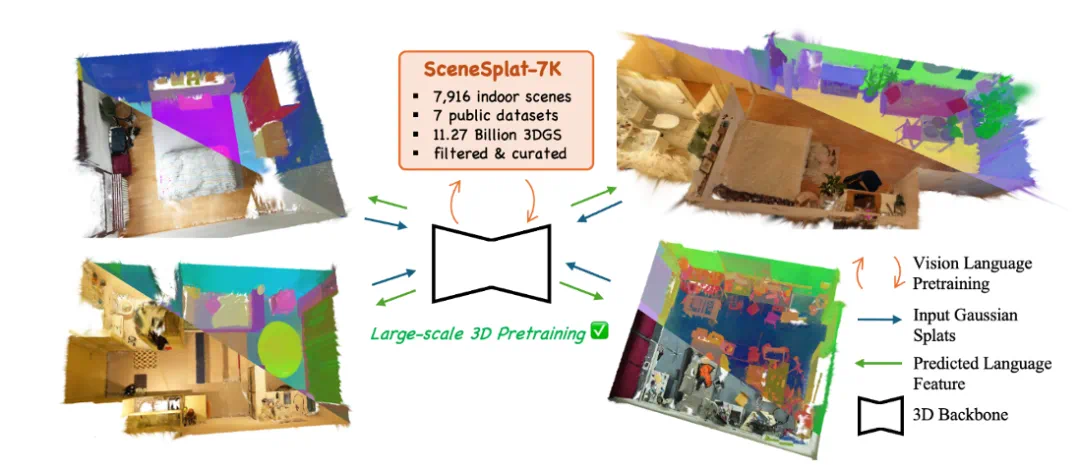
图 1: SceneSplat-7K 从 7 个不同的公开数据集采集了了 7916 个完整 3DGS 场景,并且做了语义标注;基于这一高质量数据集,我们大规模训练了 SceneSplat 模型,这是首个能够在单次前向传播中预测数百万个 3D 高斯分布的开放词汇语言特征的模型。
视频:SceneSplat
SceneSplat 数据集
大规模 3DGS 重建
为支撑在 3D 高斯点(3DGS)上的原生语义学习,我们构建并发布 SceneSplat-7K。数据来源覆盖 7 个权威室内数据集:ARKitScenes、Replica、ScanNet、ScanNet++(含 v2)、Hypersim、3RScan、Matterport3D,统一转化为 3DGS 表示,形成跨真实与合成场景的多样化数据集。
SceneSplat-7K 包含 7,916 个处理后的 3DGS 场景、总计 112.7 亿个高斯点,单场景均值约 142 万;对应 472 万张 RGB 训练帧。整体重建质量达到 PSNR 29.64 dB、平均 Depth-L1 0.035 m,在保持高保真外观的同时兼顾几何准确性。该数据集的构建开销等效 NVIDIA L4 150 个 GPU-days。具体信息如下表所示。
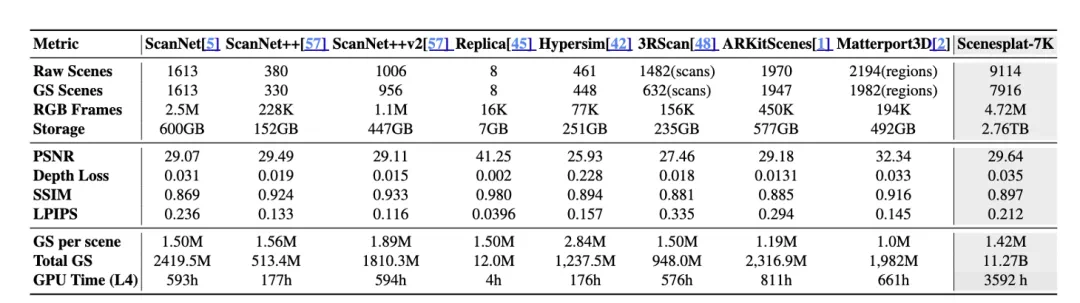
表 1:数据集数据。
开放词汇语义标注
我们使用了一套稳定、快速的系统来标注 3DGS 的语义信息。首先用 SAMv2 做物体级分割、SigLIP2 提取视觉 - 语言特征,再借助 Occam’s LGS 将多视角 2D 特征高效 “抬升” 到 3DGS 上,得到稳定的高斯 - 语言特征对,为后续预训练提供监督;预训练的编码器仅依赖 3DGS 参数与邻域信息,即可学习到丰富的语义表示,无需在推理时再做 2D 融合。

SceneSplat 预训练
在得到大规模带标注的 3DGS 数据集后,我们希望训练一个高参数量的 Transformer 编码器来预训练 3DGS 数据。根据数据的不同特征,我们提供了两个不同的训练路线。在有语义标注的情况下,我们进行了视觉 - 语言预训练,使得网络可以直接输出与 CLIP/SigLip 对齐的特征,便于进行开放词汇测试;对于没有语义标注的数据,我们直接根据原有 3DGS 参数进行自监督训练,释放无标注场景的学习潜力。
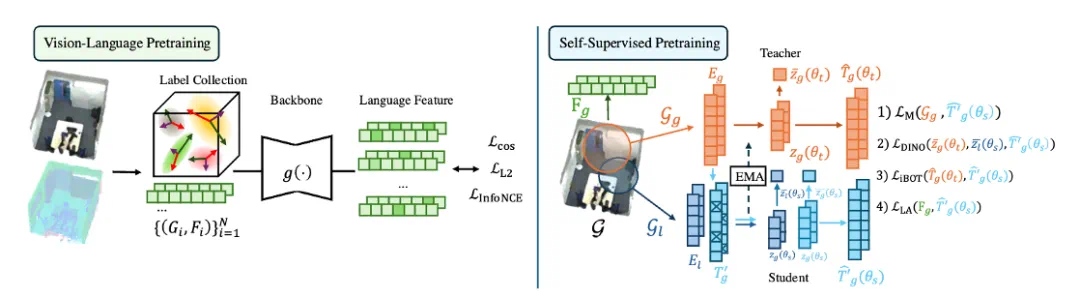
图 2. SceneSplat 同时支持视觉 - 语言预训练与自监督预训练。
视觉 - 语言预训练
我们采用分层 Transformer 编解码器:以高斯为 token,结合 kNN 半径构图形成邻域注意力;解码回归维度为 d 的语义向量。训练目标由两部分损失函数组成:
损失函数:对每个高斯的预测嵌入 z_i 与监督嵌入 z ̂_i 同时施加余弦损失与 L2 损失,稳定对齐方向与尺度;
对比学习(后期启用):在训练后段加入 InfoNCE,并对同类高斯进行类内聚合(prototype pooling)后再对比,强化类间可分性。在训练后期加入可以显著避免早起损失函数震荡过高的问题。
推理与后处理。给定文本查询 t 的向量 y_t,与每个高斯嵌入做余弦相似度匹配即可得到正确的 query;考虑测试点集与高斯中心不完全重合,使用 kNN 投票(默认 k 为几十)在空间上聚合,得到正确的推理。
GaussianSSL:自监督训练
实际上,绝大多数 3D 重建的场景没有语义标注,借用 2D foundation model 来进行标注也十分昂贵。我们提出另一种自监督训练方法来得到可泛化的 3DGS 表征。
1. Masked Gaussian Modeling(MGM)
对 3DGS 随机高比例掩码,仅向模型提供可见子集与拓扑邻域信息;解码器重建被掩的核心参数(如中心、尺度、旋转、颜色、不透明度等)。不同量纲采用分量归一化与多任务加权(L1/L2 结合),鼓励网络同时理解几何与外观,并学习到对噪声与稀疏采样鲁棒的局部结构先验。
2. Self-Distillation Learning(自蒸馏)
采用教师 - 学生框架与多种 3D 数据增广(旋转、尺度抖动、点扰动、随机子采样)。在全局表征与局部 token 两级施加一致性损失(余弦 / 分布对齐),并配合轻量正则化(如避免坍塌的熵 / 编码率约束),获得对增广不变的判别性特征。教师以动量更新,稳定训练并提升大规模数据上的收敛性。
3. Language–Gaussian Alignment(可选)
当场景具备 VL 标签时,引入轻量语言对齐作为辅助头:先将高维 VLM 嵌入通过自编码器 / 线性头降维,再仅对 Mask 区域施加低维对齐损失,使 MGM 的结构重建与语义对齐协同而非相互干扰。该分支可按数据可得性按需启用,确保无标注与弱标注数据都能纳入统一训练。
实验结果
定量实验
如表 2 所示,我们的方法在 ScanNet200、ScanNetpp 和 Matterport3D 的零样本语义分割上面都达到了 SOTA 的效果。
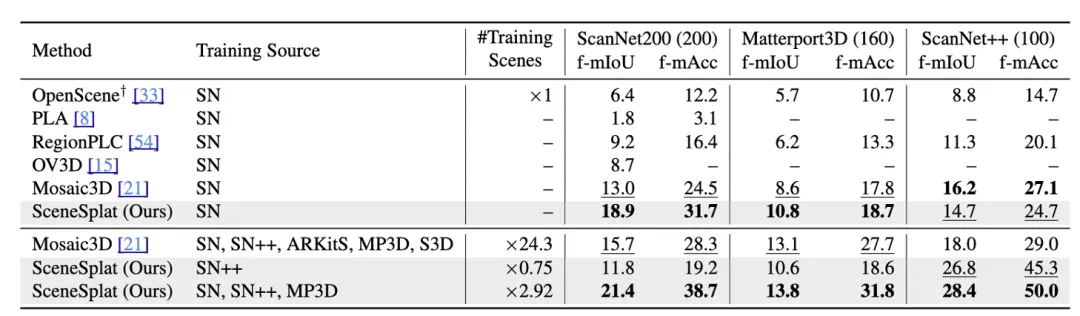
表 2:零样本 3D 语义分割
在无监督预训练后,我们测试了 GaussianSSL 的语义分割效果,结果如表 3 所示,在 ScanNet 和 ScanNetpp 数据集中均达到了 SOTA 的效果。
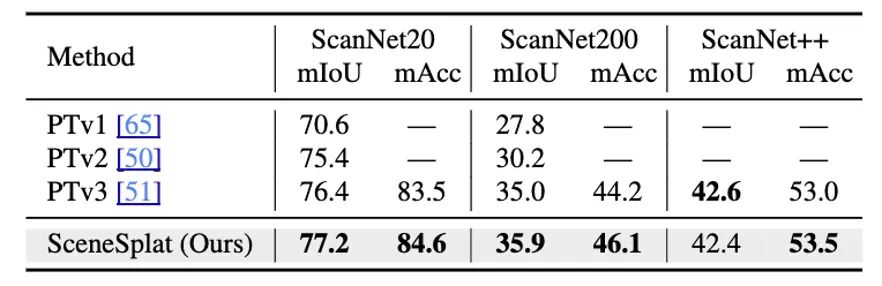
表 3: 语义分割结果
定性实验
在做可视化的时候,我们发现了很多很有趣的结果,如图 3 所示,本身的 3D 语义标注会将相同的桌子打上不同的标签,但是经过训练后,我们的模型可以很干净的分割出来完整的桌子。
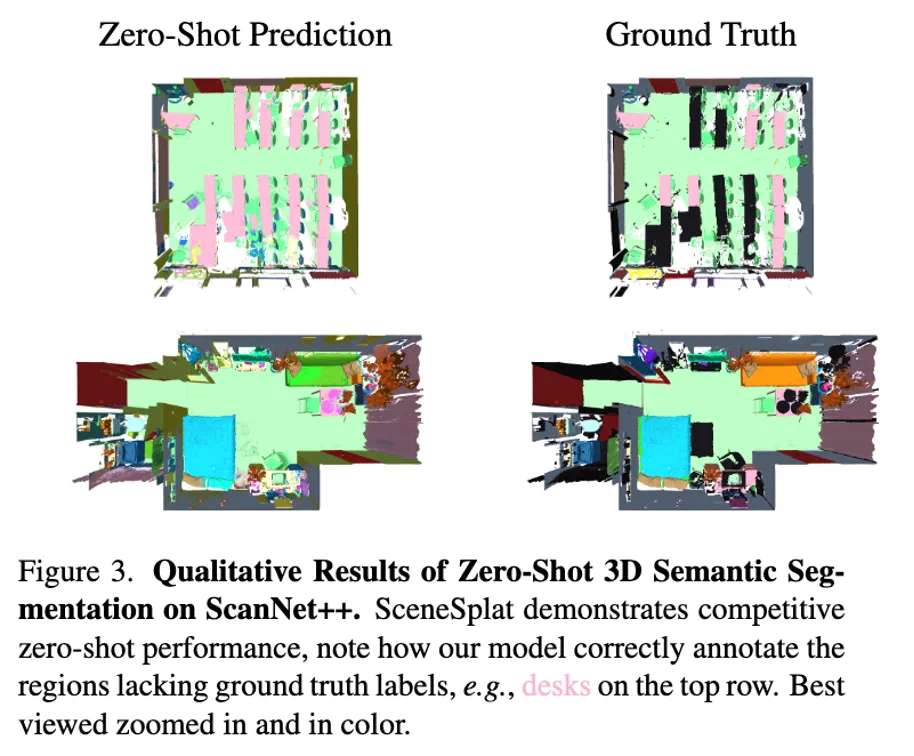
图 3. 在 ScanNetpp 上的零样本预测可视化。
在图 4 中,我们展示了模型零样本 Query 的能力,一些类别,比如 Robot Arm 是在原数据集中不存在的,但是经过 SceneSplat 预训练后,我们可以很好的识别 Out of Distribution 的物体。图 5 中我们测试了物体属性 query,证明了我们的模型也能很好的 model attribute。更多的实验结果请参考我们原文。

图 4. 文本 query 结果。

图 5(左):“Vacation” --> “Travel Guide”,(右):“Art”-->“Painting”。
后期工作
我们继续将 SceneSplat-7K 数据集拓展成了 SceneSplat-49K,并且在多个 dataset 上进行了系统的 3DGS 和语义结合的工作的 benchmarking,欢迎大家继续关注 SceneSplat++ :https://arxiv.org/abs/2506.08710。
主要作者简介:
李跃,阿姆斯特丹大学博士二年级学生,分别于苏黎世联邦理工学院和上海交通大学获得硕士和学士学位,主要研究方向为在线稠密重建和 3D 场景理解。
马麒,苏黎世联邦理工 INSAIT 共同培养博士二年级学生,本科毕业于上海交通大学和硕士毕业于苏黎世联邦理工,主要研究方向是 3D 重建和理解方向,目前在 ICCV, CVPR, Neurips 等国际会议发表多篇论文。
杨润一,INSAIT 博士生,导师为 Dr. Danda Paudel 和 Prof. Luc Van Gool,硕士毕业于帝国理工学院 MRes AIML,本科毕业于北京理工大学自动化专业。曾在索尼 Pixomondo Innovation Lab 担任研究员。主要研究方向为三维重建、场景理解和生成。CICAI 2023 获得 Best Paper Runner-up 奖项。
马梦姣,INSAIT 计算机科学与人工智能研究所博士生,学士毕业于南京航空航天大学,主要研究兴趣为三维场景理解。
任斌,比萨大学和特伦托大学联合培养 “意大利国家 AI 博士” 项目博士生,INSAIT 和苏黎世联邦理工访问学者,此前分别于北京大学和中南大学获得硕士和学士学位。主要研究方向为表征学习,场景理解,以及多模态推理。
Luc Van Gool 教授是计算机视觉与人工智能领域的国际顶尖学者,现任 INSAIT 全职教授,曾任苏黎世联邦理工学院(ETH Zurich)和比利时鲁汶大学(KU Leuven)教授,同时领导多个跨学科研究团队。他的研究涵盖三维视觉、物体与场景识别、生成建模以及智能系统等方向,发表了数百篇在 CVPR、ICCV、ECCV、NeurIPS 等顶级会议和期刊上的论文,共计 25 万 + 引用,H-index 207。
INSAIT 简介:
INSAIT(Institute for Computer Science, Artificial Intelligence and Technology)成立于 2022 年、坐落保加利亚索菲亚,面向计算机科学与人工智能的前沿基础与系统研究,方向覆盖计算机视觉、机器人、自然语言处理、安全与可信 AI、量子计算、算法与理论及信息安全;与 ETH Zürich、EPFL 建立战略合作,师资与博士后来自 ETH、EPFL、CMU、MIT 等顶尖院校。研究院与 Google、华为、AWS、Toyota、vivo 等开展产学协同,并参与欧盟 “AI 工厂” 计划(总额 €90M)。近年学术产出亮眼:ICCV’25 接收 13 篇、CVPR’25 接收 7 篇、CVPR’24 接收 16 篇,获 FOCS’24 最佳论文。INSAIT 长期招募 Faculty、PostDoc、PhD 与 RA(可 host 硕士毕设),提供具竞争力的资助与支持,并提供往返机票与住宿,科研环境开放、高效、国际化。欢迎私信了解更多情况~
近期招生信息:
博士研究生招生信息 | INSAIT & Google 联合项目
我们正在招收多名博士研究生,研究方向为:基于多模态模型的 Egocentric(第一人称)视频理解。
本项目由 INSAIT 与 Google 联合支持,为有志于在人工智能与计算机视觉前沿领域深造的同学提供优越的研究环境与资源支持。
📌 申请方式
请通过 INSAIT PhD 招生页面 https://insait.ai/phd/ 提交申请,并注明 【INSAIT-Google-Egocentric】;
如有相关问题,可邮件联系 [email protected]。
我们热忱欢迎对 Egocentric 视频理解与多模态 AI 充满兴趣的同学加入!


