
在大模型推理能力提升的探索中,工具使用一直是克服语言模型计算局限性的关键路径。不过,当今的大模型在使用工具方面还存在一些局限,比如预先确定了工具的使用模式、限制了对最优策略的探索、实现透明度不足等。
为了解决这些难题,来自上海交通大学、SII 和 GAIR 的研究团队提出了一种全新框架 ToRL(Tool-Integrated Reinforcement Learning),该方法允许模型直接从基座模型开始,通过强化学习自主探索最优工具使用策略,而非受限于预定义的工具使用模式。

论文标题:ToRL: Scaling Tool-Integrated RL
论文地址:https://arxiv.org/pdf/2503.23383
代码地址:https://github.com/GAIR-NLP/ToRL
数据集地址:https://github.com/GAIR-NLP/ToRL/tree/main/data/torl_data
模型地址:https://huggingface.co/GAIR/ToRL-7B
实验表明,这种方法在数学推理任务上取得了显著突破:ToRL-7B 在 AIME24 上达到了 43.3% 的准确率,比不使用工具的基线 RL 模型提高了 14%,比现有的工具集成大模型提高了 17%。
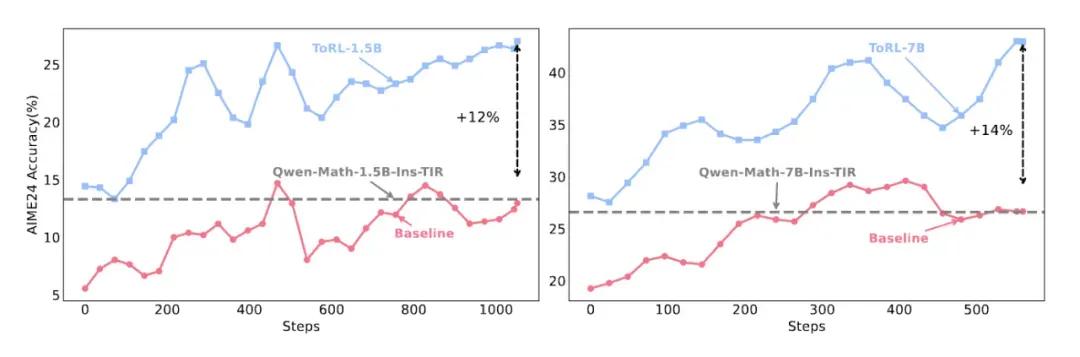
图 1: ToRL 在 AIME24 等基准中的性能对比,优于基线和现有 TIR 系统
一、为什么要直接从基座模型扩展工具集成强化学习?
在传统工具集成推理(TIR)领域,研究者们长期遵循着一条看似不可撼动的铁律:必须先通过监督微调(SFT)教会模型使用工具,才能进行强化学习优化。这种 "先 SFT 再 RL" 的范式,就像给 AI 套上预设的思维枷锁,虽然能获得稳定的性能提升,却可能永远无法发现最优的工具使用策略。
正当大家沿着这条既定路线堆砌数据和算力时,该研究团队却大胆提出了一个假设:如果让模型完全自主探索工具使用方式,会怎样?他们开发的 ToRL 框架就像打开了一扇全新的大门 —— 直接从基座模型出发,单纯通过扩展强化学习让 AI 自主掌握工具使用的精髓。
实验结果令人惊喜:ToRL 不仅打破了传统 TIR 方法的性能天花板,更让模型自发涌现出三大重要能力:
像人类专家般的工具选择直觉
自我修正无效代码的元能力
动态切换计算与推理的解题智慧
这些能力完全由奖励信号驱动自然形成,没有任何人为预设的痕迹。
这不禁让人思考:ToRL 证明了大模型可能早已具备强大的工具使用能力,只是需要更开放的学习方式去释放。当主流研究还在为数据规模和算法复杂度较劲时,ToRL 用事实告诉我们:有时候,少一些人为干预,反而能收获更多意外之喜。

图 2: ToRL 使用自然语言和代码工具交叉验证,并在发现不一致后进一步使用使用工具验证
二、技术解析:ToRL 如何赋予模型自主工具能力
工具集成推理 (TIR) 的基本框架
工具集成推理 (TIR) 使大语言模型能够通过编写代码,利用外部工具执行计算,并基于执行结果迭代生成推理过程。这一过程可以用简单的语言描述为:
当语言模型面对一个问题时,TIR 允许模型构建一个包含多个步骤的推理轨迹。在每一步中,模型首先用自然语言进行推理,然后生成相关代码,接着获取代码的执行结果,并将这三部分内容组合起来形成完整的推理过程。随着推理的深入,模型会不断参考之前的推理内容、代码及其执行结果,进一步调整自己的思路。
ToRL: 直接从基座模型的强化学习
ToRL 框架将 TIR 与直接从基座语言模型开始的强化学习相结合,而不需要先进行监督微调。这使得模型能够自主发现有效的工具使用策略。
在模型的推理过程中,当检测到代码终止标识符 (```output) 时,系统会暂停文本生成,提取最新的代码块执行,并将结构化执行结果插入上下文中。系统会继续生成后续的自然语言推理,直到模型提供最终答案或生成新的代码块。
设计选择与考量:
工具调用频率控制:为了平衡训练效率,引入超参数 C,表示每次响应生成允许的最大工具调用次数;
执行环境选择:选择稳定、准确和响应迅速的代码解释器实现;
错误消息处理:提取关键错误信息,减少上下文长度;
沙盒输出掩码:在损失计算中掩盖沙盒环境的输出,提高训练稳定性。
奖励设计:实现了基于规则的奖励函数,正确答案获得 + 1 奖励,错误答案获得 - 1 奖励。此外,研究还尝试探究了基于执行的惩罚:含有不可执行代码的响应会导致 - 0.5 的奖励减少。在默认实验设置中,仅使用了答案正确性的 reward。
三、实验验证:ToRL 的性能优势
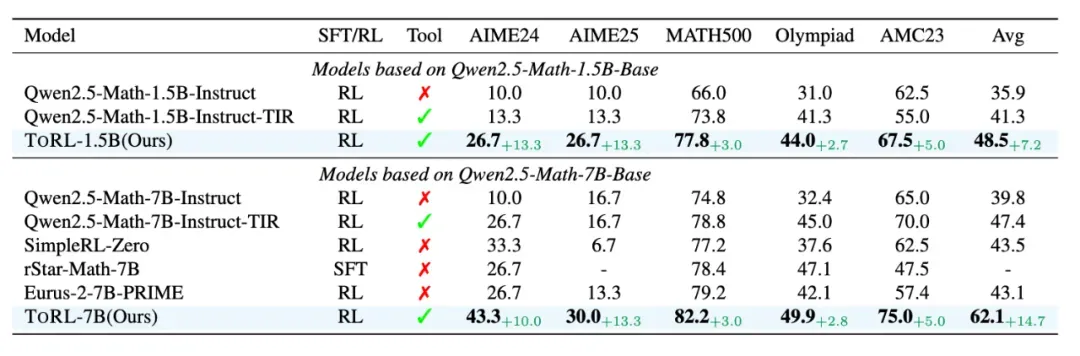
图 3: ToRL 在数学基准测试上的准确率比较
实验结果表明,ToRL 在所有测试基准上的表现始终优于基线模型。对于 1.5B 参数模型,ToRL-1.5B 的平均准确率达到了 48.5%,超过了 Qwen2.5-Math-1.5B-Instruct (35.9%) 和 Qwen2.5-Math-1.5B-Instruct-TIR (41.3%)。在 7B 参数模型中,性能提升更加显著,ToRL-7B 达到了 62.1% 的平均准确率,比具有相同基础模型的其他开源模型高出 14.7%。
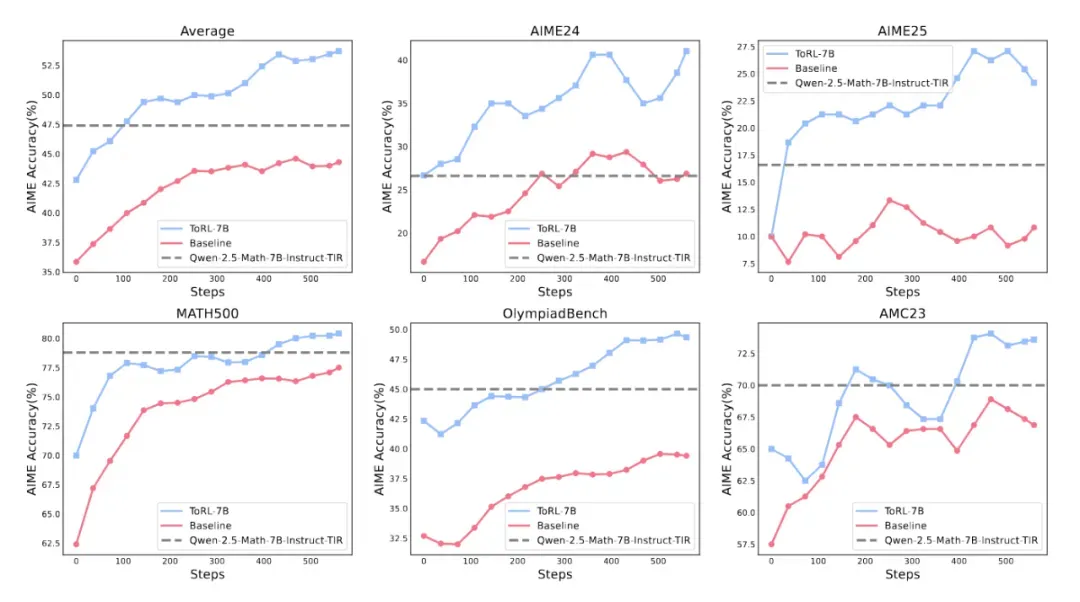
图 4: ToRL 在数学基准测试上的训练动态
图 4 展示了在五个不同数学基准上的训练动态。ToRL-7B 在训练步骤中显示出持续改进,并保持明显优势。这种性能差距在具有挑战性的基准上尤为显著,如 AIME24 (43.3%)、AIME25 (30.0%) 和 OlympiadBench (49.9%)。
四、行为探索:模型使用工具的认知模式
训练中的工具使用进化

图 5: 训练步数增加时,ToRL 的代码使用率与有效性变化
图 5 提供了训练过程中工具使用模式的深入洞察:
代码比率:模型生成的包含代码的响应比例在前 100 步内从 40% 增加到 80%,展示了整个训练过程中的稳定提升
通过率:成功执行的代码比例呈现持续上升趋势,反映了模型增强的编码能力
正确 / 错误响应的通过率:揭示了代码执行错误与最终答案准确性之间的相关性,正确响应表现出更高的代码通过率
有效代码比率:检查有效代码比例的变化,包括成功执行的代码和在模型提供最终答案前生成的代码,两者都随着训练时间增加而提高
关键发现:随着训练步骤的增加,模型解决问题使用代码的比例以及可以正确执行的代码比例持续增长。同时,模型能够识别并减少无效代码的生成。
关键参数设置的影响
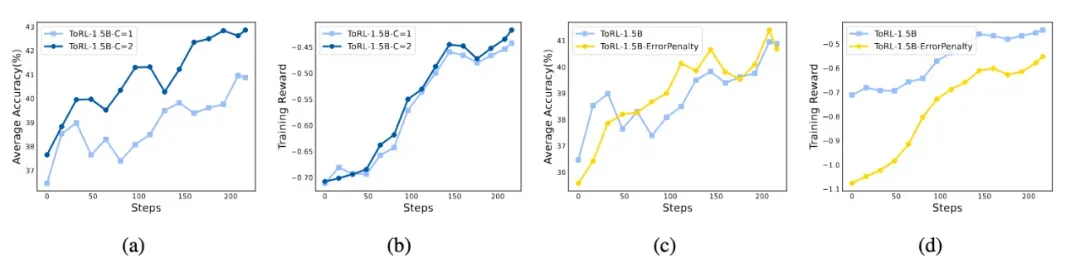
图 6: 探索相应最大次数(左 2 图)和可执行(右 2 图)对模型性能的影响
研究团队探索了关键 ToRL 设置对最终性能和行为的影响:
首先,实验探究了增加 C(单次响应生成中可调用的最大工具数)的影响。将 C 从 1 增加到 2 显著提高了性能,平均准确率提高约 2%。然而,增加 C 会大幅降低训练速度,需要在性能和效率之间进行权衡。
此外,分析了将代码可执行性奖励纳入奖励塑造的影响。结果表明,这种奖励设计并未提高模型性能。研究团队推测,对执行错误进行惩罚可能会激励模型生成过于简单的代码以最小化错误,从而可能阻碍其正确解决问题的能力。
通过强化学习扩展涌现的认知行为
模型训练后期出现了一些有趣的现象,这些现象帮助我们深入理解模型使用工具解决问题的认知行为。
例如,模型能够根据代码解释器的执行反馈调整其推理。在一个案例中,模型首先编写了代码,但由于不当处理导致索引错误。在收到 "TypeError: 'int' object is not subscriptable" 的反馈后,它迅速调整并生成了可执行代码,最终推断出正确答案。

图 7: 案例 1-ToRL 通过执行器报错反馈重新构建推理代码
另一个案例展示了模型的反思认知行为。模型最初通过自然语言推理解决问题,然后通过工具进行验证,但发现不一致。因此,模型进一步进行修正,最终生成正确答案。

图 8: 案例 2-ToRL 使用代码工具验证修正推理结果
关键发现:ToRL 产生了多种认知行为,包括从代码执行结果获取反馈,以及通过代码和自然语言进行交叉检查。
五、前景与意义:超越数学的工具学习
ToRL 使大语言模型能够通过强化学习将工具整合到推理中,超越预定义的工具使用约束。研究结果显示了显著的性能提升和涌现的推理能力,展示了 ToRL 在复杂推理方面推进大语言模型发展的潜力。
这种直接从基座模型扩展的方法不仅在数学领域表现出色,还为需要精确计算、模拟或算法推理的其他领域开辟了新的可能性,如科学计算、经济建模和算法问题解决。
研究团队已开源实现代码、数据集和训练模型,使社区能够在 ToRL 的基础上进一步拓展工具增强语言模型的研究。
项目链接:https://github.com/GAIR-NLP/ToRL


