打开手机,让 AI Agent 自动帮你完成订外卖、订酒店、网上购物的琐碎任务,这正成为智能手机交互的新范式。
一个能自主处理大部分日常任务的个人专属智能体,正在从科幻走进现实。
然而,通往 “解放双手” 的最后一公里却并不好走。如何高效地训练和在手机端部署 Agent 模型,长期以来似乎都是少数大厂的 “自留地”。从高质量操作数据的获取,到模型的训练与适配,再到移动端 APP 的优化,重重门槛将绝大多数开发者和普通用户挡在门外,也极大地限制了移动端 Agent 的生态发展。
就在刚刚,这一局面迎来了新的破局者。
来自上海交通大学 IPADS 实验室的团队,正式开源了一套名为 MobiAgent 的移动端智能体 “全家桶”。

论文地址: https://arxiv.org/abs/2509.00531
AgentRR 论文:https://arxiv.org/abs/2505.17716
项目仓库: https://github.com/IPADS-SAI/MobiAgent
模型:https://huggingface.co/IPADS-SAI/collections
APP:https://github.com/IPADS-SAI/MobiAgent/releases/download/v1.0/Mobiagent.apk
这套框架,首次将从 0 到 1 构建手机 Agent 的全流程完整地向所有用户开放。这意味着,从收集手机操作轨迹数据开始,到训练出一个能听懂自然语言指令、帮你处理日常事务的专属 Agent,再到最终将它部署在自己的手机上,现在,人人都能上手 DIY。
当然,光能 “炼” 还不够,性能必须能打。为了验证 MobiAgent 的真实能力,研究团队直接在国内 Top 20 的 App 上进行了实测。结果显示,7B 规模的 MobiAgent 模型,在任务平均完成分上,不仅超越了 GPT-5、Gemini 2.5 Pro 等一众顶级闭源大模型,也优于目前最强的同规模开源 GUI Agent 模型。
除了 Agent 能力之外,团队还为 Agent 设计了一个独特的 “潜记忆加速器”。面对点外卖、查地图这类高频重复操作,MobiAgent 能够 “举一反三”,通过学习历史操作来简化决策,靠 “肌肉记忆” 完成 Agent 任务,最终将端到端的任务性能提升了 2-3 倍。这样一套集 “数据捕获、模型训练、推理加速、自动评测” 于一体的四位一体框架,可以说,彻底打通了移动智能体从开发到落地的 “最后一公里”。
这,或许才是普通人真正想要的 Agent。那么,MobiAgent 究竟是如何做到的?
Agent 养成全攻略:三步走
要让 AI 学会玩手机,首先得让它看懂人是怎么操作的。MobiAgent 的第一大核心,就是贡献了一套 AI 辅助的敏捷数据收集 “流水线”。
过去,给 AI 准备 “教材”(标注数据)又贵又慢。现在,MobiAgent 用一个轻量级小工具,就能记录下人类在手机上的所有点击、滑动、输入等操作轨迹。对于一些简单的任务,这一录制过程甚至可以完全交给大模型完成,进一步提高了数据收集的效率。
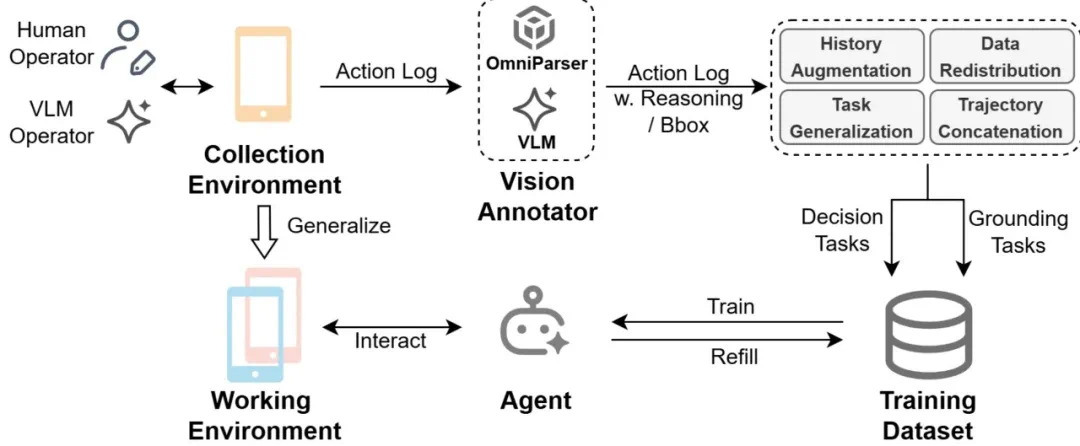
MobiAgent数据收集与自进化流程
但只有操作还不够,AI 得理解 “为什么” 这么做。于是,团队使用通用的 VLM 模型(例如 gemini-2.5-pro),让它对着操作记录,“脑补” 出每一步的思考过程和逻辑,自动生成高质量的 “带思路” 的训练数据。最后,也是最重要的一步,这些数据会经过一个自动化 “精炼流水线”,调整数据的难易平衡比例、输入任务描述、历史信息长度等等,让训练出的 Agent 模型具有更强的泛化能力。
有了高质量的教材,下一步就是训练。MobiAgent 的 "大脑"MobiMind,被设计成了一个分工明确的 “三人小组”:
Planner(规划师): 负责理解复杂任务,进行拆解。
Decider(决策者): 看着当前手机屏幕,决定下一步干啥。
Grounder(执行者): 负责把 “点搜索按钮” 这种指令,精准定位到屏幕上的坐标并点击。
这种 “各司其职” 的架构,让模型训练起来更高效,能力也更强。
让 Agent 拥有 “肌肉记忆”,速度飙升 3 倍
光聪明还不够,反应慢也是硬伤。你肯定不想让 Agent 帮你买杯咖啡,结果思考了半分钟。为此,MobiAgent 团队祭出了第二个大杀器:AgentRR(Agent Record&Replay)加速框架。这个框架的核心思想,就跟我们人类的 “肌肉记忆” 一样:对于重复做过的事,直接凭经验搞定,不用再过一遍大脑。
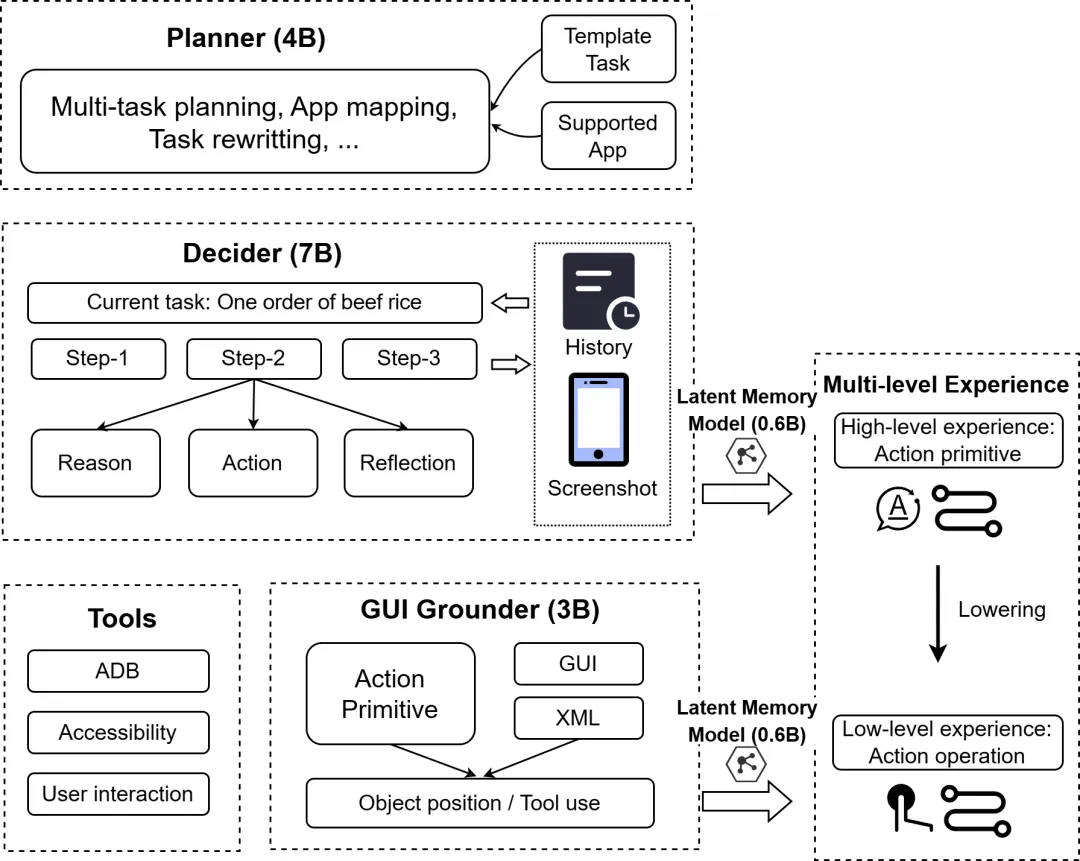
AgentRR系统架构
AgentRR 会把智能体执行过的任务轨迹,通过树的形式记录在一个叫 ActTree 的结构里。当接到一个新任务时,一个超轻量的 “潜意识”(Latent Memory Model)会迅速判断:
这个任务我是不是做过类似的?前几步是不是可以照搬?
比如,无论是 “搜附近的火锅店” 还是 “搜附近的电影院”,点开地图 App、点搜索框这两步都是完全一样的。AgentRR 就能直接 “复用” 这段操作,跳过大模型的思考过程,从而大幅提升效率。效果有多好?在模拟真实用户使用习惯(80% 请求集中在 20% 任务)的测试中,动作复用率高达 60%-85%。反映在实际任务上,就是 2 到 3 倍的性能提升。
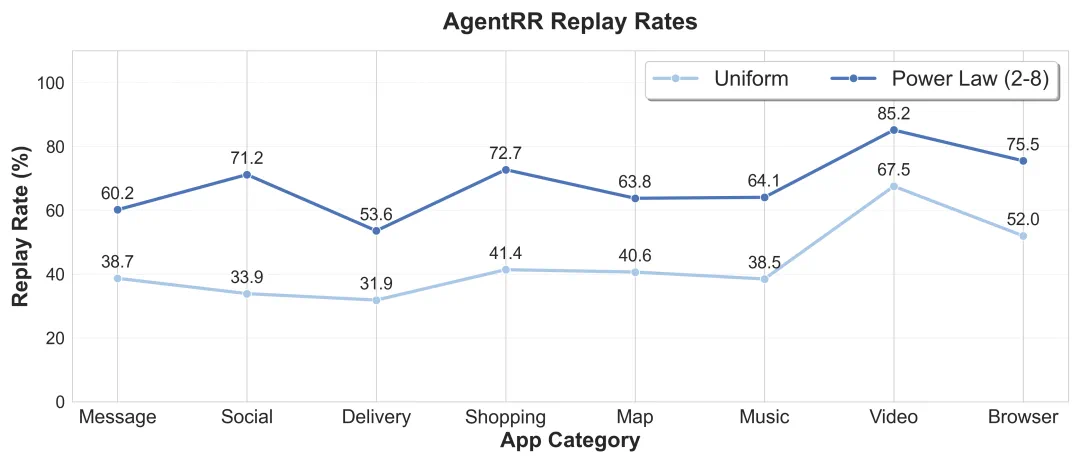
不同请求分布下,AgentRR 的动作复用率
真实场景大比拼:谁是 「手机操作之王」?
是骡子是马,拉出来遛遛。为了公平地评判各大模型的真实能力,团队还专门打造一个更贴近现实的移动端智能体评测基准:MobiFlow。这个基准会基于任务的一个个关键节点,也就是 “里程碑”,对在动态 GUI 环境中执行任务的 Agent 进行精确打分,避免了 “不是满分,就是零分” 的单一评判标准,并且覆盖了社交、影音、购物、旅行、外卖等多个领域的国产主流 App。
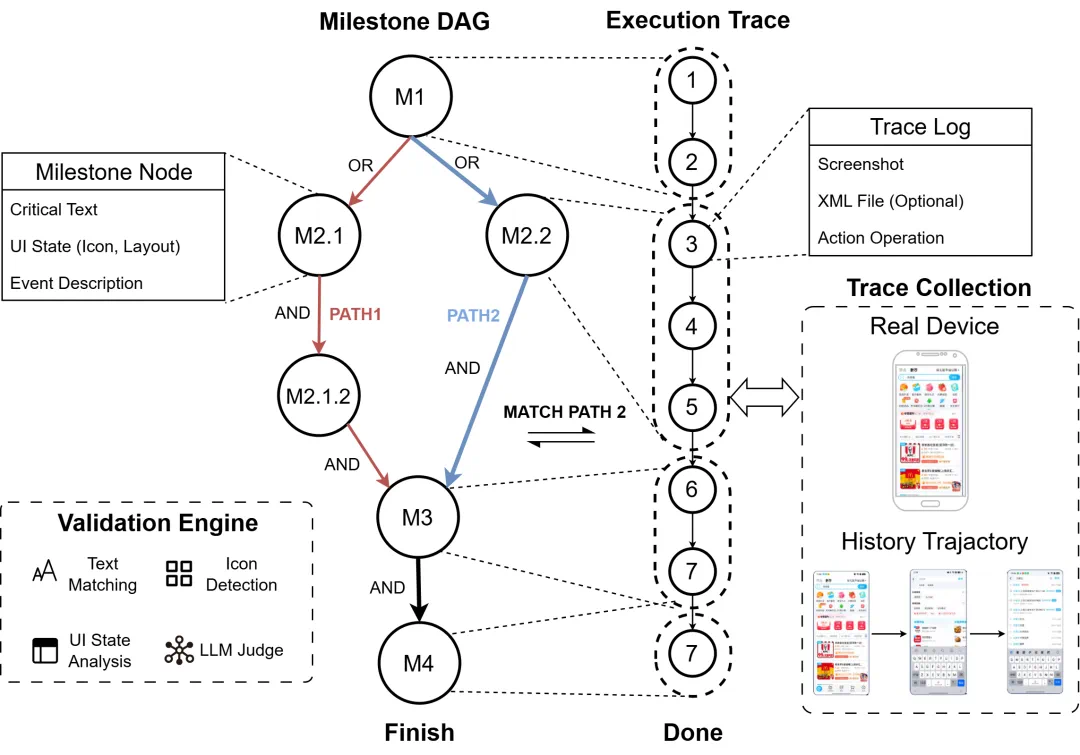
MobiFlow智能体评测基准
最终的评测结果,MobiAgent(MobiMind-Decider-7B + MobiMind-Grounder-3B 的组合)在绝大多数 App 上都取得了最高分,尤其是在购物、外卖这类复杂任务上,优势非常明显。相比之下,像 GPT 和 Gemini 这样的大模型,虽然也能完成一些任务,但有时会 “走捷径”,比如把所有要求一股脑全塞进搜索框,依赖 App 自身的 AI 搜索能力。这种 “偷懒” 的做法一旦遇到不支持 AI 搜索的 App,完成率就大幅下降。更重要的是,MobiAgent 在所有测试中都能正确终止任务,而 GPT-5 在 11 个 App 上都出现了 “无限循环” 卡住的问题。
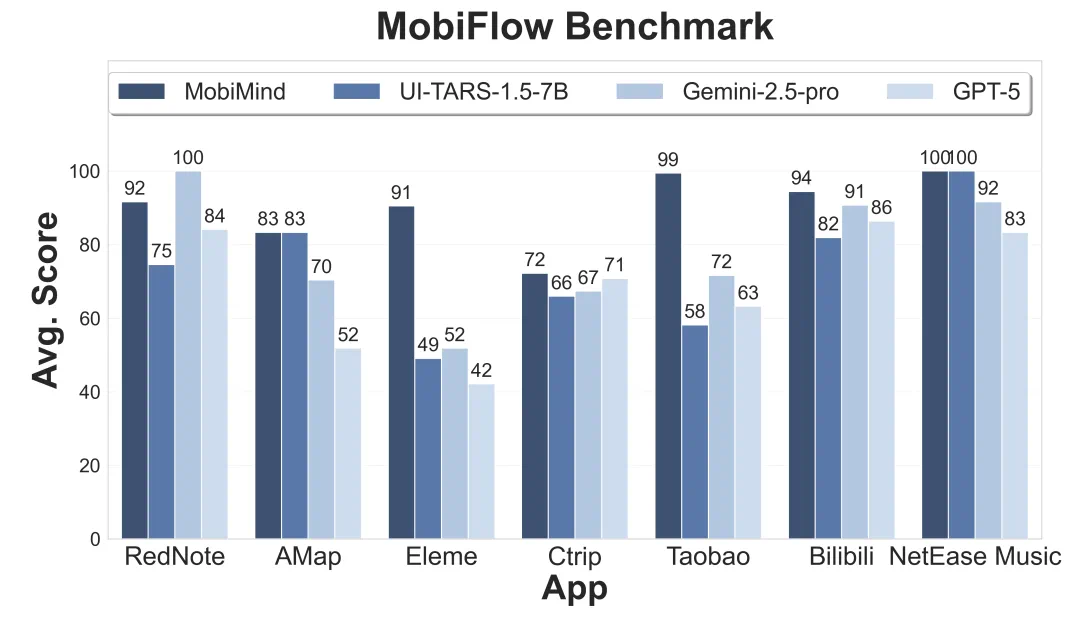
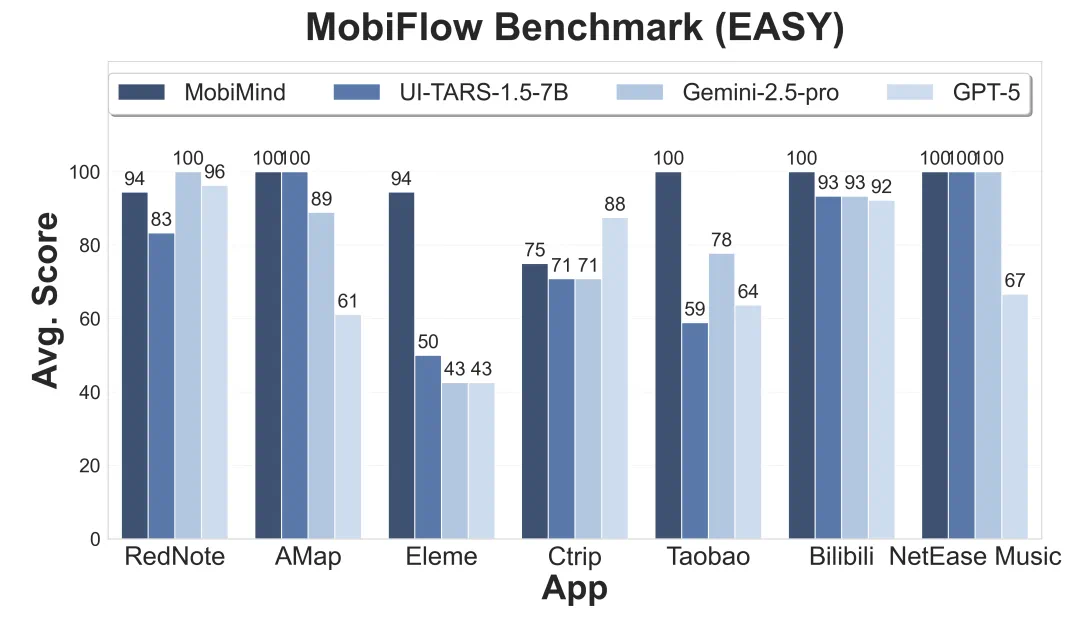
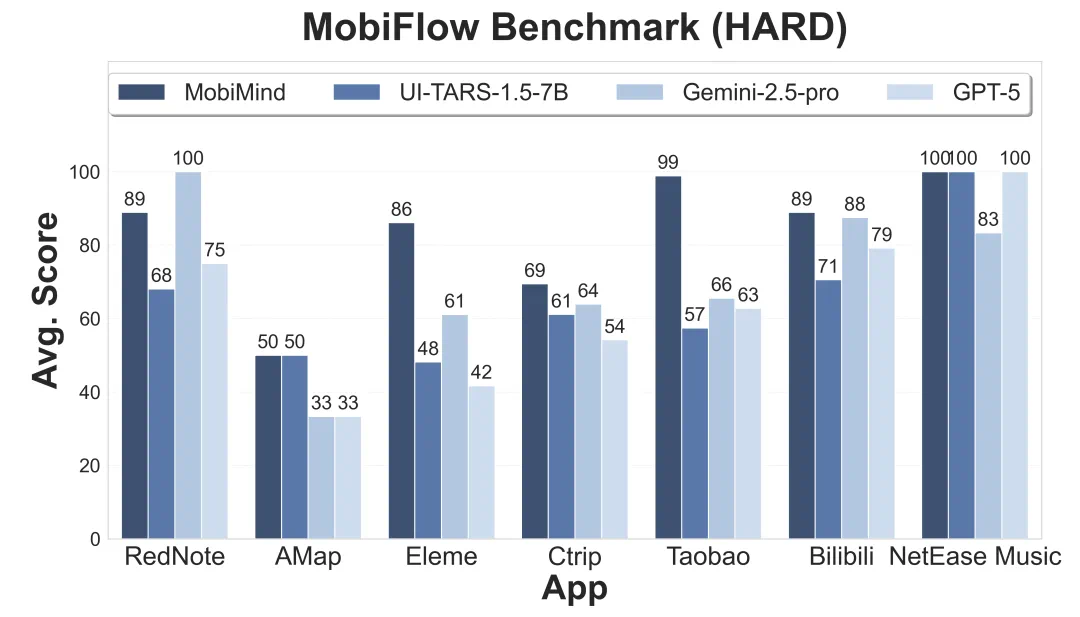
总结
MobiAgent 的出现,不仅在性能上树立了新的标杆,更重要的是,它通过开源整个技术栈,极大地降低了定制化、私有化移动智能体的门槛。从日常应用的 Agent 开发,到每个人的个性化专属助理,想象空间被彻底打开。
或许,那个 “能动口就不动手” 的智能移动时代,就快到来了。
项目成员介绍
MobiAgent核心开发团队主要由上海交通大学IPADS实验室(并行与分布式系统研究所)的端侧智能体研究小组的本科生和硕士生,以及John班的实习生组成。主要指导教师为上海交通大学人工智能学院助理教授冯二虎。